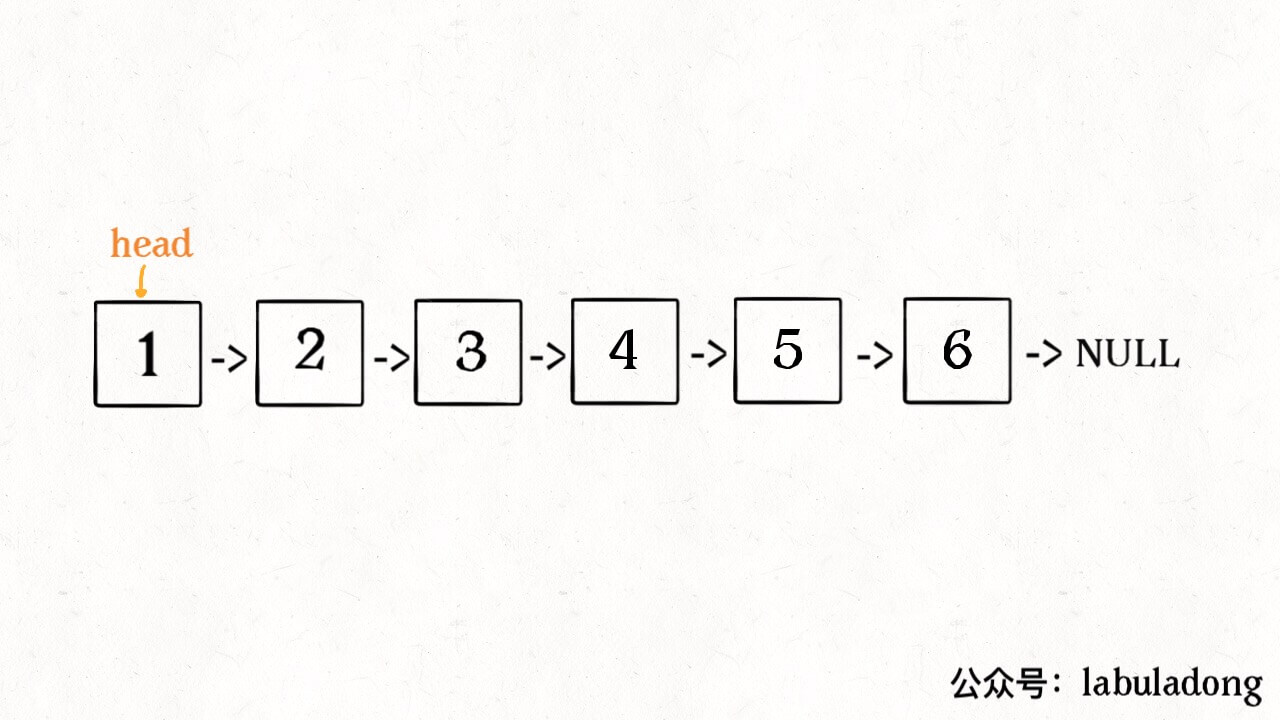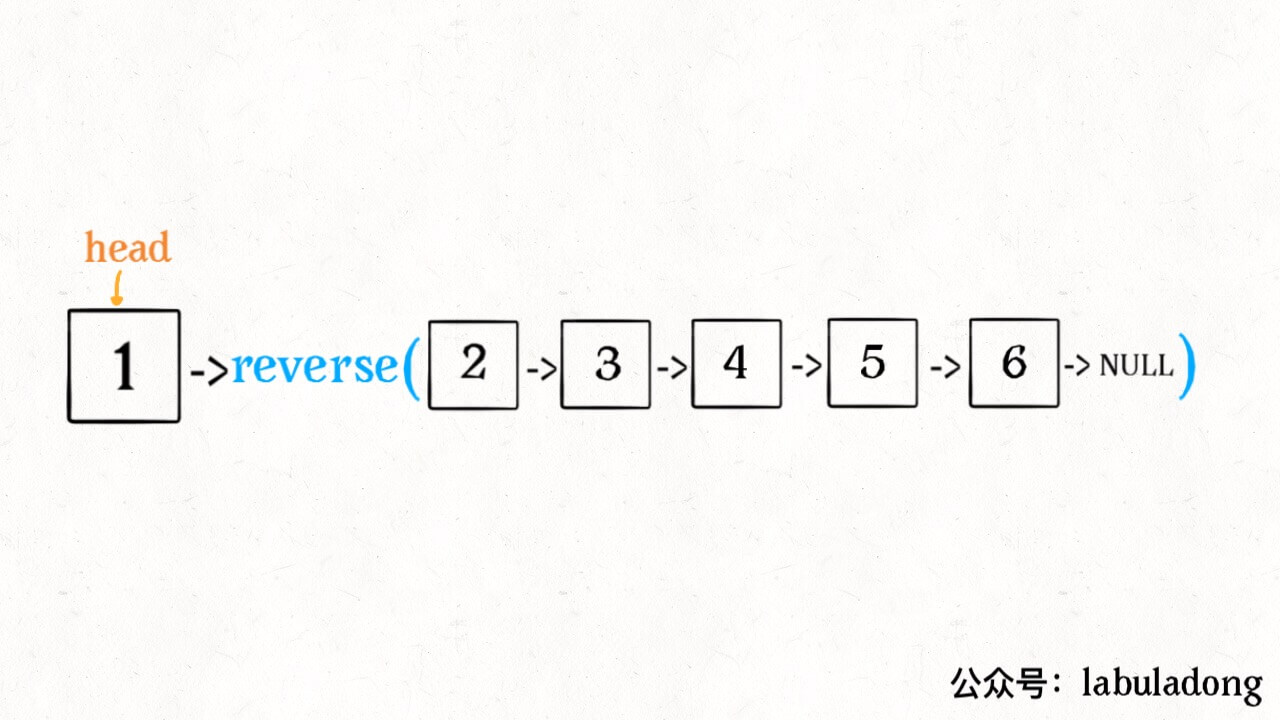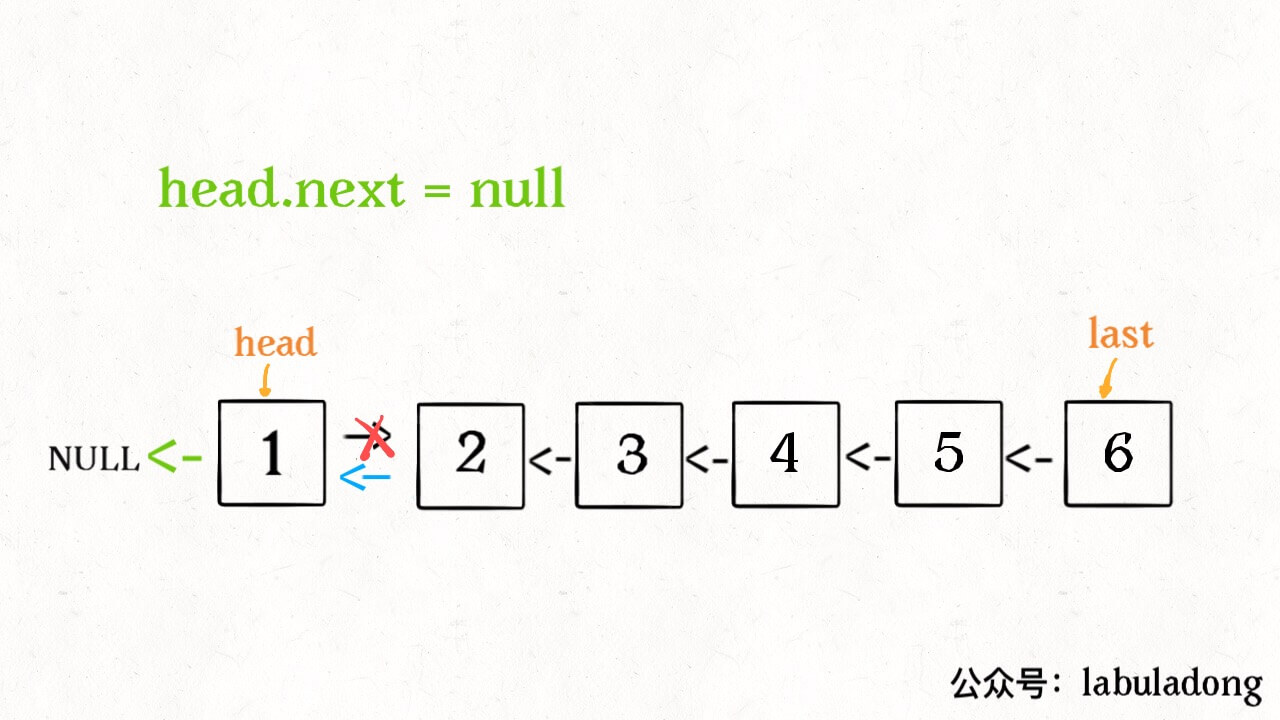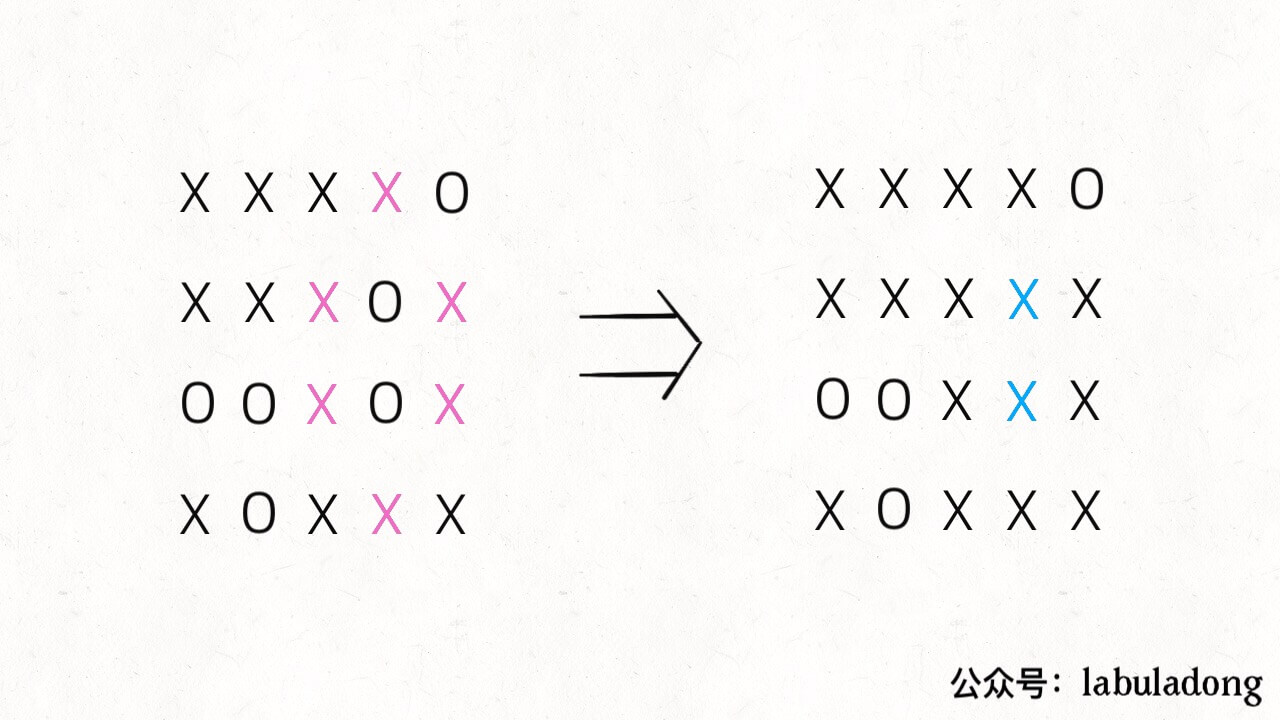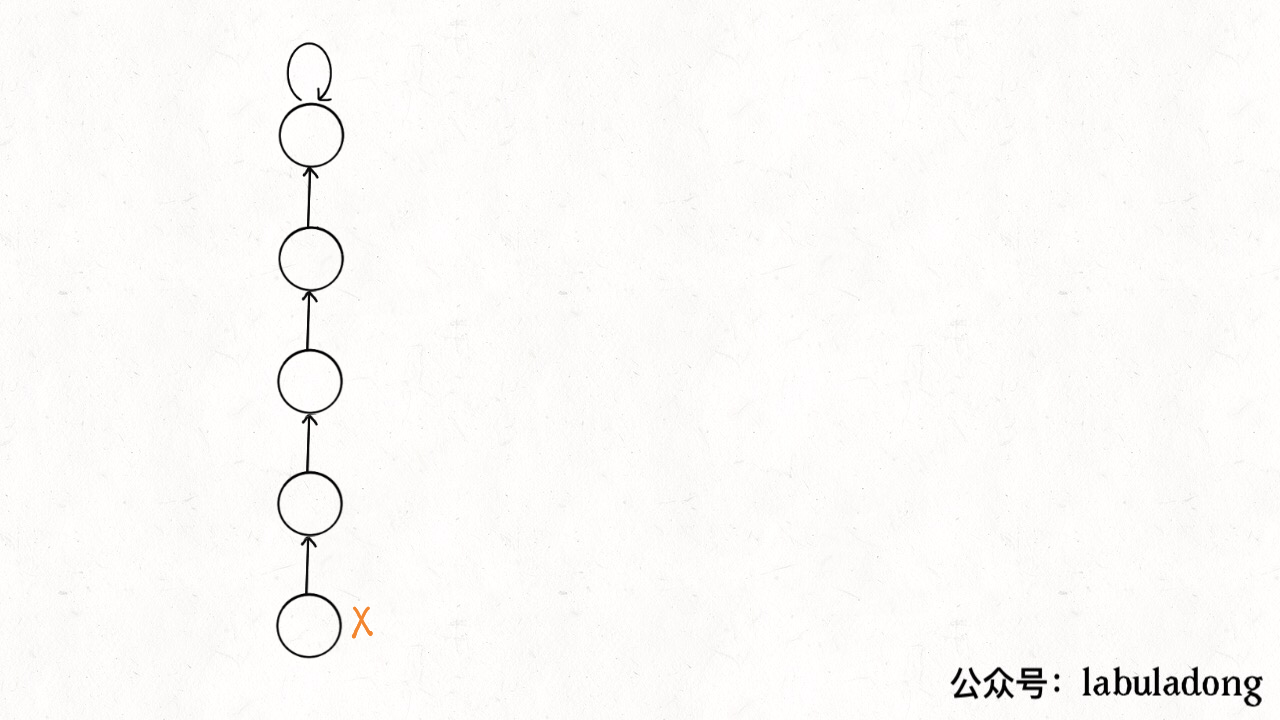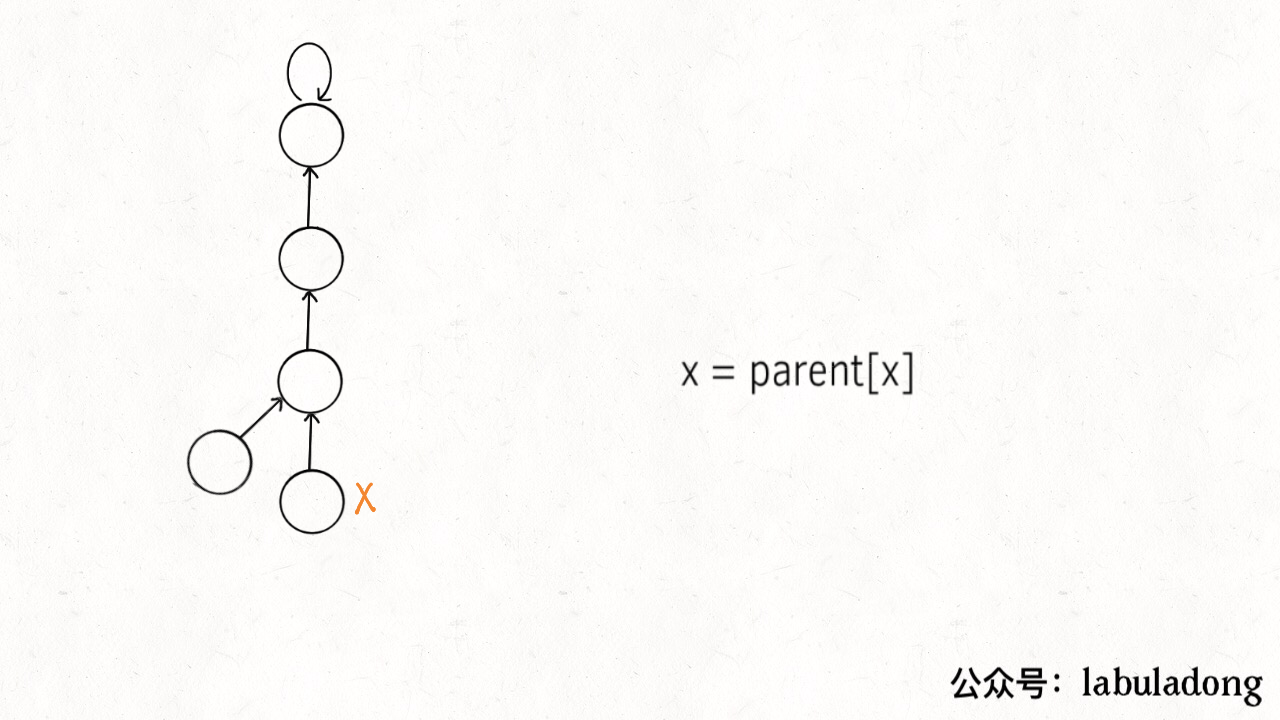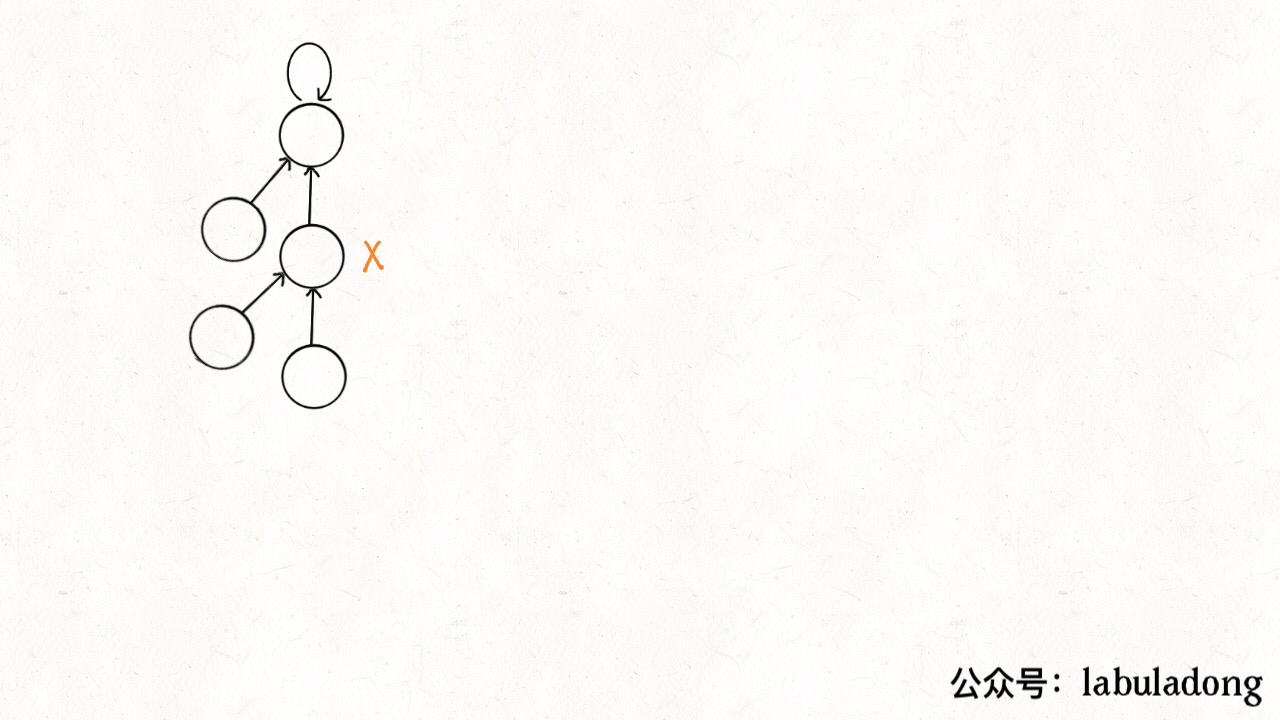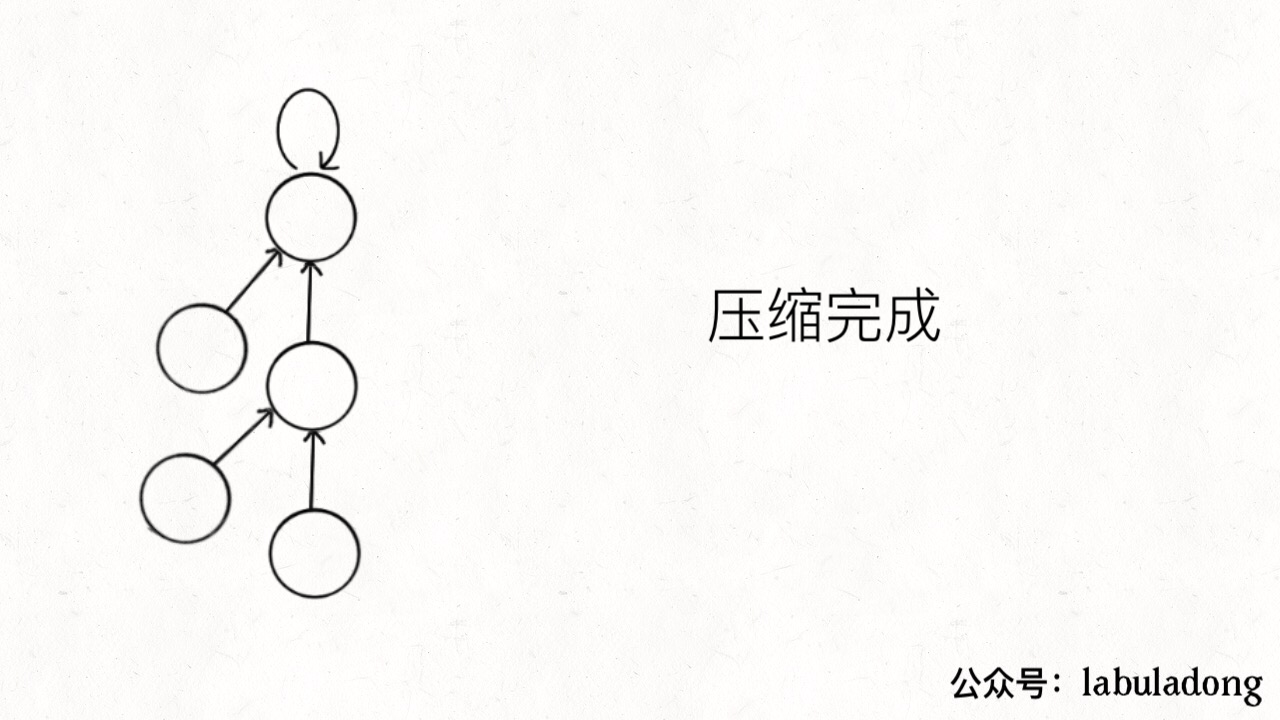反转单链表的迭代实现不是一个困难的事情,但是递归实现就有点难度了,如果再加一点难度,让你仅仅反转单链表中的一部分,你是否能够递归实现呢? 本文就来由浅入深,step by step 地解决这个问题。如果你还不会递归地反转单链表也没关系,本文会从递归反转整个单链表开始拓展,只要你明白单链表的结构,相信你能够有所收获。
1 2 3 4 5 6
// 单链表节点的结构 publicclassListNode{ int val; ListNode next; ListNode(int x) { val = x; } }
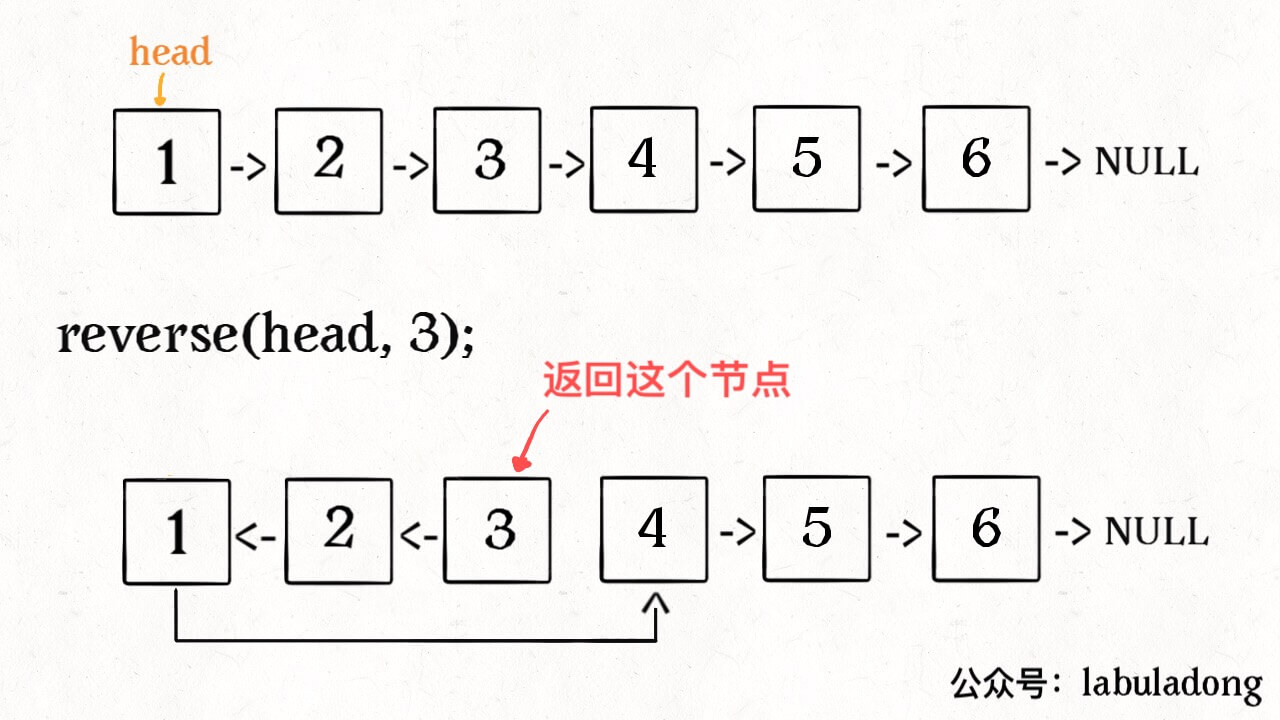
什么叫反转单链表的一部分呢,就是给你一个索引区间,让你把单链表中这部分元素反转,其他部分不变: 注意这里的索引是从 1 开始的。迭代的思路大概是:先用一个 for 循环找到第 m 个位置,然后再用一个 for 循环将 m 和 n 之间的元素反转。但是我们的递归解法不用一个 for 循环,纯递归实现反转。 迭代实现思路看起来虽然简单,但是细节问题很多的,反而不容易写对。相反,递归实现就很简洁优美,下面就由浅入深,先从反转整个单链表说起。
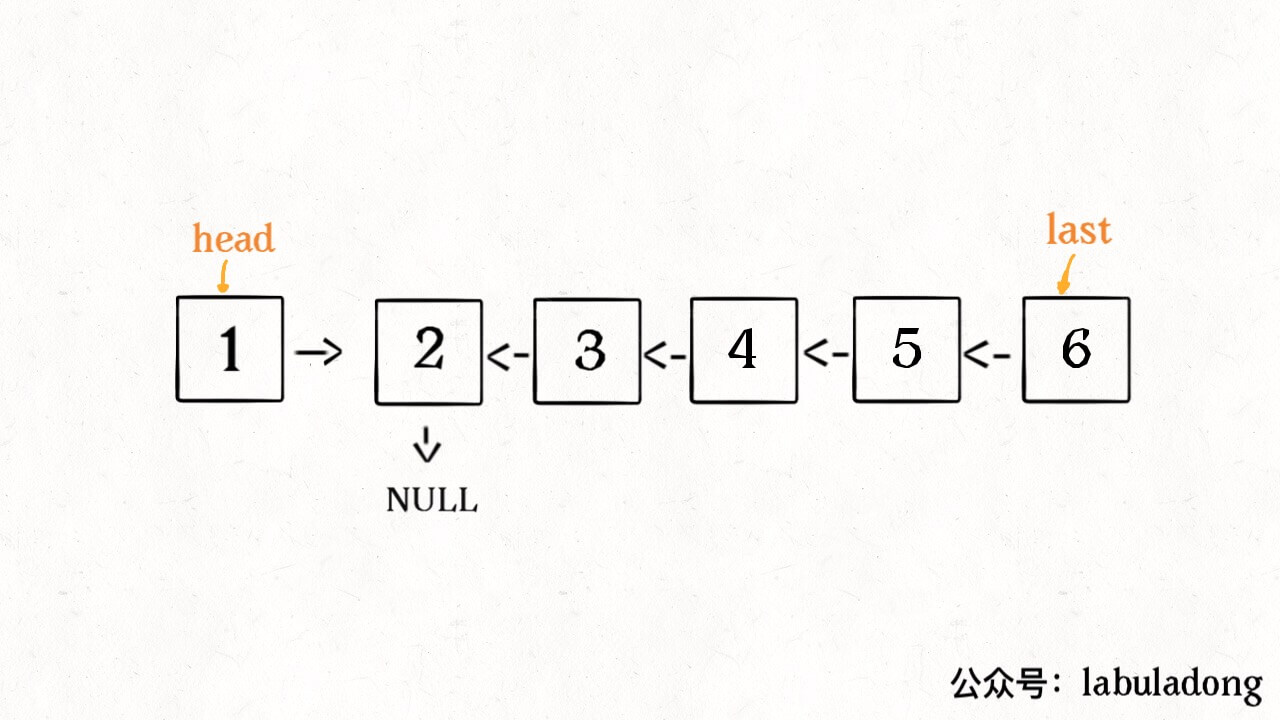
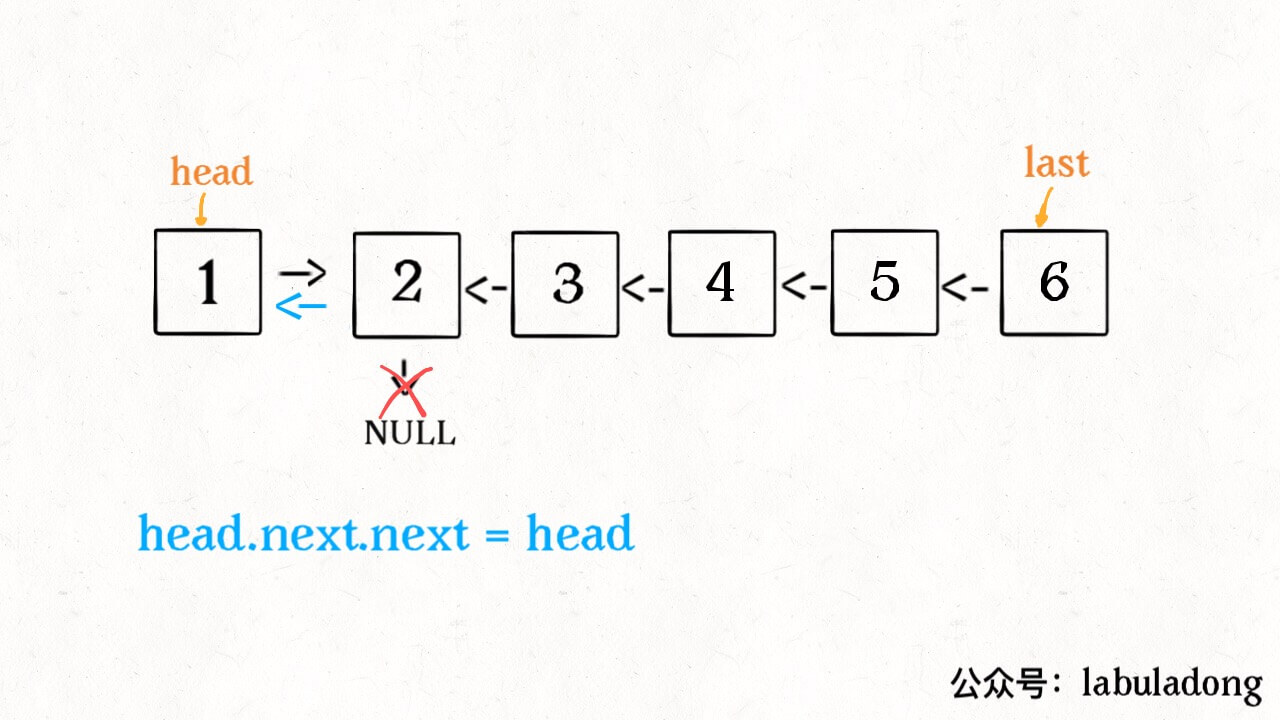
ListNode successor = null; // 后驱节点 // 反转以 head 为起点的 n 个节点,返回新的头结点 ListNode reverseN(ListNode head, int n){ if (n == 1) { // 记录第 n + 1 个节点 successor = head.next; return head; } // 以 head.next 为起点,需要反转前 n - 1 个节点 ListNode last = reverseN(head.next, n - 1); head.next.next = head; // 让反转之后的 head 节点和后面的节点连起来 head.next = successor; return last; }
