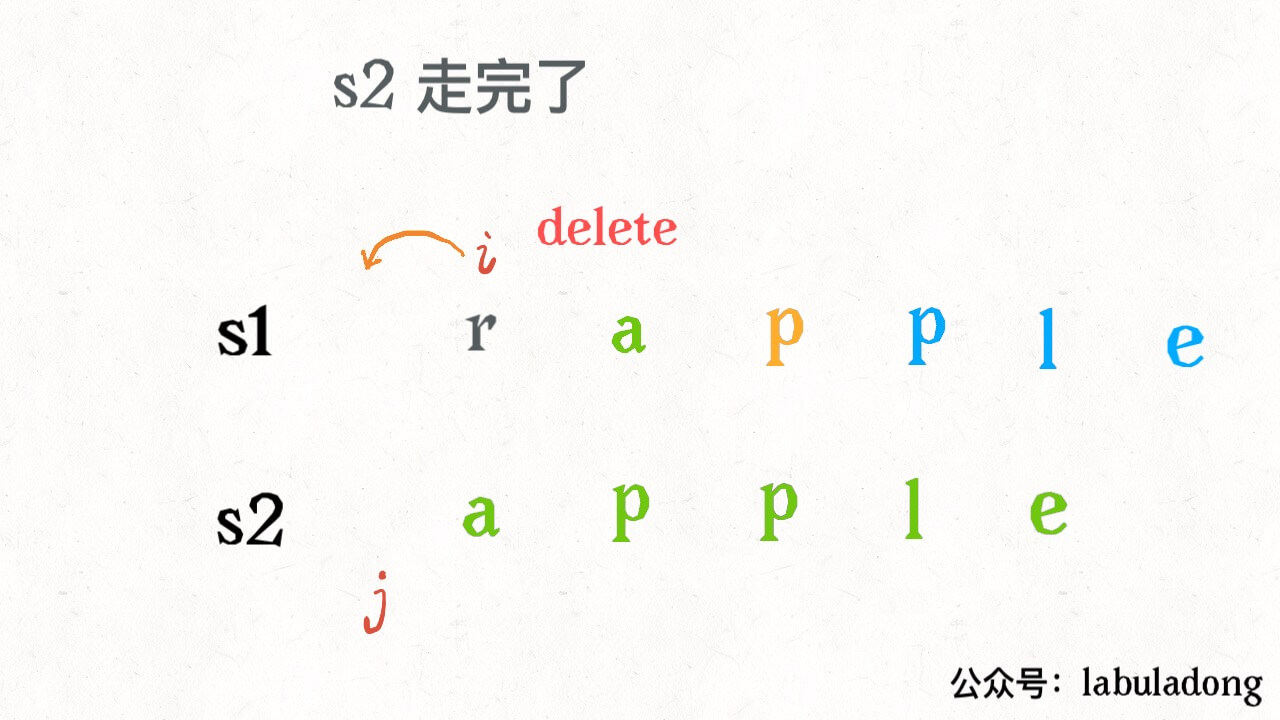
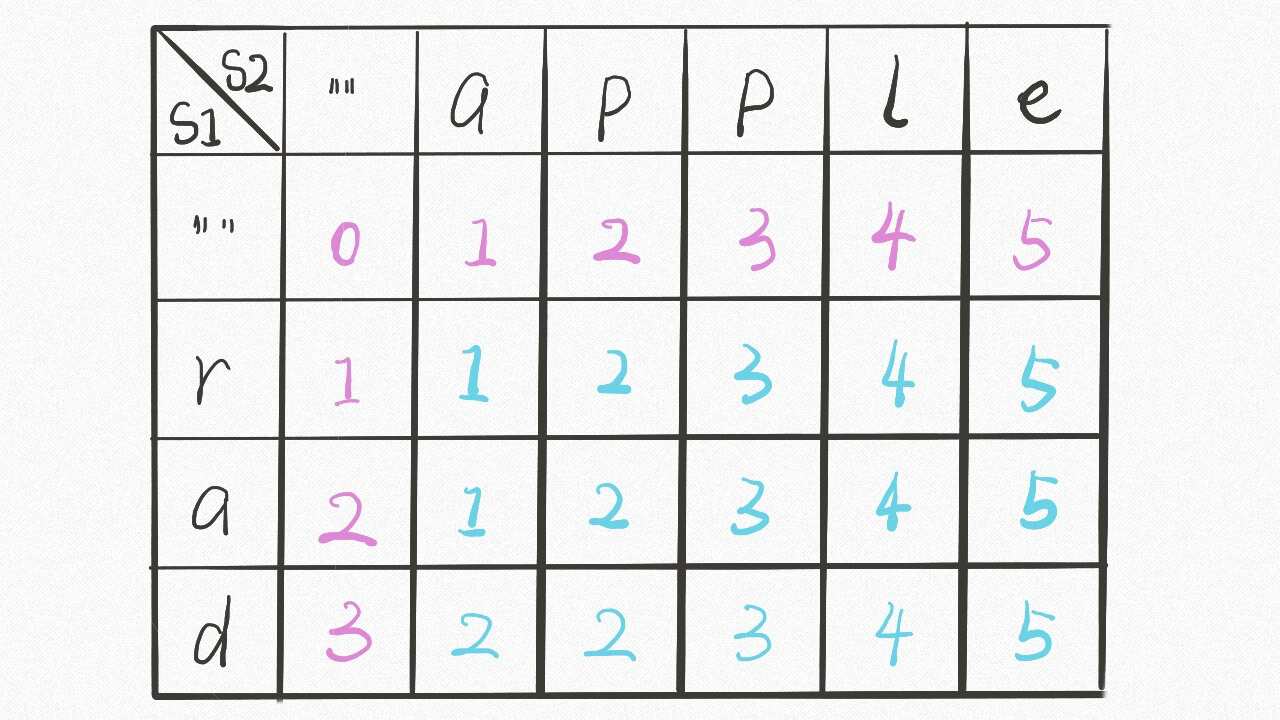
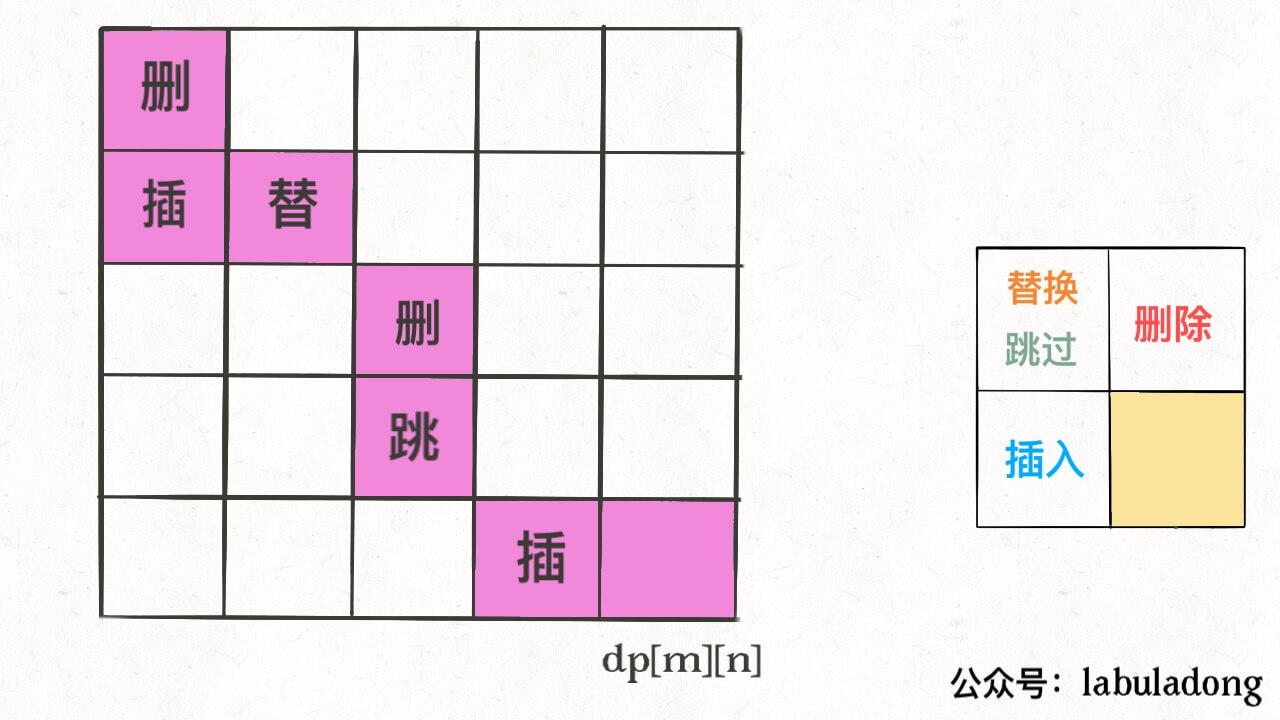
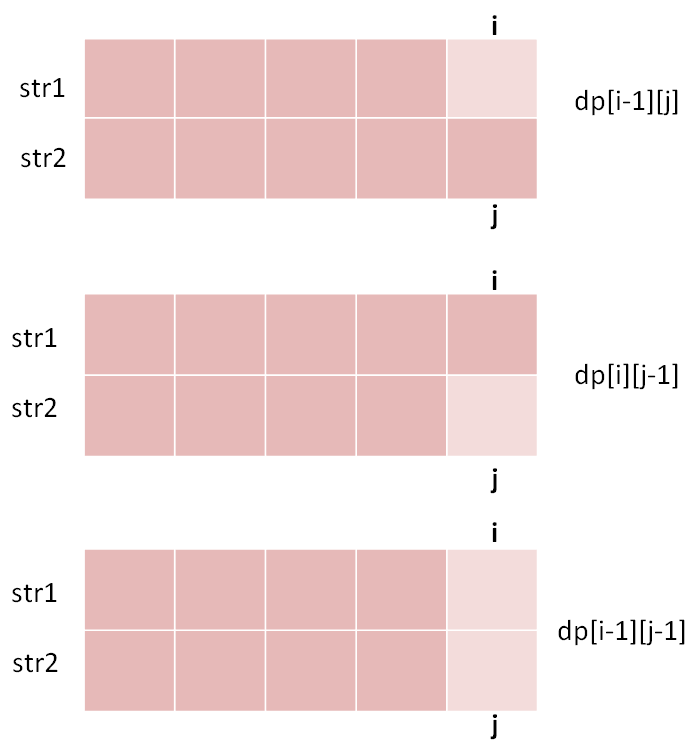int result = 0; for (Student a : school) { for (Student b : school) { if (a is b) continue; result = max(result, |a.score - b.score|); } } return result;
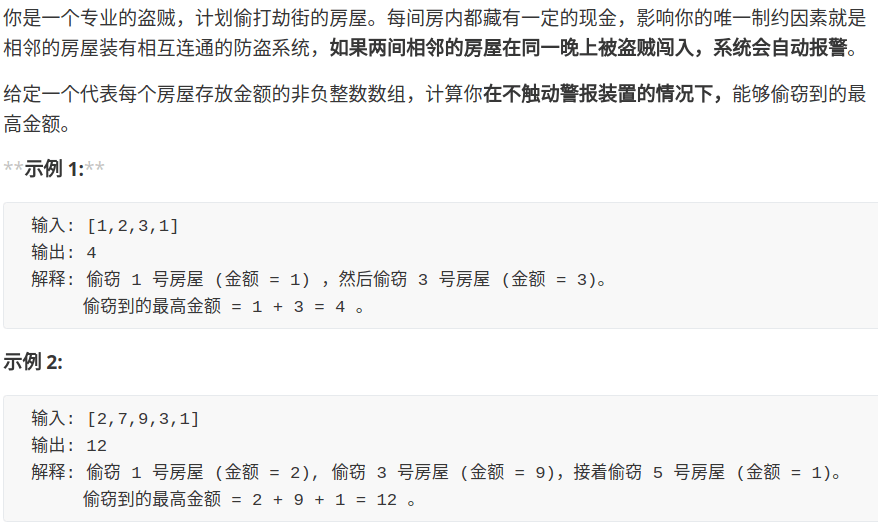
intmaxVal(TreeNode root){ if (root == null) return -1; int left = maxVal(root.left); int right = maxVal(root.right); return max(root.val, left, right); }
你看这个问题也符合最优子结构,以 root 为根的树的最大值,可以通过两边子树(子问题)的最大值推导出来,结合刚才学校和班级的例子,很容易理解吧。 当然这也不是动态规划问题,旨在说明,最优子结构并不是动态规划独有的一种性质,能求最值的问题大部分都具有这个性质;但反过来,最优子结构性质作为动态规划问题的必要条件,一定是让你求最值的,以后碰到那种恶心人的最值题,思路往动态规划想就对了,这就是套路。 动态规划不就是从最简单的 base case 往后推导吗,可以想象成一个链式反应,以小博大。但只有符合最优子结构的问题,才有发生这种链式反应的性质。 找最优子结构的过程,其实就是证明状态转移方程正确性的过程,方程符合最优子结构就可以写暴力解了,写出暴力解就可以看出有没有重叠子问题了,有则优化,无则 OK。这也是套路,经常刷题的朋友应该能体会。 这里就不举那些正宗动态规划的例子了,读者可以翻翻历史文章,看看状态转移是如何遵循最优子结构的,这个话题就聊到这,下面再来看另外个动态规划迷惑行为。
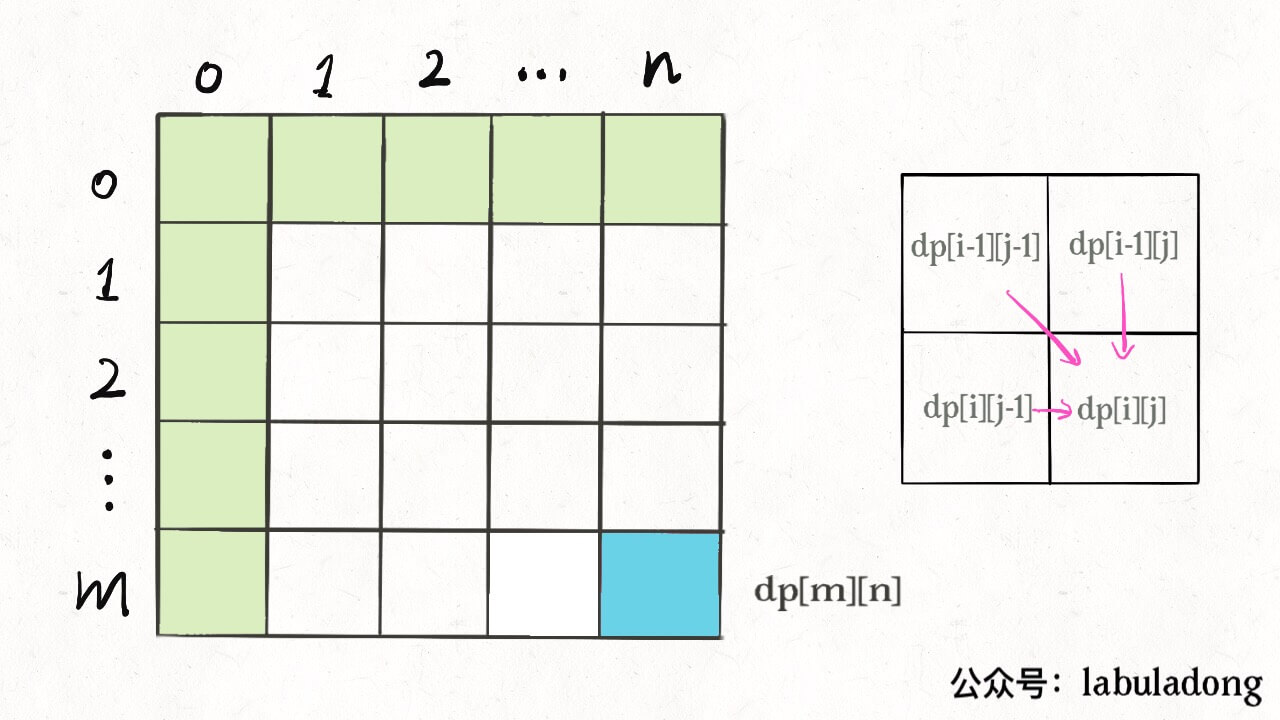
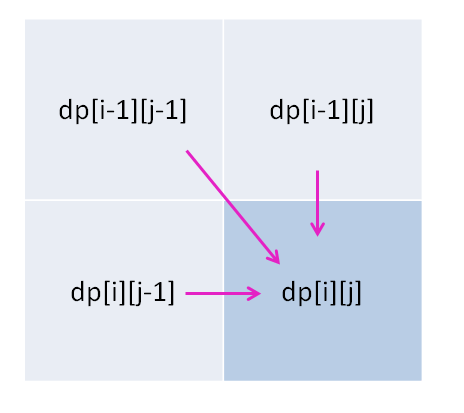
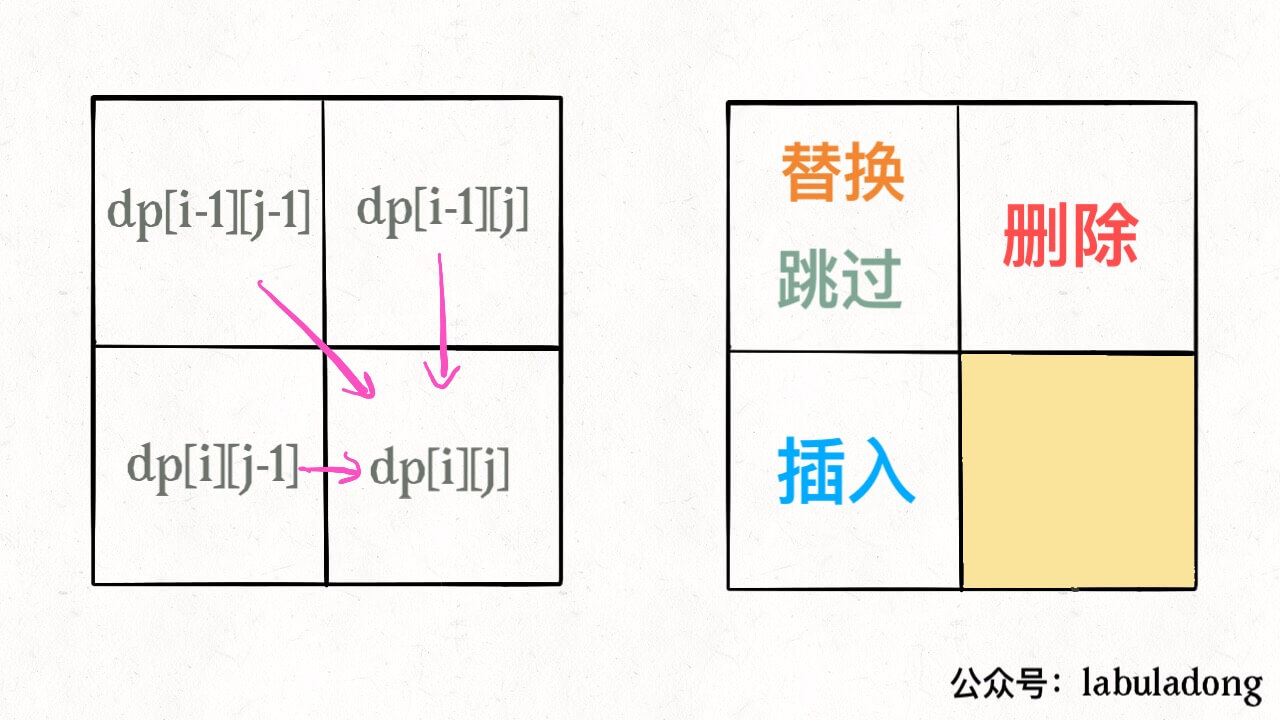