具体的区别: 1、base case 变为 n == 1,反转一个元素,就是它本身,同时要记录后驱节点。 2、刚才我们直接把 head.next 设置为 null,因为整个链表反转后原来的 head 变成了整个链表的最后一个节点。但现在 head 节点在递归反转之后不一定是最后一个节点了,所以要记录后驱 successor(第 n + 1 个节点),反转之后将 head 连接上。 OK,如果这个函数你也能看懂,就离实现「反转一部分链表」不远了。
ListNode reverseBetween(ListNode head, int m, int n)
首先,如果 m == 1,就相当于反转链表开头的 n 个元素嘛,也就是我们刚才实现的功能:
1 2 3 4 5 6 7 8
ListNode reverseBetween(ListNode head, int m, int n){ // base case if (m == 1) { // 相当于反转前 n 个元素 return reverseN(head, n); } // ... }
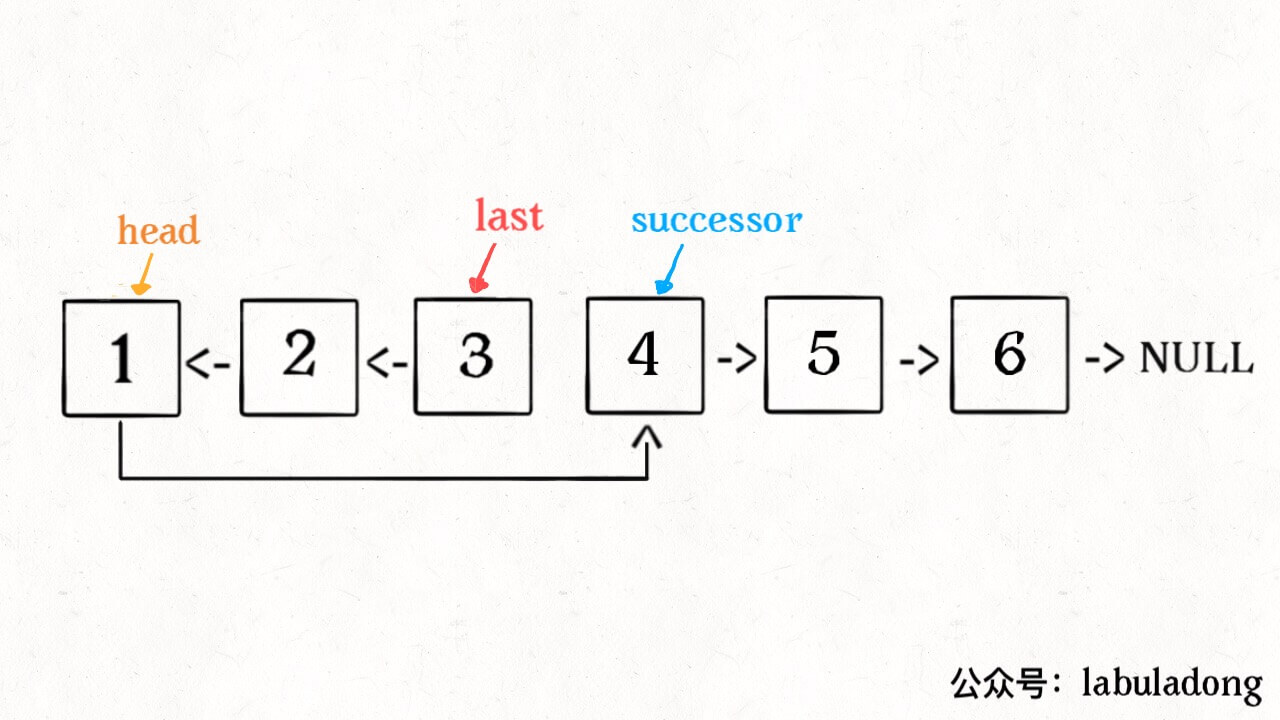
如果 m != 1 怎么办?如果我们把 head 的索引视为 1,那么我们是想从第 m 个元素开始反转对吧;如果把 head.next 的索引视为 1 呢?那么相对于 head.next,反转的区间应该是从第 m - 1 个元素开始的;那么对于 head.next.next 呢…… 区别于迭代思想,这就是递归思想,所以我们可以完成代码:
1 2 3 4 5 6 7 8 9
ListNode reverseBetween(ListNode head, int m, int n){ // base case if (m == 1) { return reverseN(head, n); } // 前进到反转的起点触发 base case head.next = reverseBetween(head.next, m - 1, n - 1); return head; }
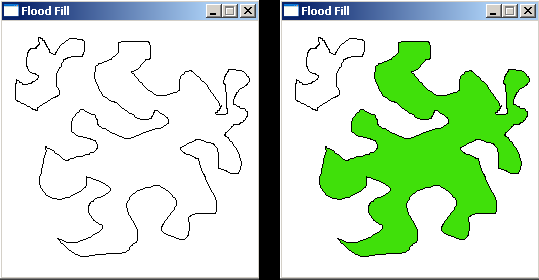
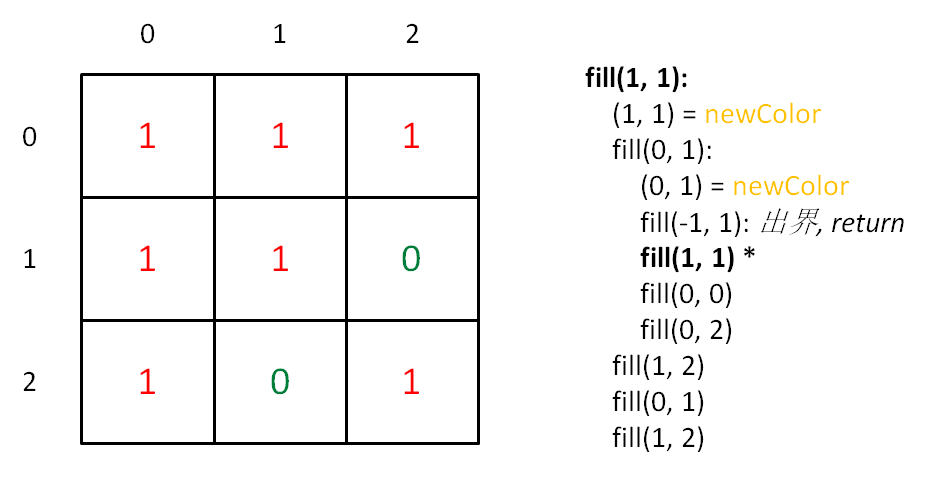
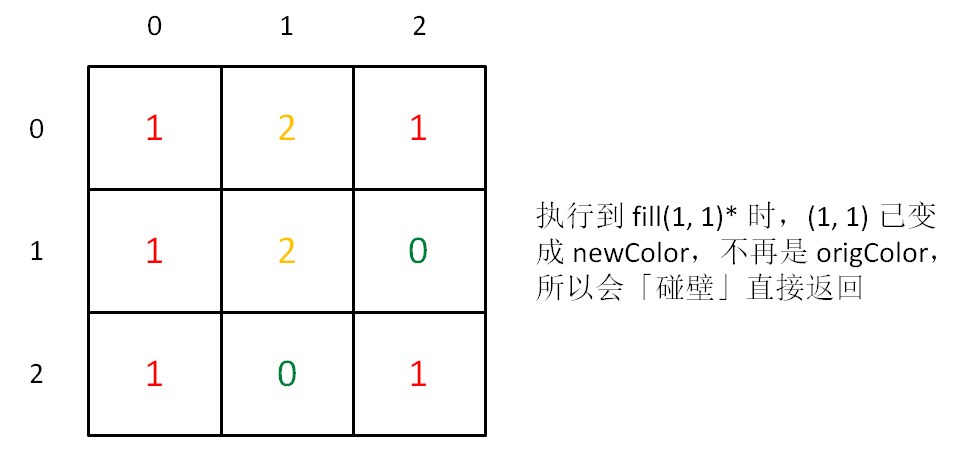
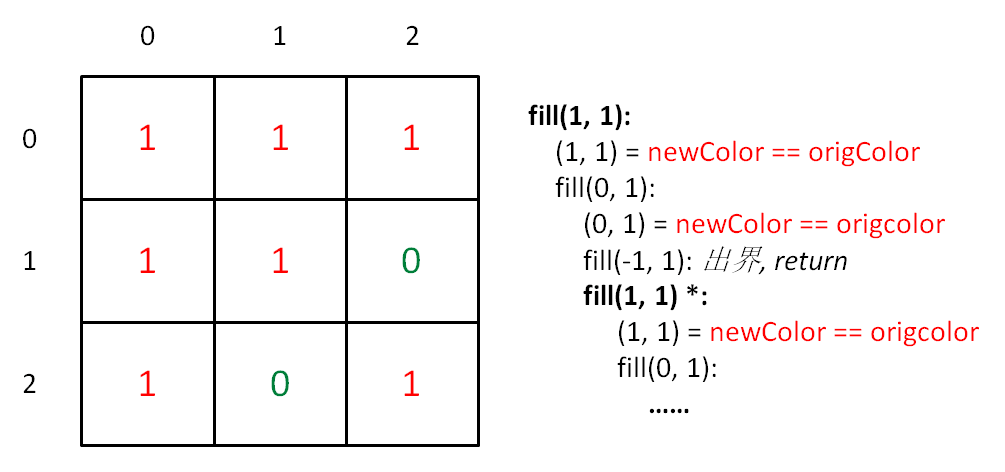
int[][] floodFill(int[][] image, int sr, int sc, int newColor) { int origColor = image[sr][sc]; fill(image, sr, sc, origColor, newColor); return image; } voidfill(int[][] image, int x, int y, int origColor, int newColor){ // 出界:超出边界索引 if (!inArea(image, x, y)) return; // 碰壁:遇到其他颜色,超出 origColor 区域 if (image[x][y] != origColor) return; image[x][y] = newColor;
fill(image, x, y + 1, origColor, newColor); fill(image, x, y - 1, origColor, newColor); fill(image, x - 1, y, origColor, newColor); fill(image, x + 1, y, origColor, newColor); } booleaninArea(int[][] image, int x, int y){ return x >= 0 && x < image.length && y >= 0 && y < image[0].length; }
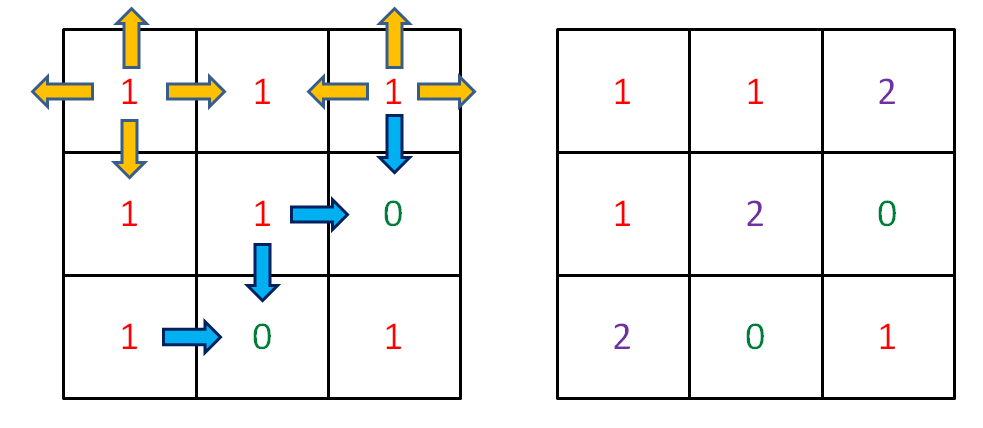
voidfill(int[][] image, int x, int y, int origColor, int newColor){ // 出界:超出数组边界 if (!inArea(image, x, y)) return; // 碰壁:遇到其他颜色,超出 origColor 区域 if (image[x][y] != origColor) return; // 已探索过的 origColor 区域 if (image[x][y] == -1) return;
// choose:打标记,以免重复 image[x][y] = -1; fill(image, x, y + 1, origColor, newColor); fill(image, x, y - 1, origColor, newColor); fill(image, x - 1, y, origColor, newColor); fill(image, x + 1, y, origColor, newColor); // unchoose:将标记替换为 newColor image[x][y] = newColor; }
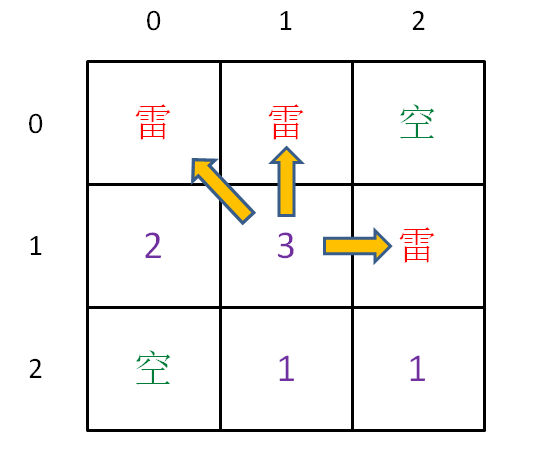