for (int i = 1; i < m; i++) for (int j = 1; j < n; j++) // 通过 dp[i-1][j], dp[i][j - 1], dp[i-1][j-1] // 计算 dp[i][j]
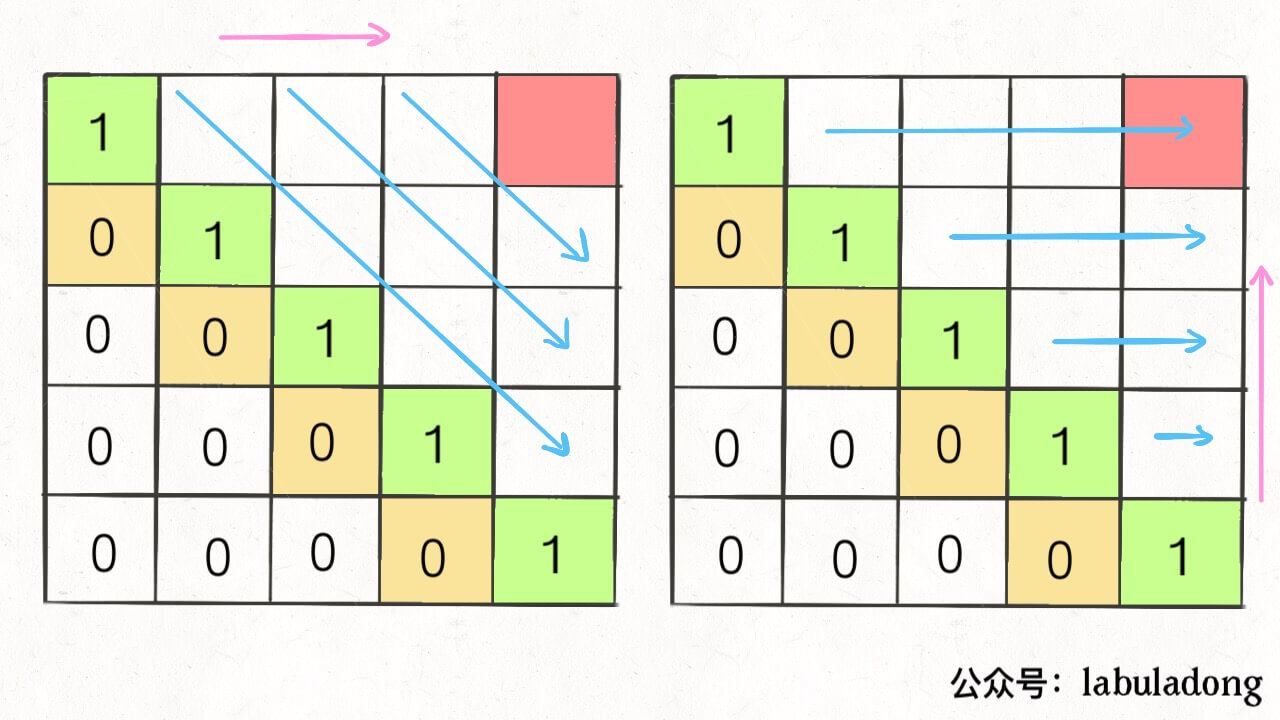
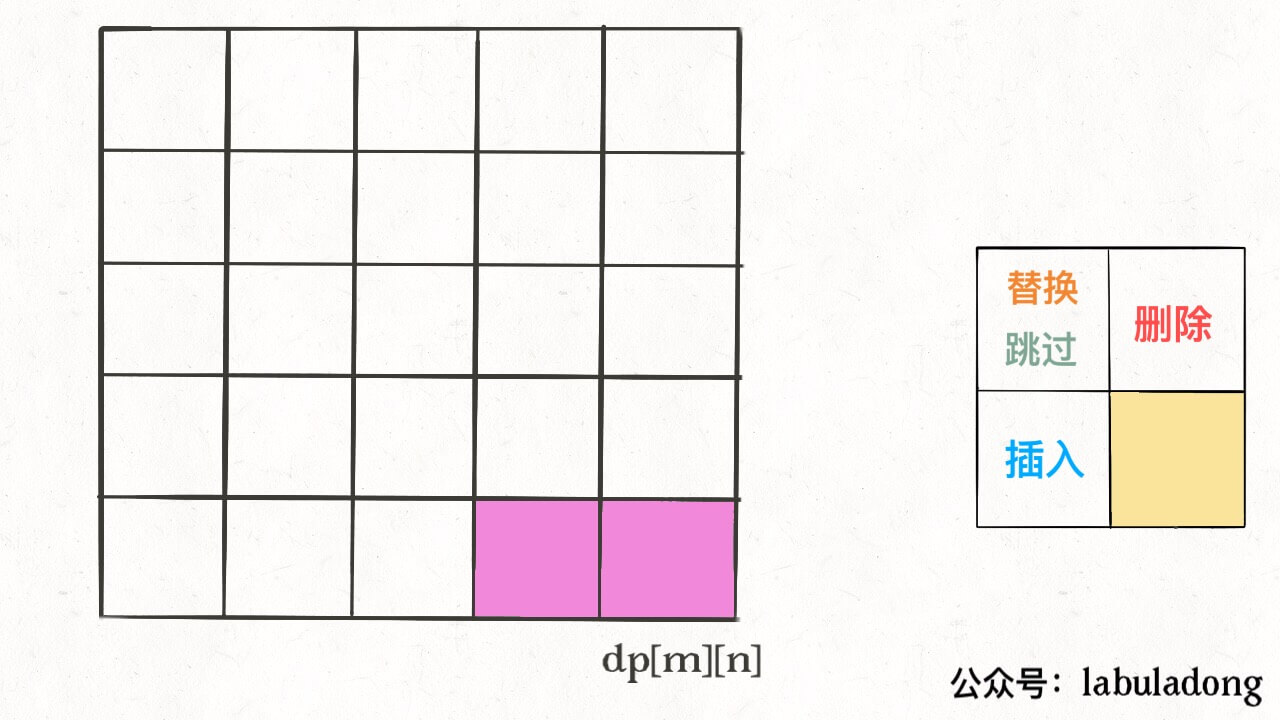
因为,这样每一步迭代的左边、上边、左上边的位置都是 base case 或者之前计算过的,而且最终结束在我们想要的答案 dp[m][n]。 再举一例,回文子序列问题,详见前文「子序列问题模板」,我们通过过对 dp 数组的定义,确定了 base case 处在中间的对角线,dp[i][j] 需要从 dp[i+1][j], dp[i][j-1], dp[i+1][j-1] 转移而来,想要求的最终答案是 dp[0][n-1],如下图: 这种情况根据刚才的两个原则,就可以有两种正确的遍历方式: 要么从左至右斜着遍历,要么从下向上从左到右遍历,这样才能保证每次 dp[i][j] 的左边、下边、左下边已经计算完毕,得到正确结果。 现在,你应该理解了这两个原则,主要就是看 base case 和最终结果的存储位置,保证遍历过程中使用的数据都是计算完毕的就行,有时候确实存在多种方法可以得到正确答案,可根据个人口味自行选择。
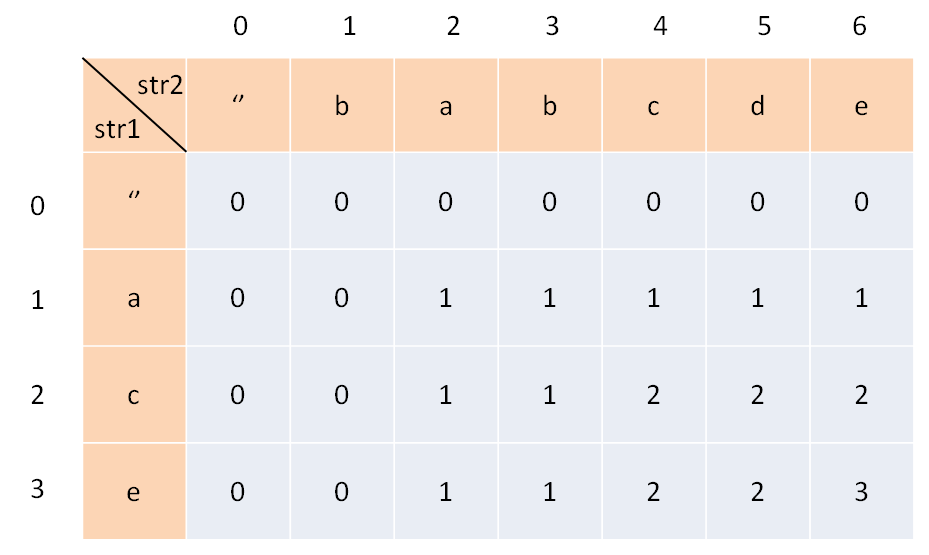
deflongestCommonSubsequence(str1, str2) -> int: m, n = len(str1), len(str2) # 构建 DP table 和 base case dp = [[0] * (n + 1) for _ in range(m + 1)] # 进行状态转移 for i in range(1, m + 1): for j in range(1, n + 1): if str1[i - 1] == str2[j - 1]: # 找到一个 lcs 中的字符 dp[i][j] = 1 + dp[i-1][j-1] else: dp[i][j] = max(dp[i-1][j], dp[i][j-1])
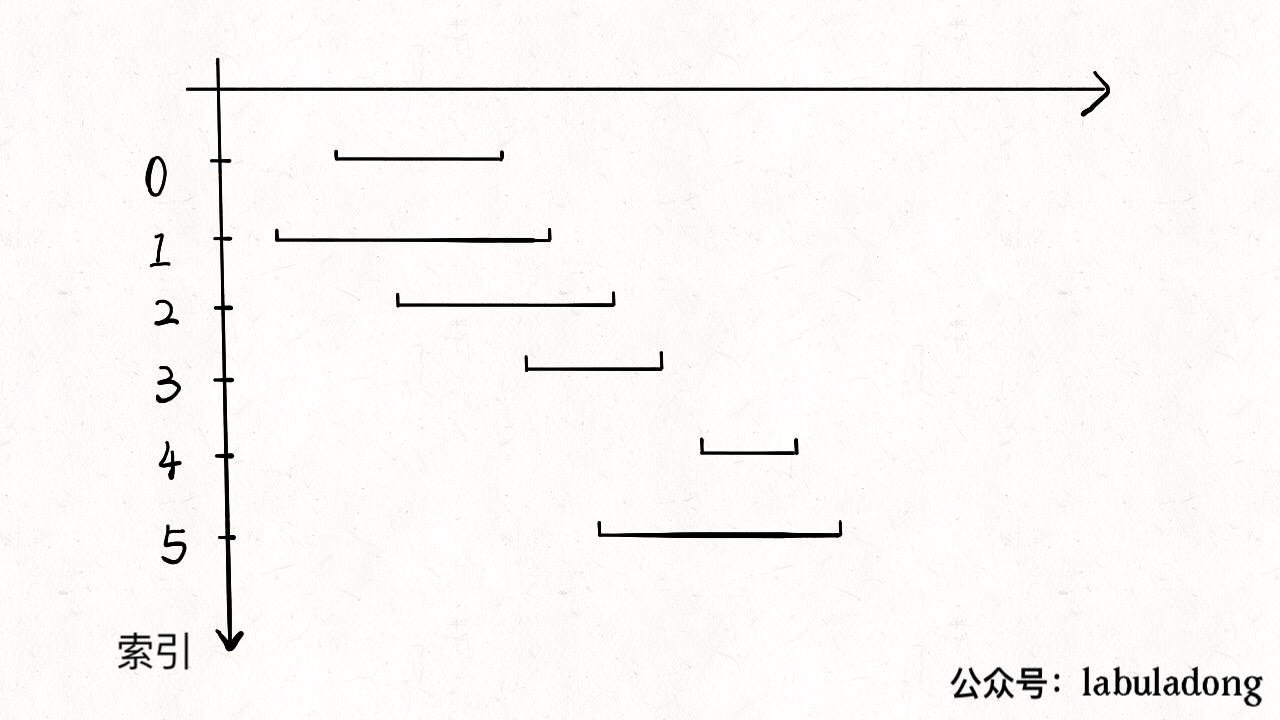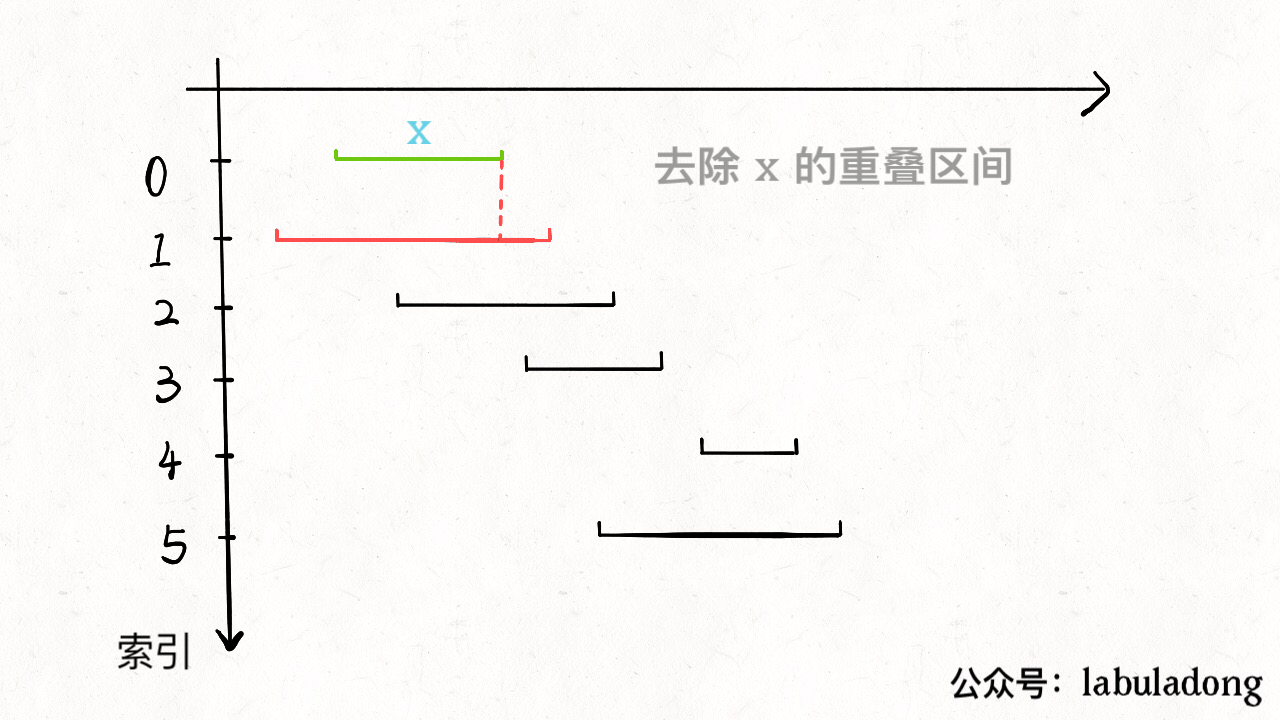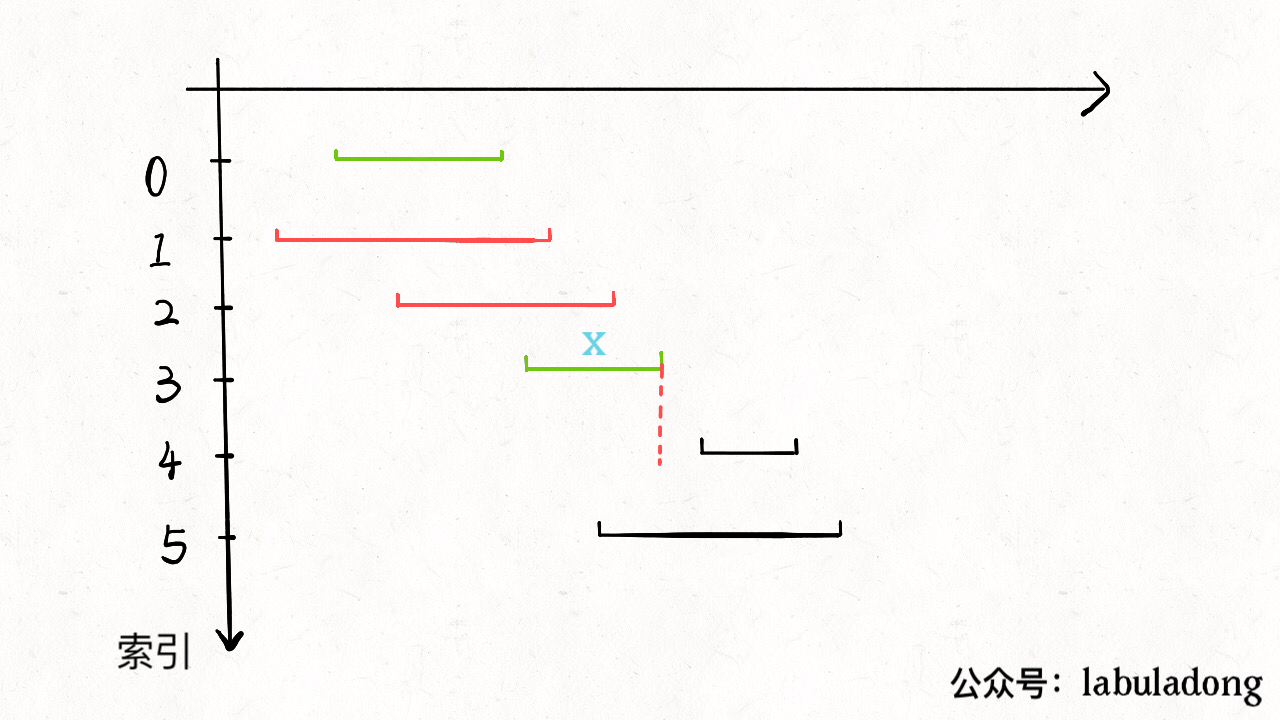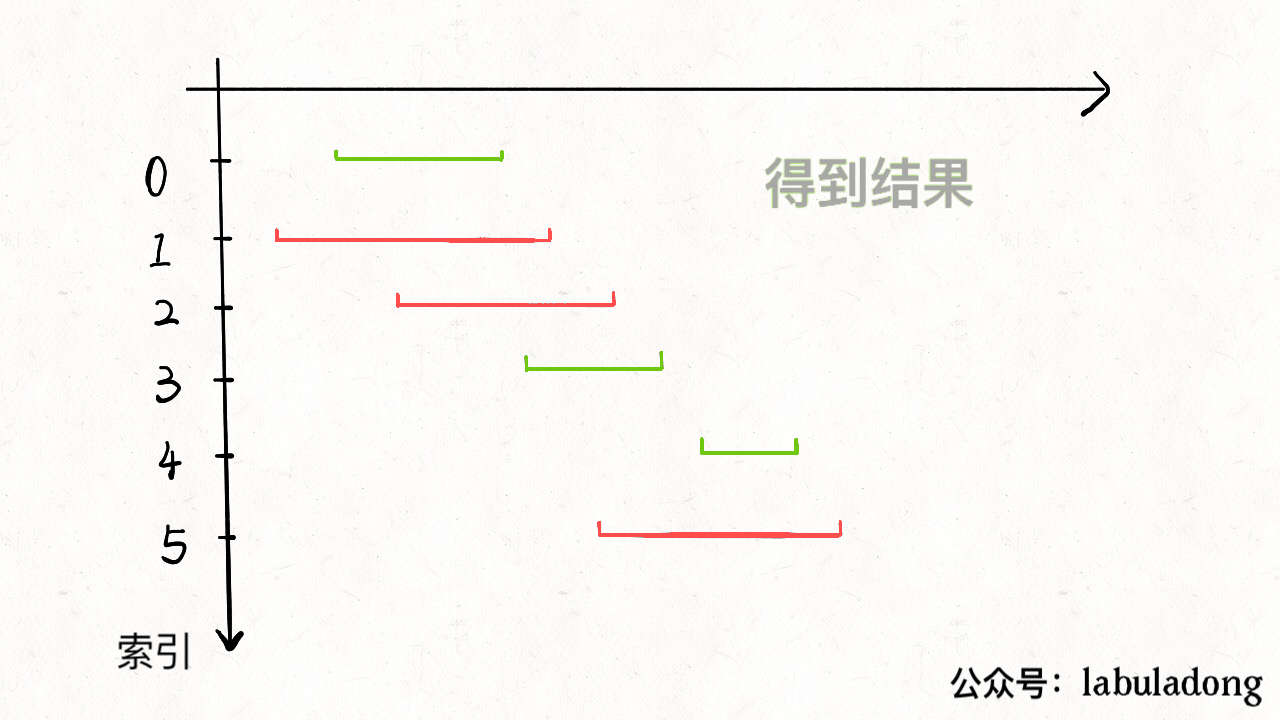
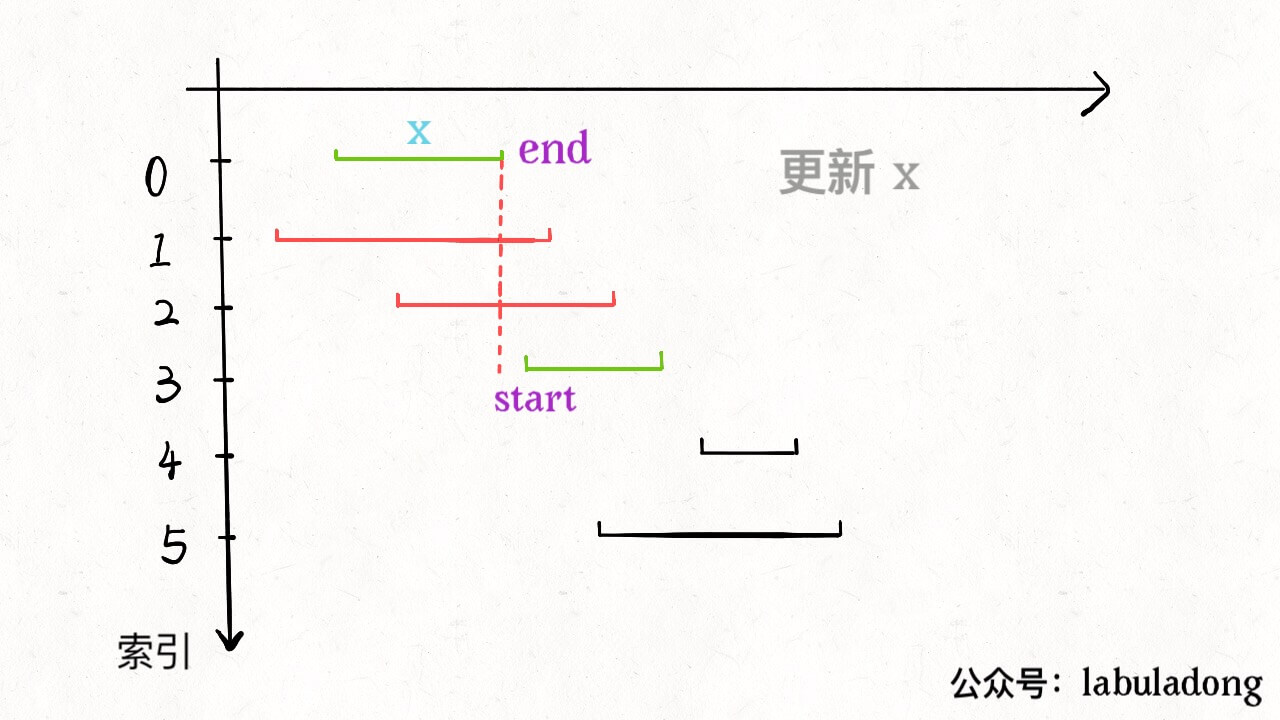