intfill(int[][] image, int x, int y, int origColor, int newColor){ // 出界:超出数组边界 if (!inArea(image, x, y)) return0; // 已探索过的 origColor 区域 if (visited[x][y]) return1; // 碰壁:遇到其他颜色,超出 origColor 区域 if (image[x][y] != origColor) return0; visited[x][y] = true;
int surround = fill(image, x - 1, y, origColor, newColor) + fill(image, x + 1, y, origColor, newColor) + fill(image, x, y - 1, origColor, newColor) + fill(image, x, y + 1, origColor, newColor);
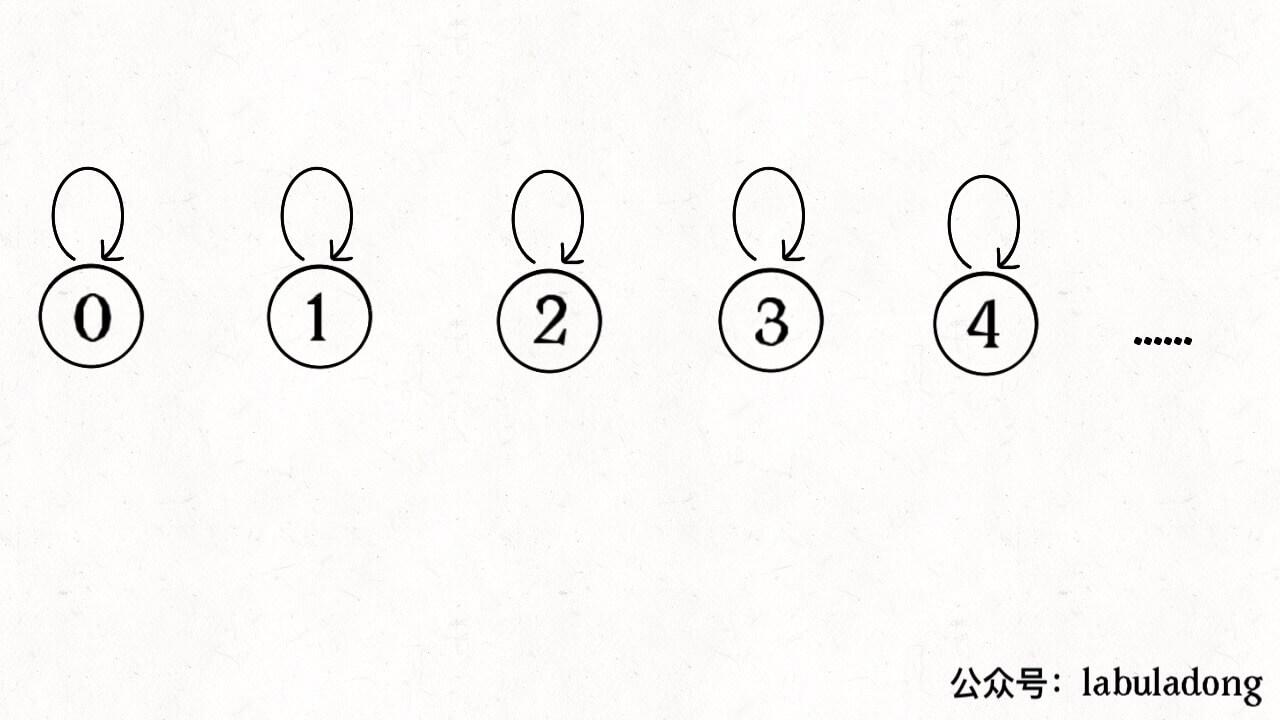
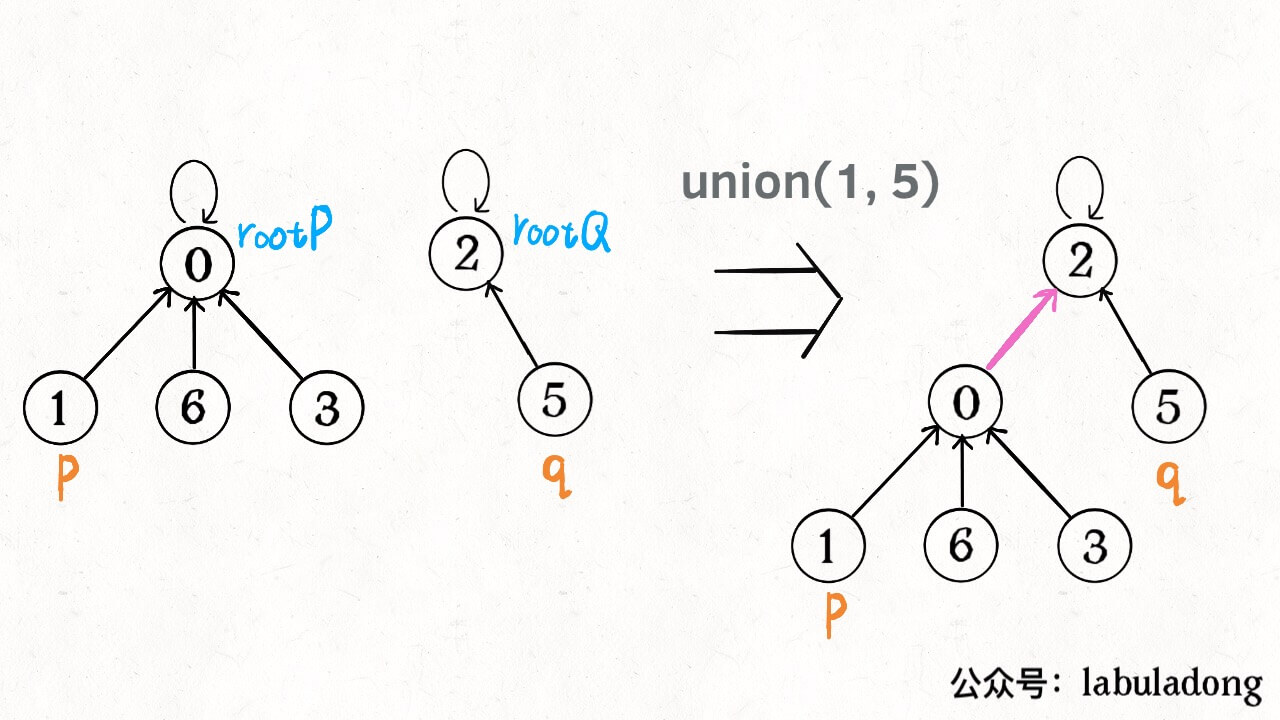
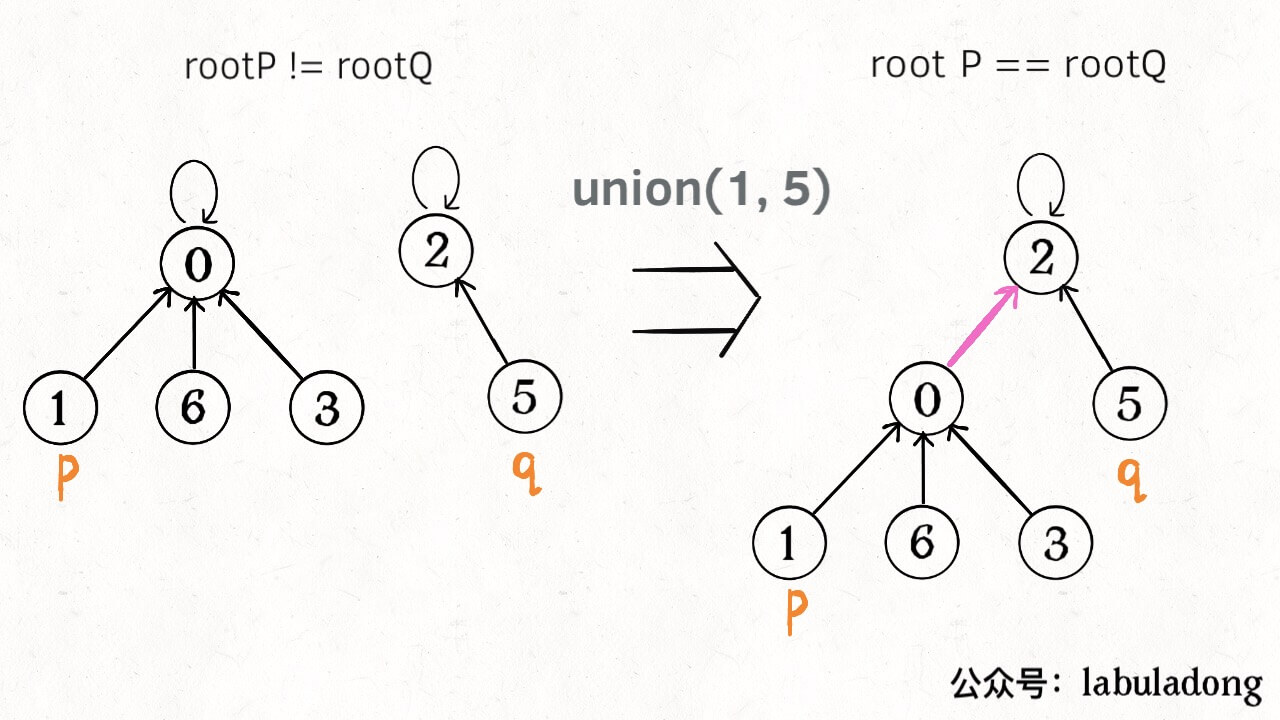
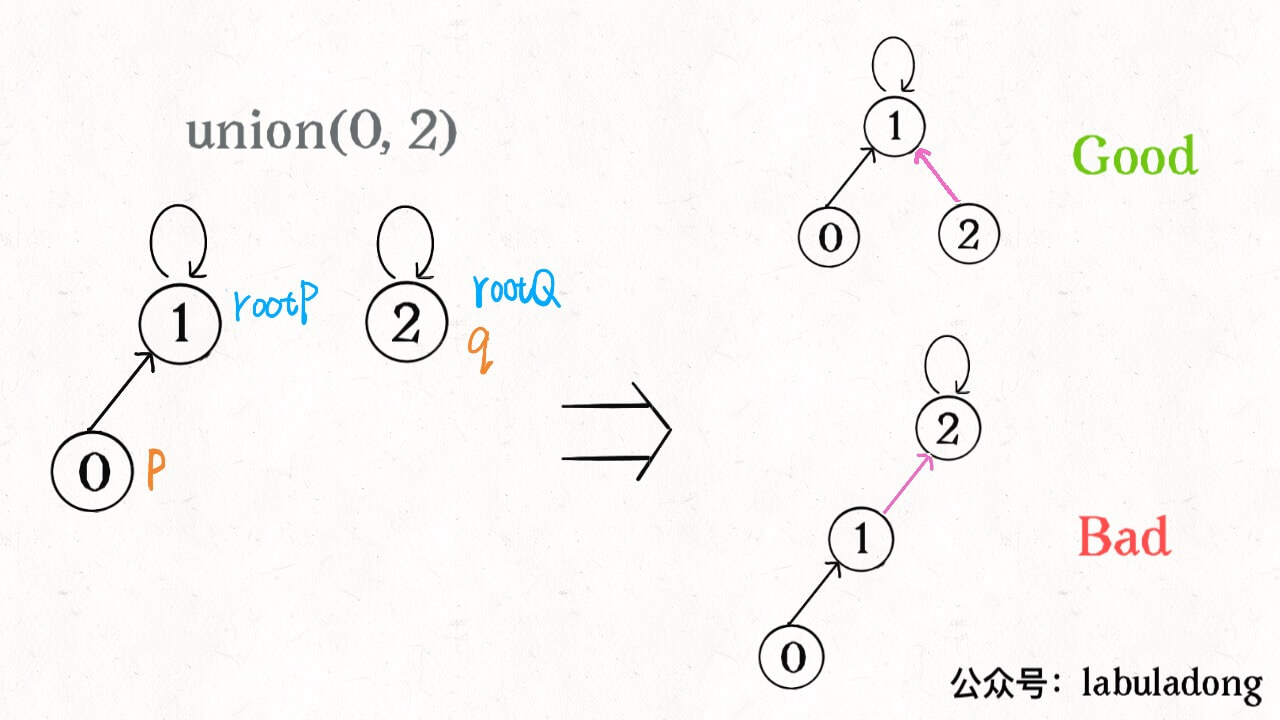
/* 将 p 和 q 连通 */ publicvoidunion(int p, int q){ int rootP = find(p); int rootQ = find(q); if (rootP == rootQ) return;
// 小树接到大树下面,较平衡 if (size[rootP] > size[rootQ]) { parent[rootQ] = rootP; size[rootP] += size[rootQ]; } else { parent[rootP] = rootQ; size[rootQ] += size[rootP]; } count--; } /* 判断 p 和 q 是否互相连通 */ publicbooleanconnected(int p, int q){ int rootP = find(p); int rootQ = find(q); // 处于同一棵树上的节点,相互连通 return rootP == rootQ; } /* 返回节点 x 的根节点 */ privateintfind(int x){ while (parent[x] != x) { // 进行路径压缩 parent[x] = parent[parent[x]]; x = parent[x]; } return x; }
publicintcount(){ return count; } }
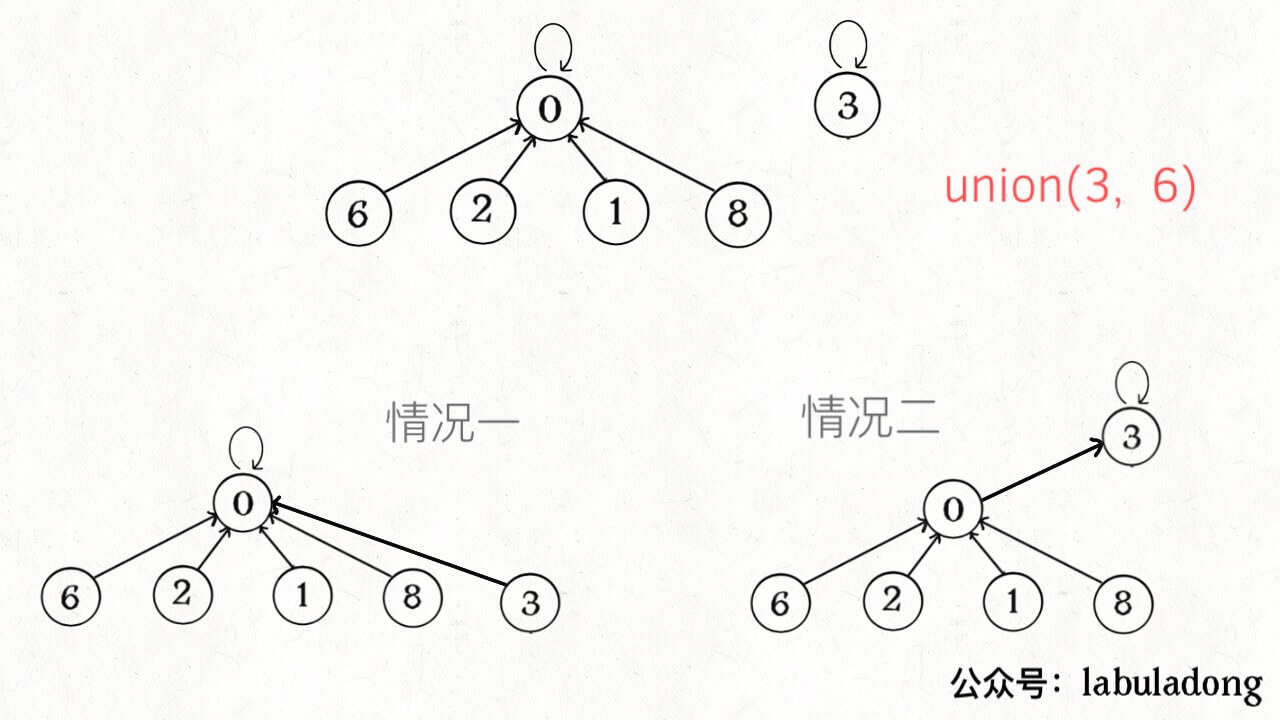
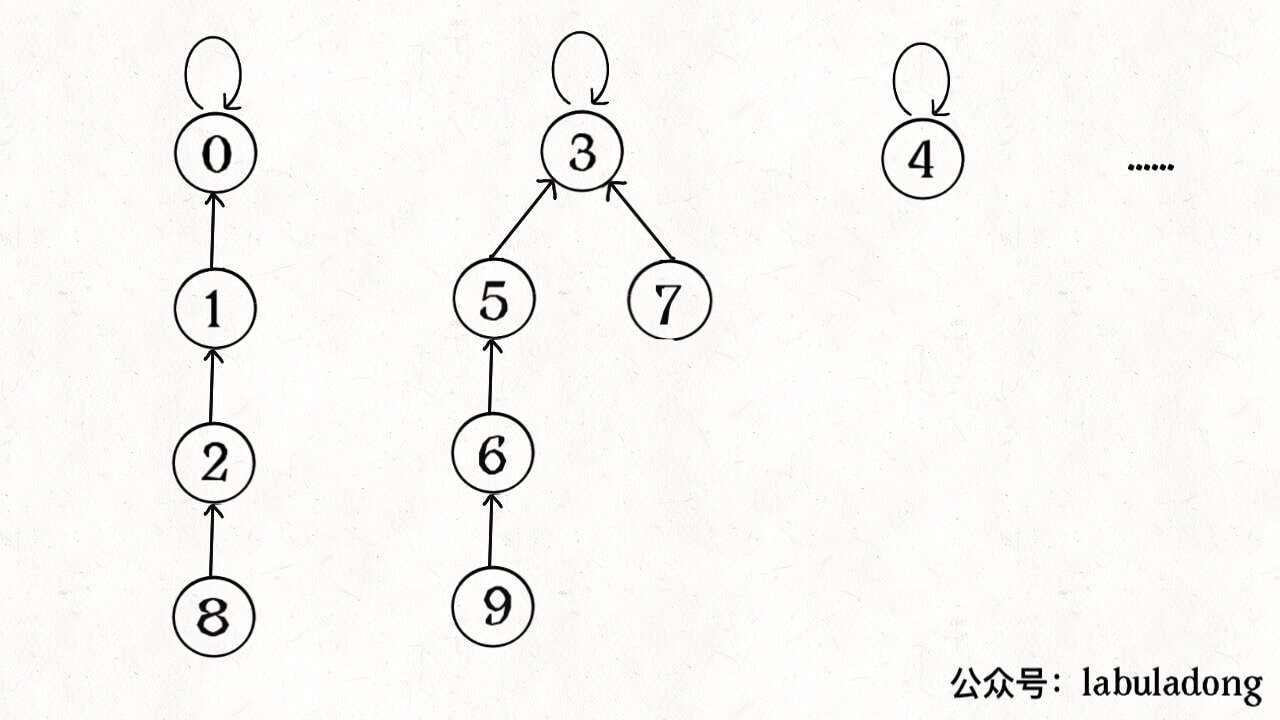
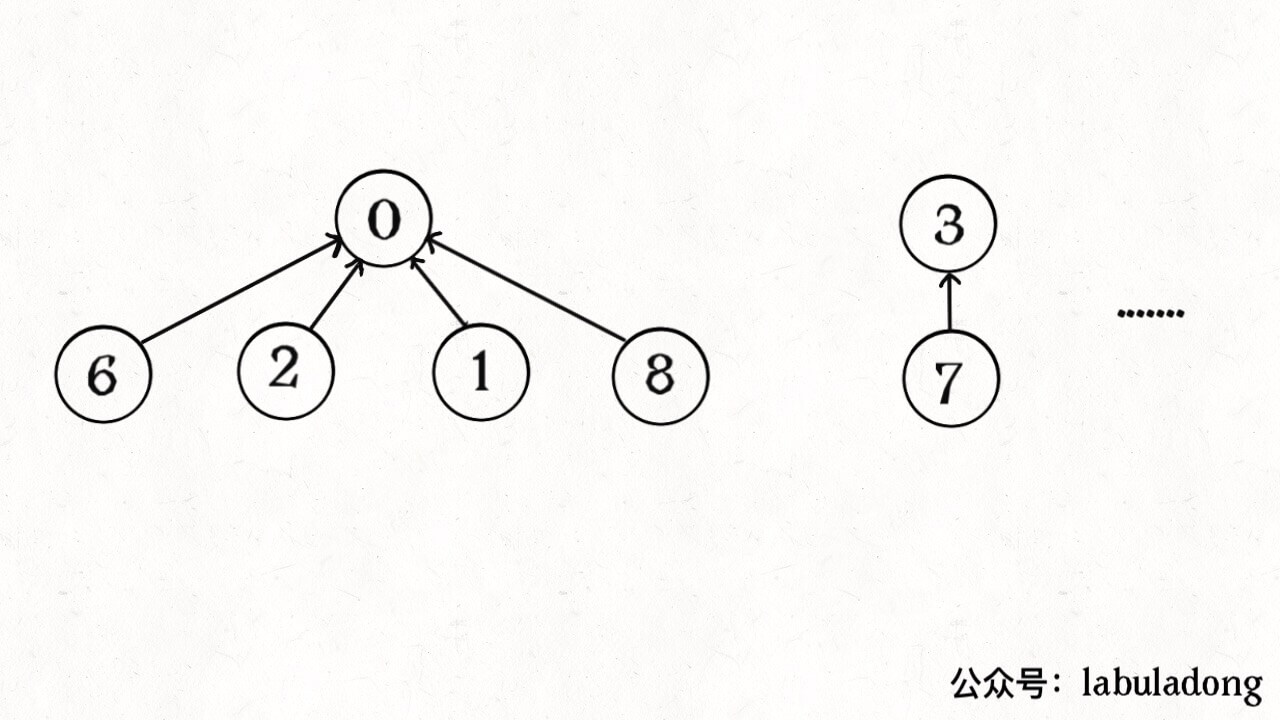
算法的关键点有 3 个: 1、用 parent 数组记录每个节点的父节点,相当于指向父节点的指针,所以 parent 数组内实际存储着一个森林(若干棵多叉树)。 2、用 size 数组记录着每棵树的重量,目的是让 union 后树依然拥有平衡性,而不会退化成链表,影响操作效率。 3、在 find 函数中进行路径压缩,保证任意树的高度保持在常数,使得 union 和 connected API 时间复杂度为 O(1)。 有的读者问,既然有了路径压缩,size 数组的重量平衡还需要吗?这个问题很有意思,因为路径压缩保证了树高为常数(不超过 3),那么树就算不平衡,高度也是常数,基本没什么影响。 我认为,论时间复杂度的话,确实,不需要重量平衡也是 O(1)。但是如果加上 size 数组辅助,效率还是略微高一些,比如下面这种情况: 如果带有重量平衡优化,一定会得到情况一,而不带重量优化,可能出现情况二。高度为 3 时才会触发路径压缩那个 while 循环,所以情况一根本不会触发路径压缩,而情况二会多执行很多次路径压缩,将第三层节点压缩到第二层。 也就是说,去掉重量平衡,虽然对于单个的 find 函数调用,时间复杂度依然是 O(1),但是对于 API 调用的整个过程,效率会有一定的下降。当然,好处就是减少了一些空间,不过对于 Big O 表示法来说,时空复杂度都没变。 下面言归正传,来看看这个算法有什么实际应用。
一、DFS 的替代方案
很多使用 DFS 深度优先算法解决的问题,也可以用 Union-Find 算法解决。 比如第 130 题,被围绕的区域:给你一个 M×N 的二维矩阵,其中包含字符 X 和 O,让你找到矩阵中四面被 X 围住的 O,并且把它们替换成 X。
1
voidsolve(char[][] board);
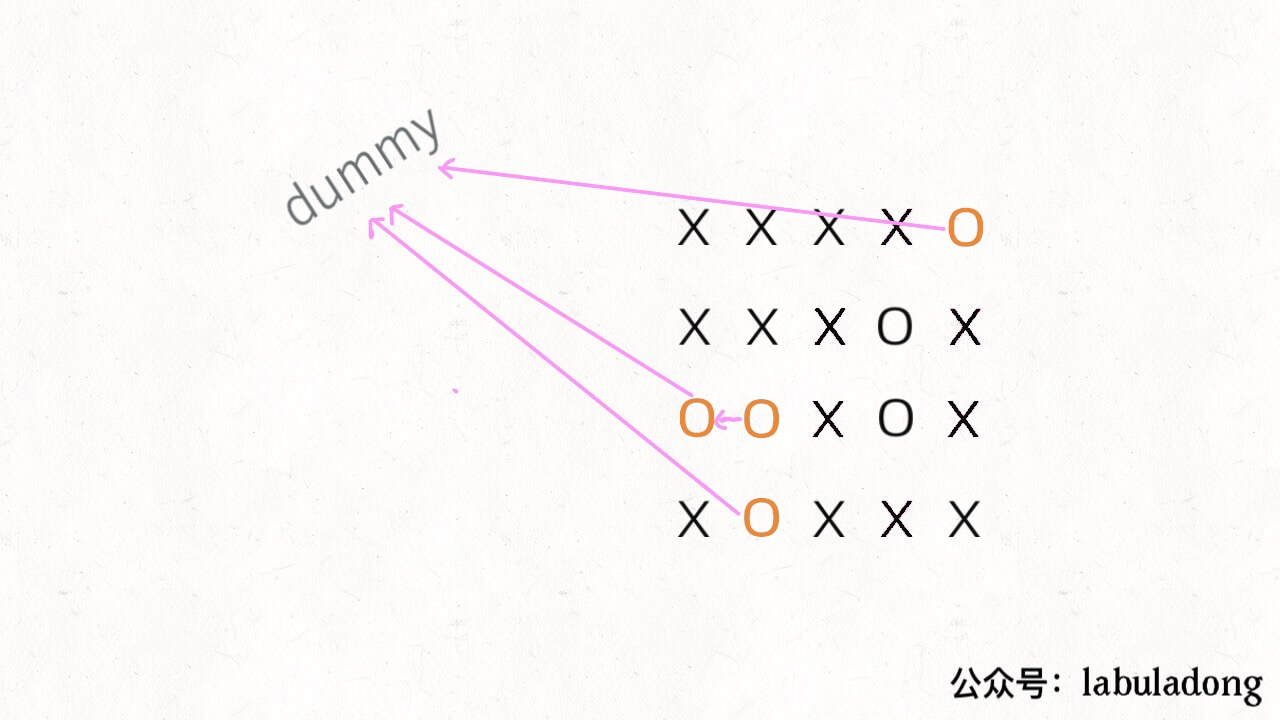
注意哦,必须是四面被围的 O 才能被换成 X,也就是说边角上的 O 一定不会被围,进一步,与边角上的 O 相连的 O 也不会被 X 围四面,也不会被替换。 PS:这让我想起小时候玩的棋类游戏「黑白棋」,只要你用两个棋子把对方的棋子夹在中间,对方的子就被替换成你的子。可见,占据四角的棋子是无敌的,与其相连的边棋子也是无敌的(无法被夹掉)。 解决这个问题的传统方法也不困难,先用 for 循环遍历棋盘的四边,用 DFS 算法把那些与边界相连的 O 换成一个特殊字符,比如 #;然后再遍历整个棋盘,把剩下的 O 换成 X,把 # 恢复成 O。