从区间集合 intvs 中选择一个区间 x,这个 x 是在当前所有区间中结束最早的(end 最小)。
把所有与 x 区间相交的区间从区间集合 intvs 中删除。
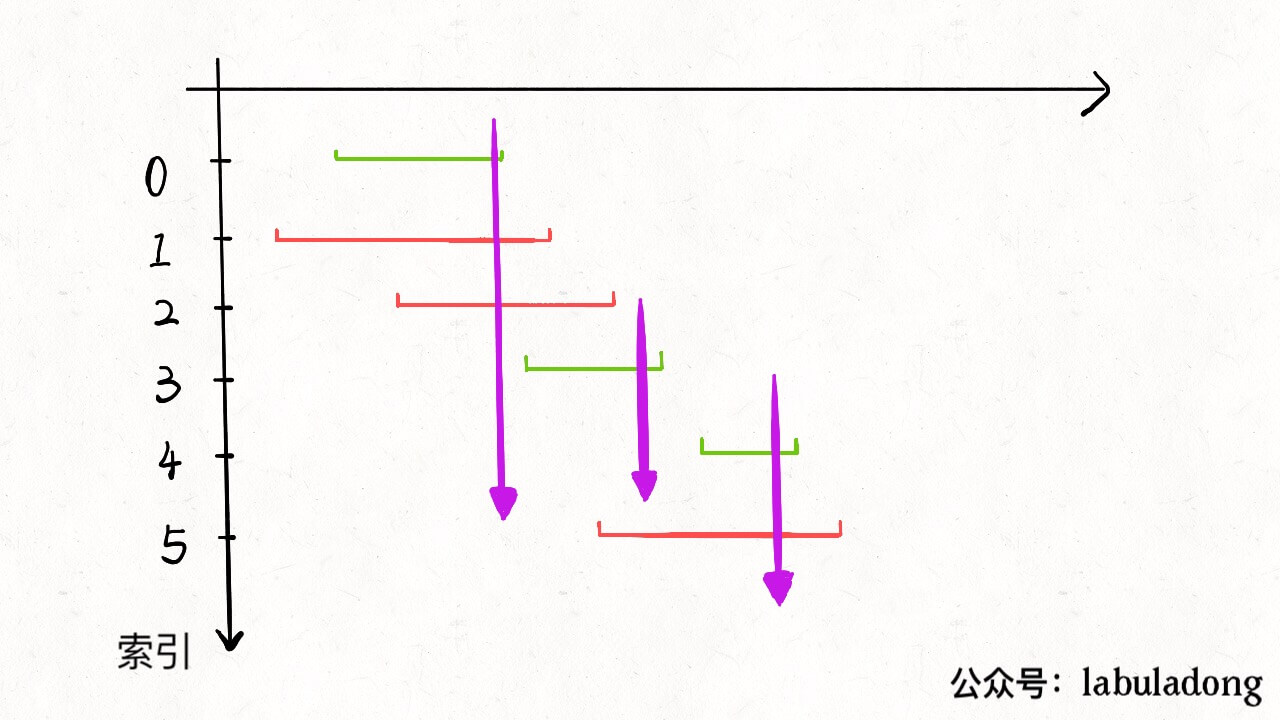
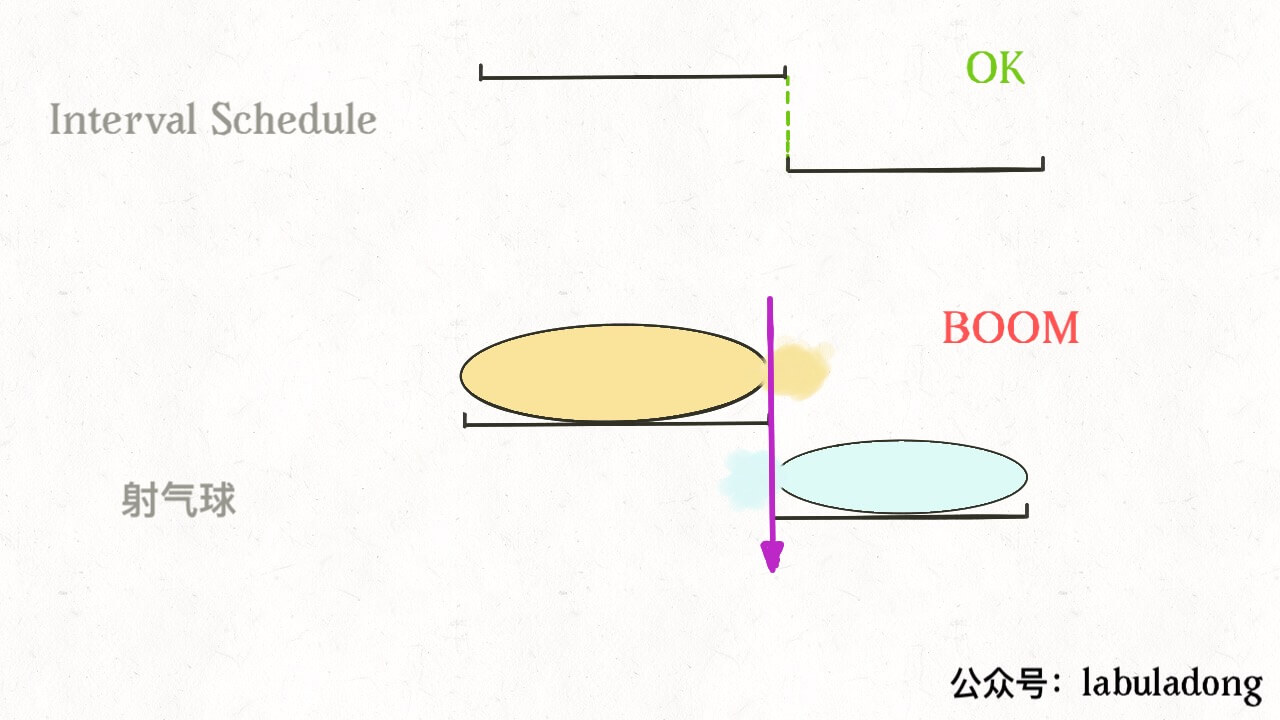
重复步骤 1 和 2,直到 intvs 为空为止。之前选出的那些 x 就是最大不相交子集。 把这个思路实现成算法的话,可以按每个区间的 end 数值升序排序,因为这样处理之后实现步骤 1 和步骤 2 都方便很多: 现在来实现算法,对于步骤 1,由于我们预先按照 end 排了序,所以选择 x 是很容易的。关键在于,如何去除与 x 相交的区间,选择下一轮循环的 x 呢?
由于我们事先排了序,不难发现所有与 x 相交的区间必然会与 x 的 end 相交;如果一个区间不想与 x 的 end 相交,它的 start 必须要大于(或等于)x 的 end: 看下代码:
之前提到过这个解法,核心是因为状态转移方程的单调性,这里可以具体展开看看。 首先简述一下原始动态规划的思路: 1、暴力穷举尝试在所有楼层 1 <= i <= N 扔鸡蛋,每次选择尝试次数最少的那一层; 2、每次扔鸡蛋有两种可能,要么碎,要么没碎; 3、如果鸡蛋碎了,F 应该在第 i 层下面,否则,F 应该在第 i 层上面; 4、鸡蛋是碎了还是没碎,取决于哪种情况下尝试次数更多,因为我们想求的是最坏情况下的结果。 核心的状态转移代码是这段:
1 2 3 4 5 6 7 8 9 10 11 12
# 当前状态为 K 个鸡蛋,面对 N 层楼 # 返回这个状态下的最优结果 defdp(K, N): for1 <= i <= N: # 最坏情况下的最少扔鸡蛋次数 res = min(res, max( dp(K - 1, i - 1), # 碎 dp(K, N - i) # 没碎 ) + 1# 在第 i 楼扔了一次 ) return res
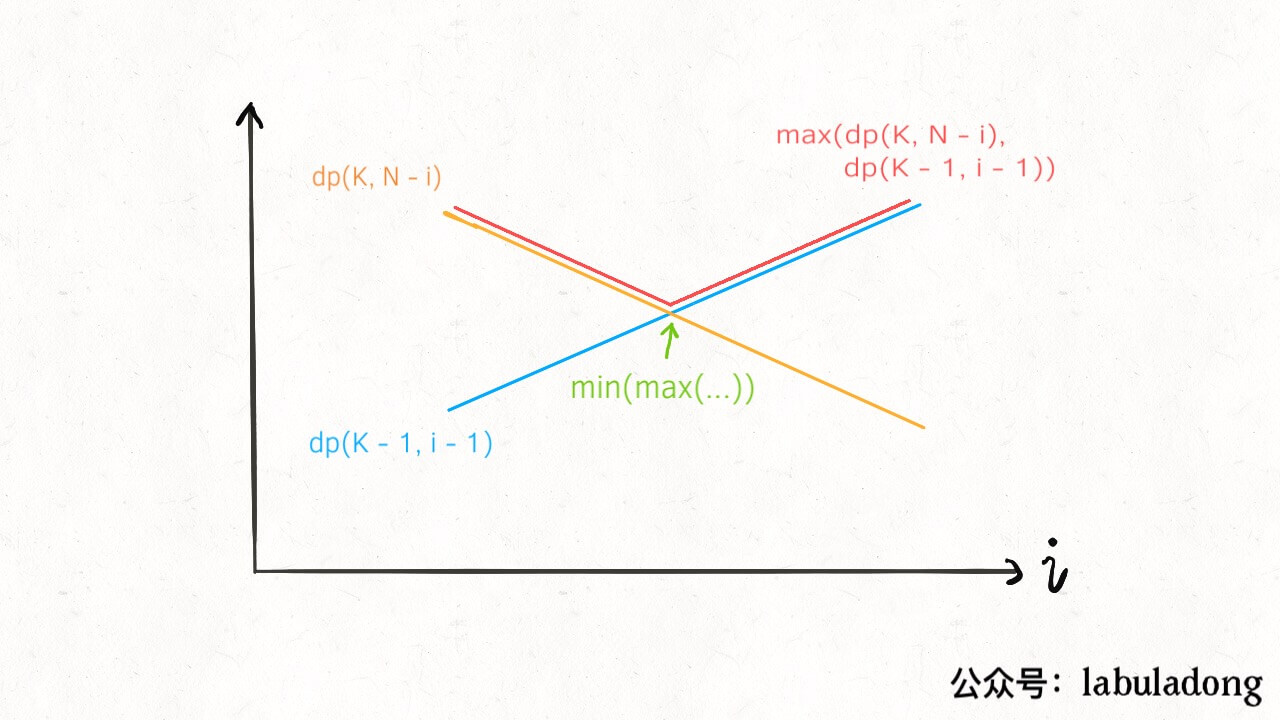
这个 for 循环就是下面这个状态转移方程的具体代码实现: $$ dp(K, N) = \min_{0 <= i <= N}{\max{dp(K - 1, i - 1), dp(K, N - i)} + 1}$$ 如果能够理解这个状态转移方程,那么就很容易理解二分查找的优化思路。 首先我们根据 dp(K, N) 数组的定义(有 K 个鸡蛋面对 N 层楼,最少需要扔几次),很容易知道 K 固定时,这个函数随着 N 的增加一定是单调递增的,无论你策略多聪明,楼层增加测试次数一定要增加。 