这样就能完成题目的要求,时间复杂度 O(MN)。 这个问题也可以用 Union-Find 算法解决,虽然实现复杂一些,甚至效率也略低,但这是使用 Union-Find 算法的通用思想,值得一学。 你可以把那些不需要被替换的 O 看成一个拥有独门绝技的门派,它们有一个共同祖师爷叫 dummy,这些 O 和 dummy 互相连通,而那些需要被替换的 O 与 dummy 不连通。 这就是 Union-Find 的核心思路,明白这个图,就很容易看懂代码了。 首先要解决的是,根据我们的实现,Union-Find 底层用的是一维数组,构造函数需要传入这个数组的大小,而题目给的是一个二维棋盘。 这个很简单,二维坐标 (x,y) 可以转换成 x * n + y 这个数(m 是棋盘的行数,n 是棋盘的列数)。敲黑板,这是将二维坐标映射到一维的常用技巧。 其次,我们之前描述的「祖师爷」是虚构的,需要给他老人家留个位置。索引 [0.. m*n-1] 都是棋盘内坐标的一维映射,那就让这个虚拟的 dummy 节点占据索引 m * n 好了。
voidsolve(char[][] board){ if (board.length == 0) return; int m = board.length; int n = board[0].length; // 给 dummy 留一个额外位置 UF uf = new UF(m * n + 1); int dummy = m * n; // 将首列和末列的 O 与 dummy 连通 for (int i = 0; i < m; i++) { if (board[i][0] == 'O') uf.union(i * n, dummy); if (board[i][n - 1] == 'O') uf.union(i * n + n - 1, dummy); } // 将首行和末行的 O 与 dummy 连通 for (int j = 0; j < n; j++) { if (board[0][j] == 'O') uf.union(j, dummy); if (board[m - 1][j] == 'O') uf.union(n * (m - 1) + j, dummy); } // 方向数组 d 是上下左右搜索的常用手法 int[][] d = newint[][]{{1,0}, {0,1}, {0,-1}, {-1,0}}; for (int i = 1; i < m - 1; i++) for (int j = 1; j < n - 1; j++) if (board[i][j] == 'O') // 将此 O 与上下左右的 O 连通 for (int k = 0; k < 4; k++) { int x = i + d[k][0]; int y = j + d[k][1]; if (board[x][y] == 'O') uf.union(x * n + y, i * n + j); } // 所有不和 dummy 连通的 O,都要被替换 for (int i = 1; i < m - 1; i++) for (int j = 1; j < n - 1; j++) if (!uf.connected(dummy, i * n + j)) board[i][j] = 'X'; }
这段代码很长,其实就是刚才的思路实现,只有和边界 O 相连的 O 才具有和 dummy 的连通性,他们不会被替换。 说实话,Union-Find 算法解决这个简单的问题有点杀鸡用牛刀,它可以解决更复杂,更具有技巧性的问题,主要思路是适时增加虚拟节点,想办法让元素「分门别类」,建立动态连通关系。
int[] twoSum(int[] nums, int target) { int n = nums.length; index<Integer, Integer> index = new HashMap<>(); // 构造一个哈希表:元素映射到相应的索引 for (int i = 0; i < n; i++) index.put(nums[i], i);
for (int i = 0; i < n; i++) { int other = target - nums[i]; // 如果 other 存在且不是 nums[i] 本身 if (index.containsKey(other) && index.get(other) != i) returnnewint[] {i, index.get(other)}; }
returnnewint[] {-1, -1}; }
这样,由于哈希表的查询时间为 O(1),算法的时间复杂度降低到 O(N),但是需要 O(N) 的空间复杂度来存储哈希表。不过综合来看,是要比暴力解法高效的。 我觉得 Two Sum 系列问题就是想教我们如何使用哈希表处理问题。我们接着往后看。
TwoSum II
这里我们稍微修改一下上面的问题。我们设计一个类,拥有两个 API:
1 2 3 4 5 6
classTwoSum{ // 向数据结构中添加一个数 number publicvoidadd(int number); // 寻找当前数据结构中是否存在两个数的和为 value publicbooleanfind(int value); }