那么注意 dp(K - 1, i - 1) 和 dp(K, N - i) 这两个函数,其中 i 是从 1 到 N 单增的,如果我们固定 K 和 N,把这两个函数看做关于 i 的函数,前者随着 i 的增加应该也是单调递增的,而后者随着 i 的增加应该是单调递减的: 这时候求二者的较大值,再求这些最大值之中的最小值,其实就是求这两条直线交点,也就是红色折线的最低点嘛。 我们前文「二分查找只能用来查找元素吗」讲过,二分查找的运用很广泛,形如下面这种形式的 for 循环代码:
1 2 3 4
for (int i = 0; i < n; i++) { if (isOK(i)) return i; }
defdp(k, n) -> int # 当前状态为 k 个鸡蛋,面对 n 层楼 # 返回这个状态下最少的扔鸡蛋次数
用 dp 数组表示的话也是一样的:
1 2 3
dp[k][n] = m # 当前状态为 k 个鸡蛋,面对 n 层楼 # 这个状态下最少的扔鸡蛋次数为 m
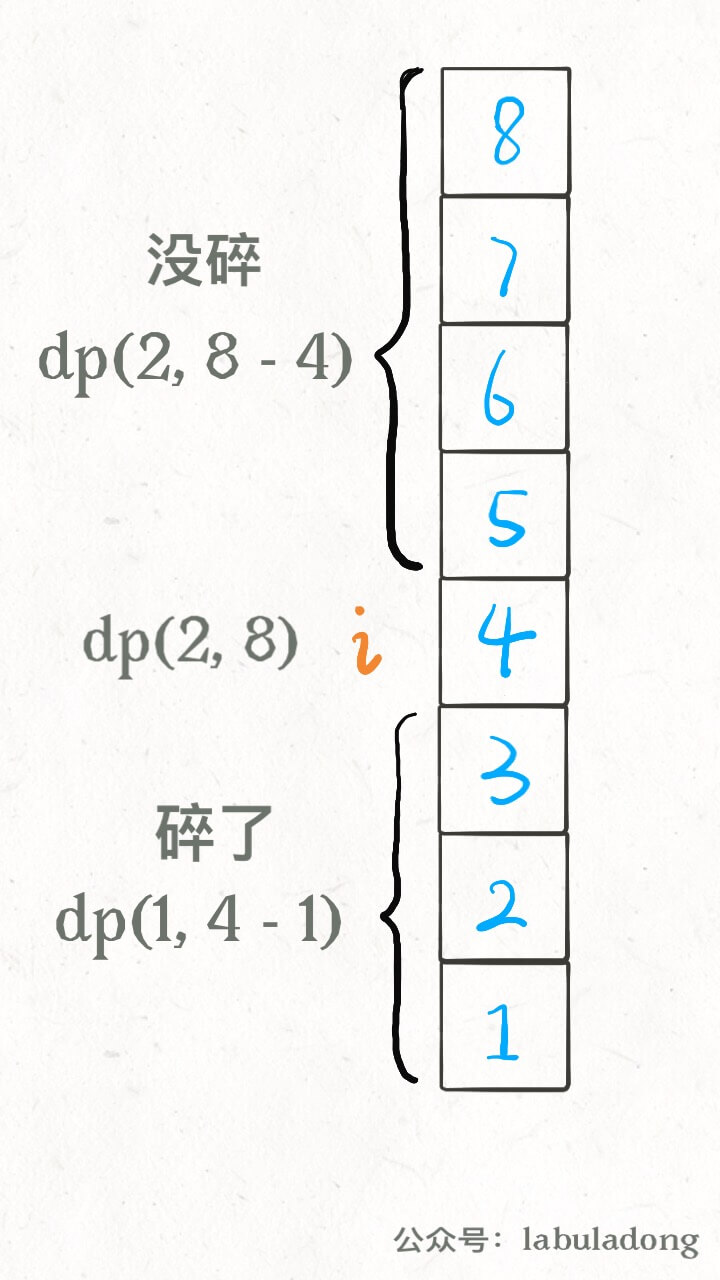
按照这个定义,就是确定当前的鸡蛋个数和面对的楼层数,就知道最小扔鸡蛋次数。最终我们想要的答案就是 dp(K, N) 的结果。 这种思路下,肯定要穷举所有可能的扔法的,用二分搜索优化也只是做了「剪枝」,减小了搜索空间,但本质思路没有变,还是穷举。 现在,我们稍微修改 dp 数组的定义,确定当前的鸡蛋个数和最多允许的扔鸡蛋次数,就知道能够确定 F 的最高楼层数。具体来说是这个意思:
1 2 3 4 5 6 7 8
dp[k][m] = n # 当前有 k 个鸡蛋,可以尝试扔 m 次鸡蛋 # 这个状态下,最坏情况下最多能确切测试一栋 n 层的楼 # 比如说 dp[1][7] = 7 表示: # 现在有 1 个鸡蛋,允许你扔 7 次; # 这个状态下最多给你 7 层楼, # 使得你可以确定楼层 F 使得鸡蛋恰好摔不碎 # (一层一层线性探查嘛)
这其实就是我们原始思路的一个「反向」版本,我们先不管这种思路的状态转移怎么写,先来思考一下这种定义之下,最终想求的答案是什么? 我们最终要求的其实是扔鸡蛋次数 m,但是这时候 m 在状态之中而不是 dp 数组的结果,可以这样处理:
1 2 3 4 5 6 7 8
intsuperEggDrop(int K, int N){ int m = 0; while (dp[K][m] < N) { m++; // 状态转移... } return m; }
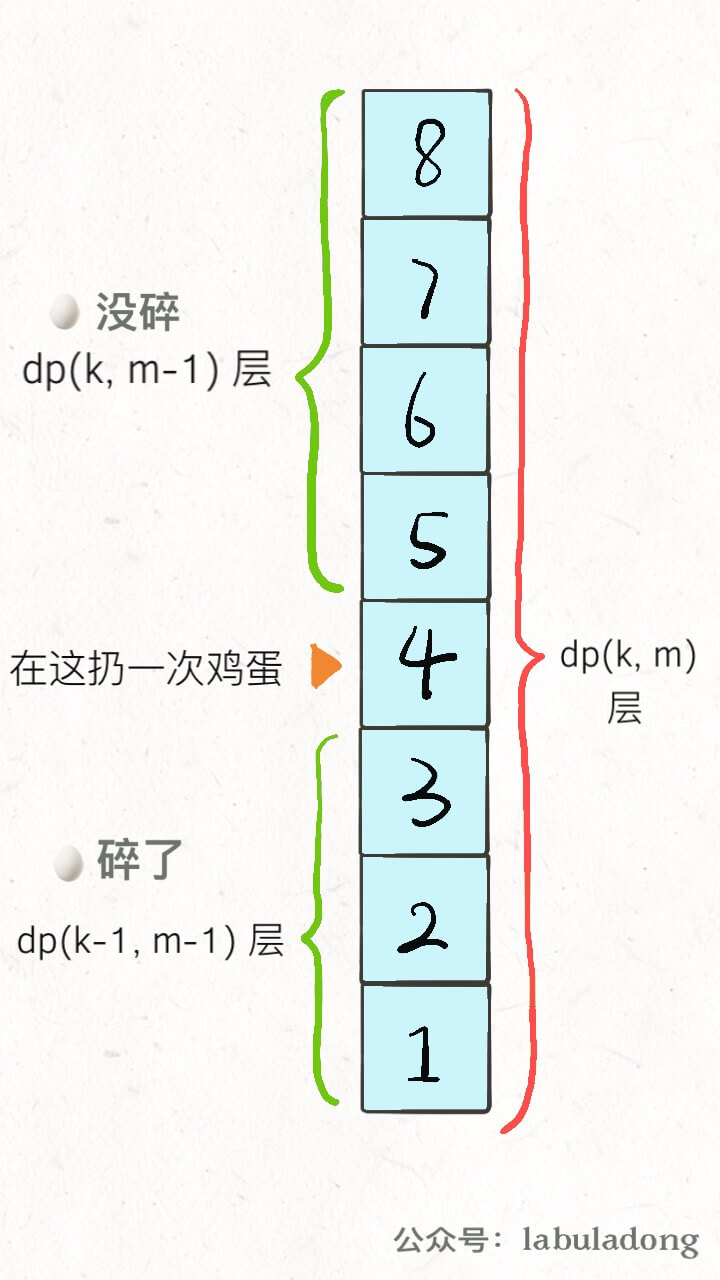
题目不是给你 K 鸡蛋,N 层楼,让你求最坏情况下最少的测试次数 m 吗?while 循环结束的条件是 dp[K][m] == N,也就是给你 K 个鸡蛋,测试 m 次,最坏情况下最多能测试 N 层楼。 注意看这两段描述,是完全一样的!所以说这样组织代码是正确的,关键就是状态转移方程怎么找呢?还得从我们原始的思路开始讲。之前的解法配了这样图帮助大家理解状态转移思路: 这个图描述的仅仅是某一个楼层 i,原始解法还得线性或者二分扫描所有楼层,要求最大值、最小值。但是现在这种 dp 定义根本不需要这些了,基于下面两个事实: 1、无论你在哪层楼扔鸡蛋,鸡蛋只可能摔碎或者没摔碎,碎了的话就测楼下,没碎的话就测楼上。 2、无论你上楼还是下楼,总的楼层数 = 楼上的楼层数 + 楼下的楼层数 + 1(当前这层楼)。 根据这个特点,可以写出下面的状态转移方程: dp[k][m] = dp[k][m - 1] + dp[k - 1][m - 1] + 1 **dp[k][m - 1] 就是楼上的楼层数,因为鸡蛋个数 k 不变,也就是鸡蛋没碎,扔鸡蛋次数 m 减一; **dp[k - 1][m - 1] 就是楼下的楼层数,因为鸡蛋个数 k 减一,也就是鸡蛋碎了,同时扔鸡蛋次数 m 减一。 PS:这个 m 为什么要减一而不是加一?之前定义得很清楚,这个 m 是一个允许的次数上界,而不是扔了几次。 至此,整个思路就完成了,只要把状态转移方程填进框架即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
intsuperEggDrop(int K, int N){ // m 最多不会超过 N 次(线性扫描) int[][] dp = newint[K + 1][N + 1]; // base case: // dp[0][..] = 0 // dp[..][0] = 0 // Java 默认初始化数组都为 0 int m = 0; while (dp[K][m] < N) { m++; for (int k = 1; k <= K; k++) dp[k][m] = dp[k][m - 1] + dp[k - 1][m - 1] + 1; } return m; }
如果你还觉得这段代码有点难以理解,其实它就等同于这样写:
1 2 3
for (int m = 1; dp[K][m] < N; m++) for (int k = 1; k <= K; k++) dp[k][m] = dp[k][m - 1] + dp[k - 1][m - 1] + 1;