classTwoSum{ Set<Integer> sum = new HashSet<>(); List<Integer> nums = new ArrayList<>(); publicvoidadd(int number){ // 记录所有可能组成的和 for (int n : nums) sum.add(n + number); nums.add(number); }
这道题的解法是比较巧妙的: 先对宽度 w 进行升序排序,如果遇到 w 相同的情况,则按照高度 h 降序排序。之后把所有的 h 作为一个数组,在这个数组上计算 LIS 的长度就是答案。 画个图理解一下,先对这些数对进行排序: 然后在 h 上寻找最长递增子序列: 这个子序列就是最优的嵌套方案。 这个解法的关键在于,对于宽度 w 相同的数对,要对其高度 h 进行降序排序。因为两个宽度相同的信封不能相互包含的,逆序排序保证在 w 相同的数对中最多只选取一个。 下面看代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// envelopes = [[w, h], [w, h]...] publicintmaxEnvelopes(int[][] envelopes){ int n = envelopes.length; // 按宽度升序排列,如果宽度一样,则按高度降序排列 Arrays.sort(envelopes, new Comparator<int[]>() { publicintcompare(int[] a, int[] b){ return a[0] == b[0] ? b[1] - a[1] : a[0] - b[0]; } }); // 对高度数组寻找 LIS int[] height = newint[n]; for (int i = 0; i < n; i++) height[i] = envelopes[i][1]; return lengthOfLIS(height); }
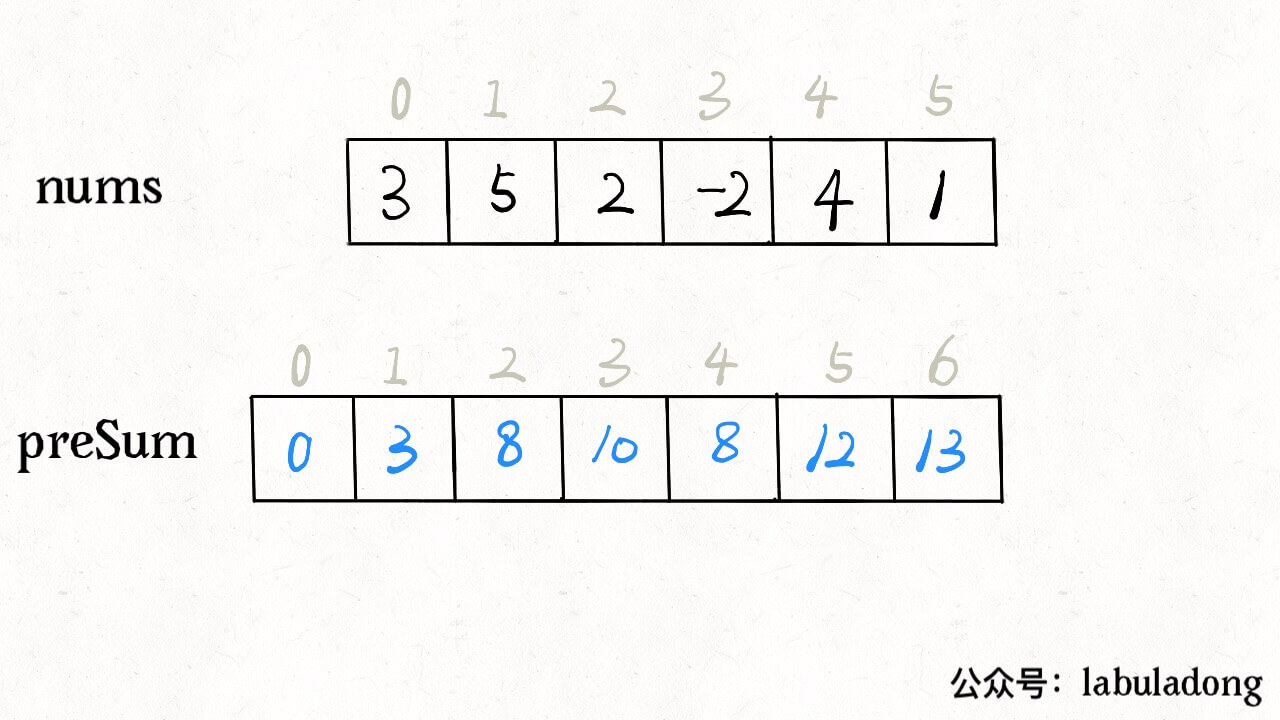
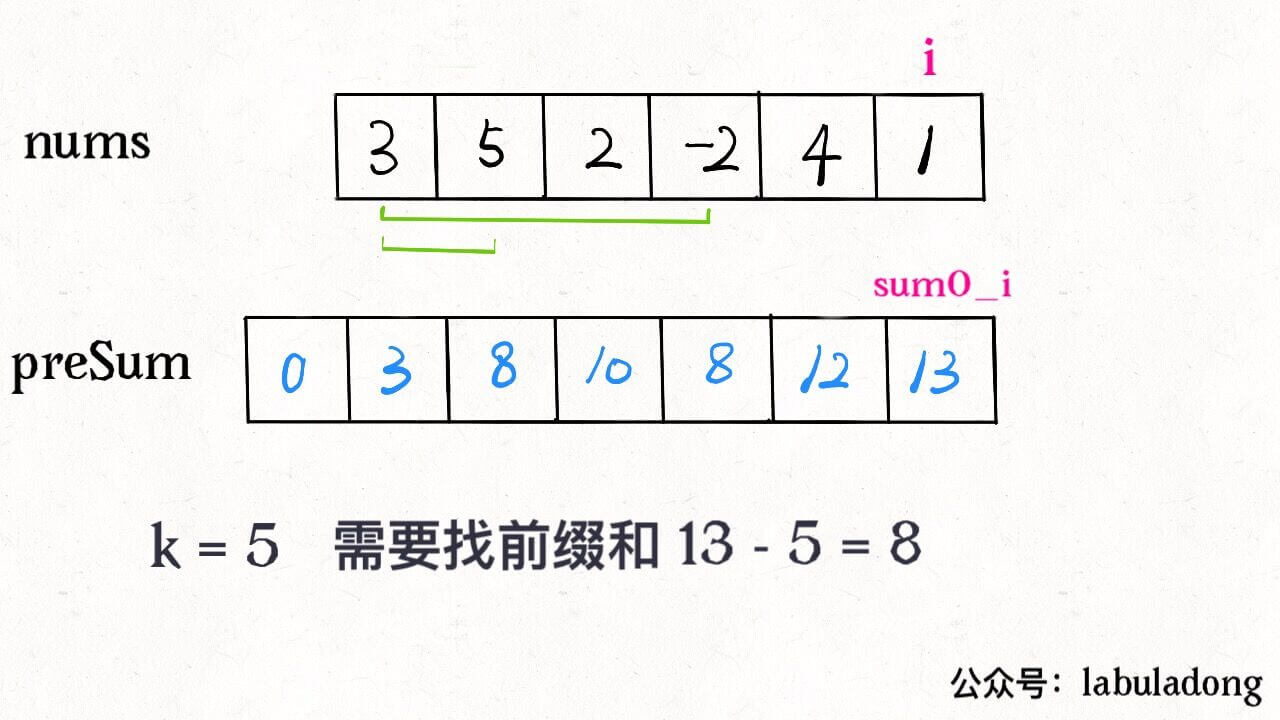
intsubarraySum(int[] nums, int k){ int n = nums.length; // 构造前缀和 int[] sum = newint[n + 1]; sum[0] = 0; for (int i = 0; i < n; i++) sum[i + 1] = sum[i] + nums[i];
int ans = 0; // 穷举所有子数组 for (int i = 1; i <= n; i++) for (int j = 0; j < i; j++) // sum of nums[j..i-1] if (sum[i] - sum[j] == k) ans++; return ans; }