看到这种代码形式就熟悉多了吧,因为我们要求的不是 dp 数组里的值,而是某个符合条件的索引 m,所以用 while 循环来找到这个 m 而已。 这个算法的时间复杂度是多少?很明显就是两个嵌套循环的复杂度 O(KN)。 另外注意到 dp[m][k] 转移只和左边和左上的两个状态有关,所以很容易优化成一维 dp 数组,这里就不写了。
还可以再优化
再往下就要用一些数学方法了,不具体展开,就简单提一下思路吧。 在刚才的思路之上,注意函数 dp(m, k) 是随着 m 单增的,因为鸡蛋个数 k 不变时,允许的测试次数越多,可测试的楼层就越高。 这里又可以借助二分搜索算法快速逼近 dp[K][m] == N 这个终止条件,时间复杂度进一步下降为 O(KlogN),我们可以设 g(k, m) =…… 算了算了,打住吧。我觉得我们能够写出 O(K*N*logN) 的二分优化算法就行了,后面的这些解法呢,听个响鼓个掌就行了,把欲望限制在能力的范围之内才能拥有快乐! 不过可以肯定的是,根据二分搜索代替线性扫描 m 的取值,代码的大致框架肯定是修改穷举 m 的 for 循环:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
// 把线性搜索改成二分搜索 // for (int m = 1; dp[K][m] < N; m++) int lo = 1, hi = N; while (lo < hi) { int mid = (lo + hi) / 2; if (... < N) { lo = ... } else { hi = ... }
defsuperEggDrop(K: int, N: int): memo = dict() defdp(K, N) -> int: # base case if K == 1: return N if N == 0: return0 # 避免重复计算 if (K, N) in memo: return memo[(K, N)] res = float('INF') # 穷举所有可能的选择 for i in range(1, N + 1): res = min(res, max( dp(K, N - i), dp(K - 1, i - 1) ) + 1 ) # 记入备忘录 memo[(K, N)] = res return res
defdp(K, N): for1 <= i <= N: # 最坏情况下的最少扔鸡蛋次数 res = min(res, max( dp(K - 1, i - 1), # 碎 dp(K, N - i) # 没碎 ) + 1# 在第 i 楼扔了一次 ) return res
这个 for 循环就是下面这个状态转移方程的具体代码实现:
$ dp(K, N) = \min_{0 <= i <= N}{\max{dp(K - 1, i - 1), dp(K, N - i)} + 1} $
首先我们根据 dp(K, N) 数组的定义(有 K 个鸡蛋面对 N 层楼,最少需要扔几次),很容易知道 K 固定时,这个函数一定是单调递增的,无论你策略多聪明,楼层增加测试次数一定要增加。 那么注意 dp(K - 1, i - 1) 和 dp(K, N - i) 这两个函数,其中 i 是从 1 到 N 单增的,如果我们固定 K 和 N,把这两个函数看做关于 i 的函数,前者随着 i 的增加应该也是单调递增的,而后者随着 i 的增加应该是单调递减的: 这时候求二者的较大值,再求这些最大值之中的最小值,其实就是求这个交点嘛,熟悉二分搜索的同学肯定敏感地想到了,这不就是相当于求 Valley(山谷)值嘛,可以用二分查找来快速寻找这个点的。 直接贴一下代码吧,思路还是完全一样的:
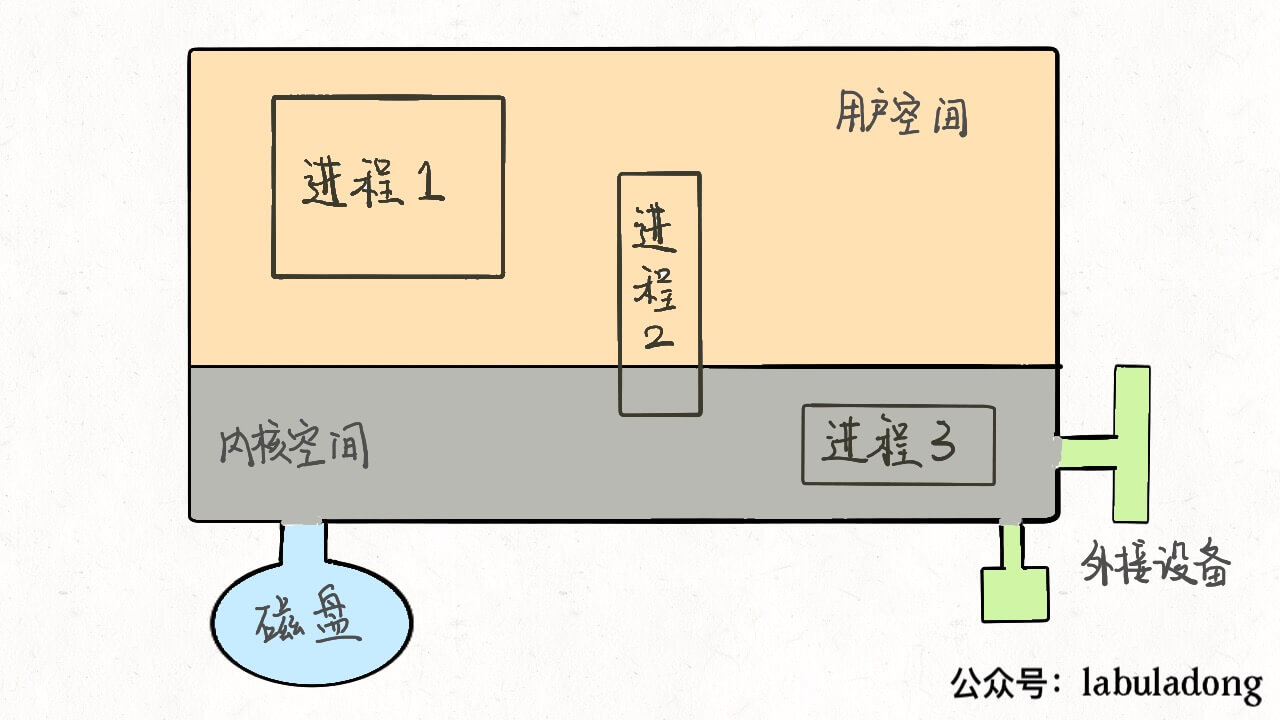
我个人很喜欢使用 Linux 系统,虽然说 Windows 的图形化界面做的确实比 Linux 好,但是对脚本的支持太差了。一开始有点不习惯命令行操作,但是熟悉了之后反而发现移动鼠标点点点才是浪费时间的罪魁祸首。。。 那么对于 Linux 命令行,本文不是介绍某些命令的用法,而是说明一些简单却特别容易让人迷惑的细节问题。 1、标准输入和命令参数的区别。 2、在后台运行命令在退出终端后也全部退出了。 3、单引号和双引号表示字符串的区别。 4、有的命令和sudo一起用就 command not found。
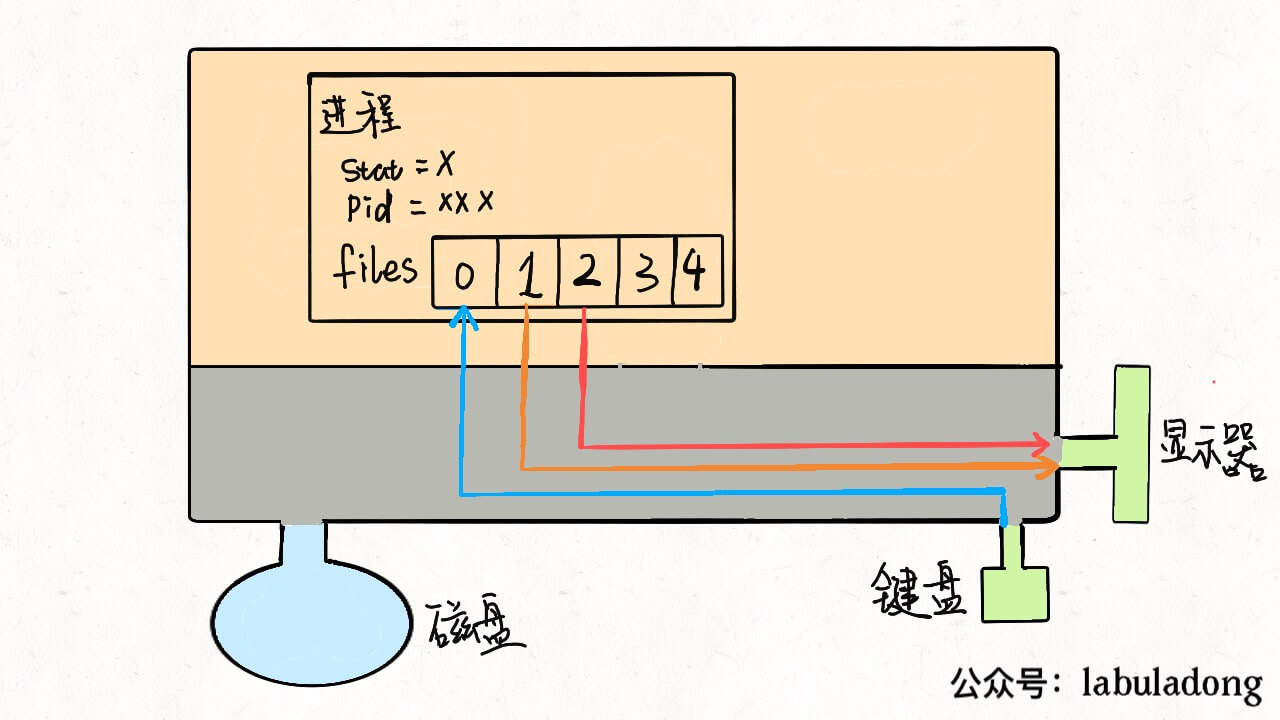
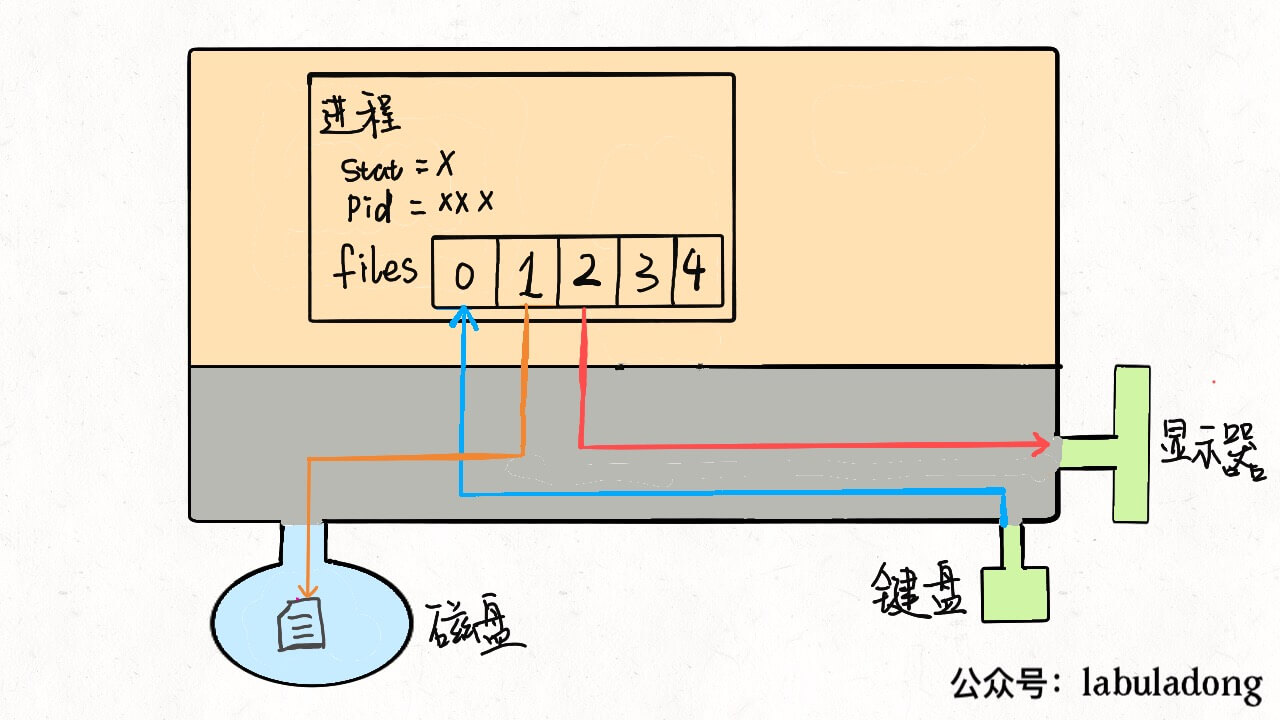
task_struct就是 Linux 内核对于一个进程的描述,也可以称为「进程描述符」。源码比较复杂,我这里就截取了一小部分比较常见的。 其中比较有意思的是mm指针和files指针。mm指向的是进程的虚拟内存,也就是载入资源和可执行文件的地方;files指针指向一个数组,这个数组里装着所有该进程打开的文件的指针。
二、文件描述符是什么
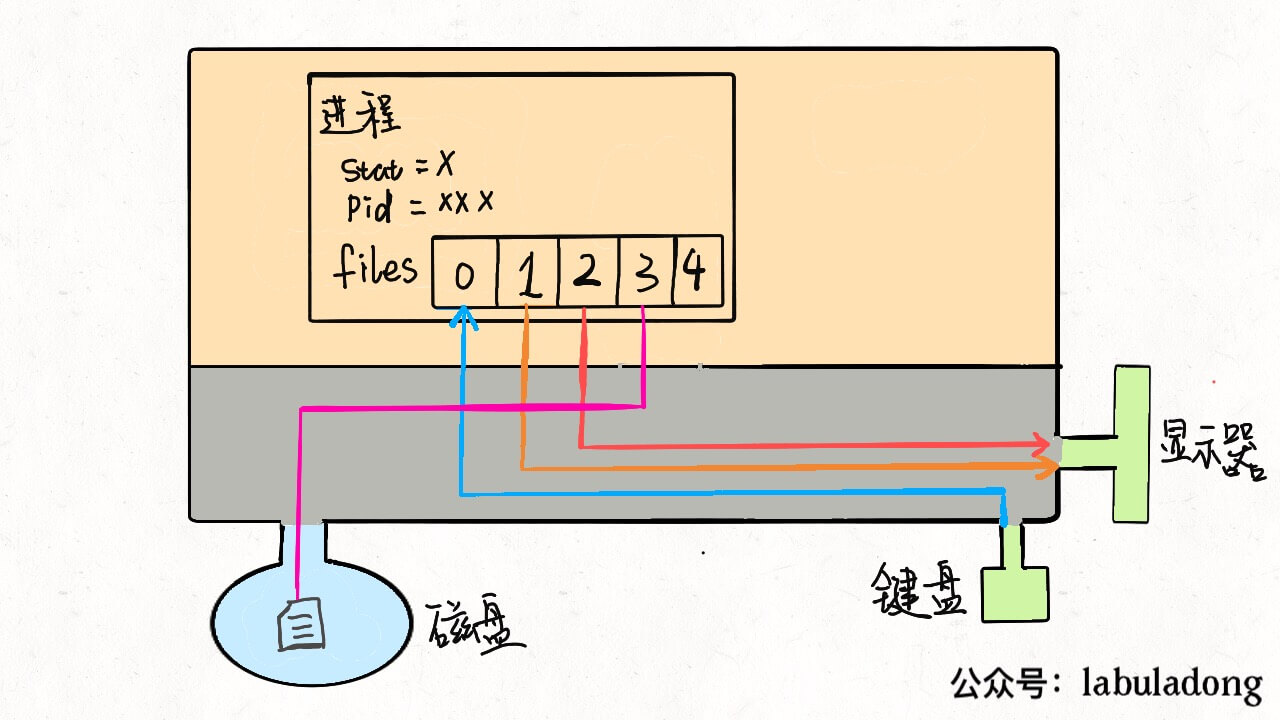
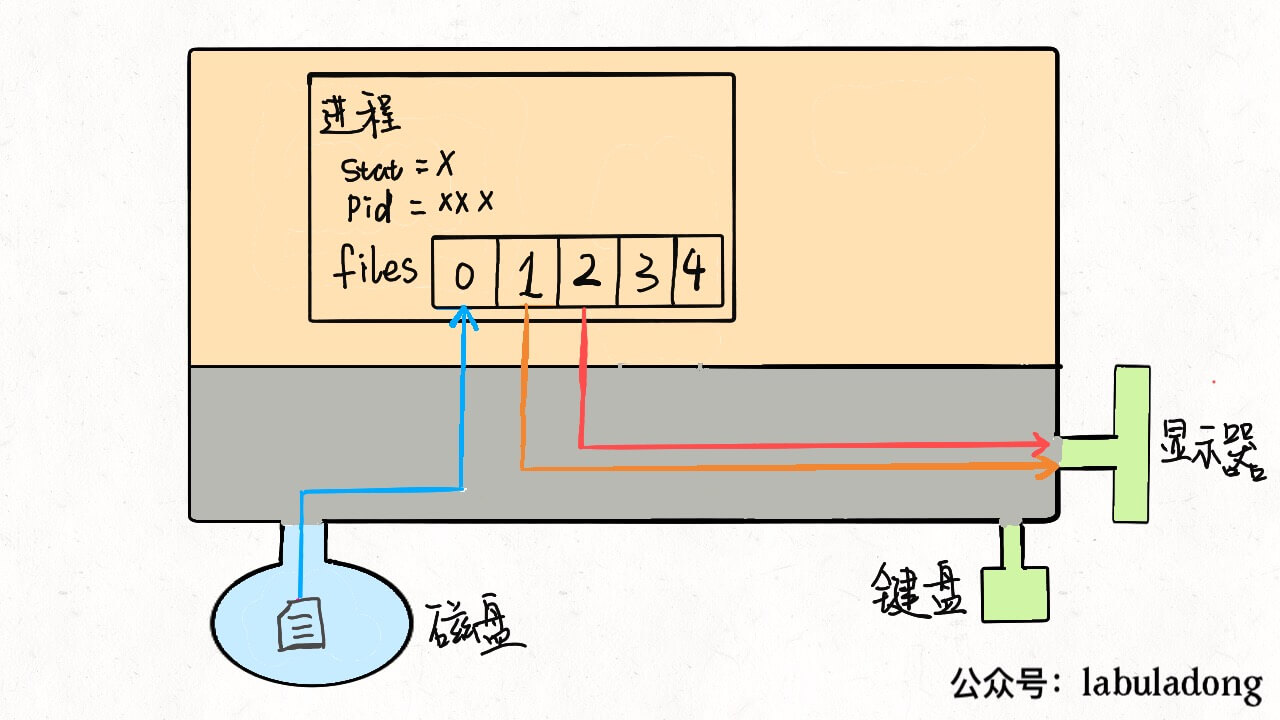
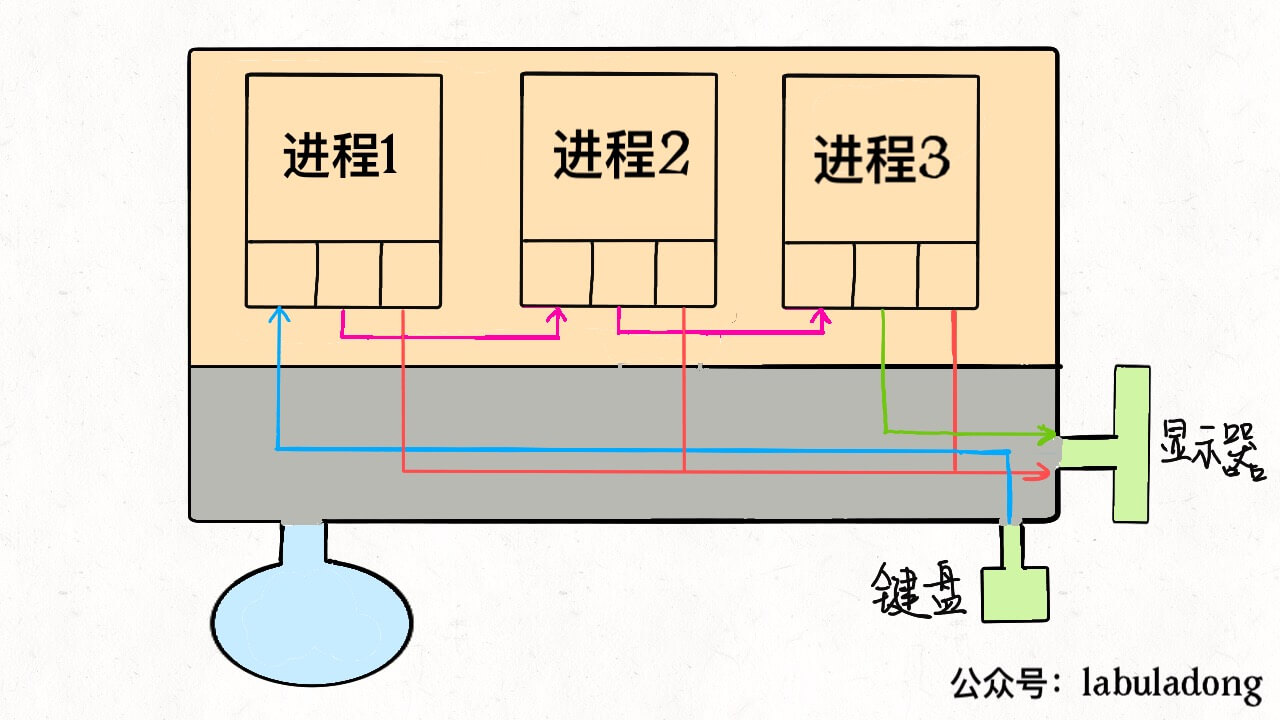
先说files,它是一个文件指针数组。一般来说,一个进程会从files[0]读取输入,将输出写入files[1],将错误信息写入files[2]。 举个例子,以我们的角度 C 语言的printf函数是向命令行打印字符,但是从进程的角度来看,就是向files[1]写入数据;同理,scanf函数就是进程试图从files[0]这个文件中读取数据。 每个进程被创建时,files的前三位被填入默认值,分别指向标准输入流、标准输出流、标准错误流。我们常说的「文件描述符」就是指这个文件指针数组的索引,所以程序的文件描述符默认情况下 0 是输入,1 是输出,2 是错误。
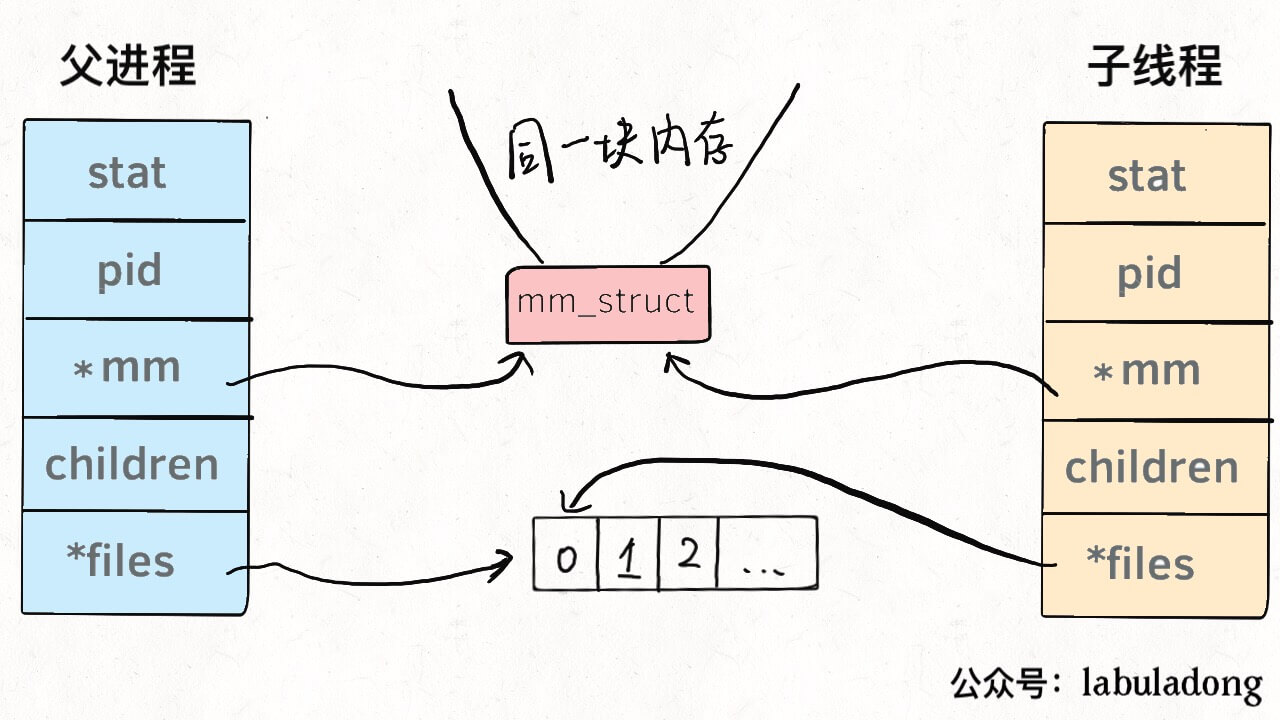
首先要明确的是,多进程和多线程都是并发,都可以提高处理器的利用效率,所以现在的关键是,多线程和多进程有啥区别。 为什么说 Linux 中线程和进程基本没有区别呢,因为从 Linux 内核的角度来看,并没有把线程和进程区别对待。 我们知道系统调用fork()可以新建一个子进程,函数pthread()可以新建一个线程。但无论线程还是进程,都是用task_struct结构表示的,唯一的区别就是共享的数据区域不同。 换句话说,线程看起来跟进程没有区别,只是线程的某些数据区域和其父进程是共享的,而子进程是拷贝副本,而不是共享。就比如说,mm结构和files结构在线程中都是共享的,我画两张图你就明白了: 所以说,我们的多线程程序要利用锁机制,避免多个线程同时往同一区域写入数据,否则可能造成数据错乱。 那么你可能问,既然进程和线程差不多,而且多进程数据不共享,即不存在数据错乱的问题,为什么多线程的使用比多进程普遍得多呢? 因为现实中数据共享的并发更普遍呀,比如十个人同时从一个账户取十元,我们希望的是这个共享账户的余额正确减少一百元,而不是希望每人获得一个账户的拷贝,每个拷贝账户减少十元。 当然,必须要说明的是,只有 Linux 系统将线程看做共享数据的进程,不对其做特殊看待,其他的很多操作系统是对线程和进程区别对待的,线程有其特有的数据结构,我个人认为不如 Linux 的这种设计简洁,增加了系统的复杂度。 在 Linux 中新建线程和进程的效率都是很高的,对于新建进程时内存区域拷贝的问题,Linux 采用了 copy-on-write 的策略优化,也就是并不真正复制父进程的内存空间,而是等到需要写操作时才去复制。所以 Linux 中新建进程和新建线程都是很迅速的。