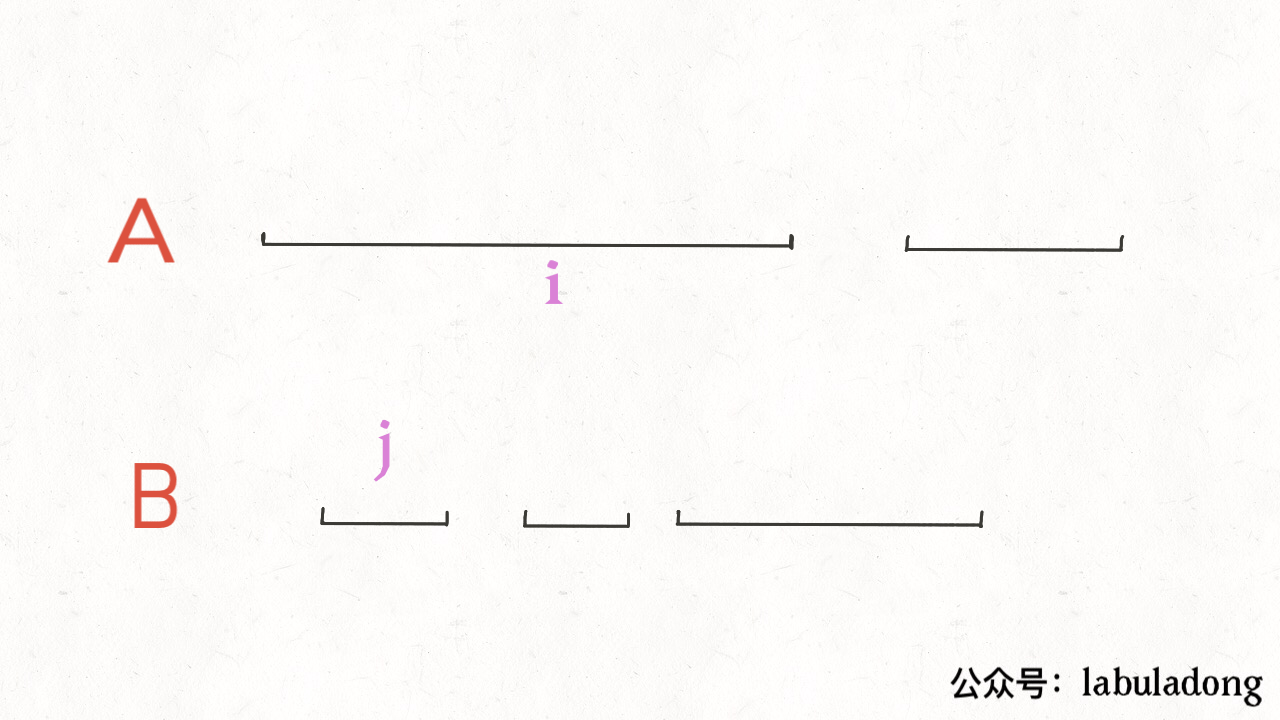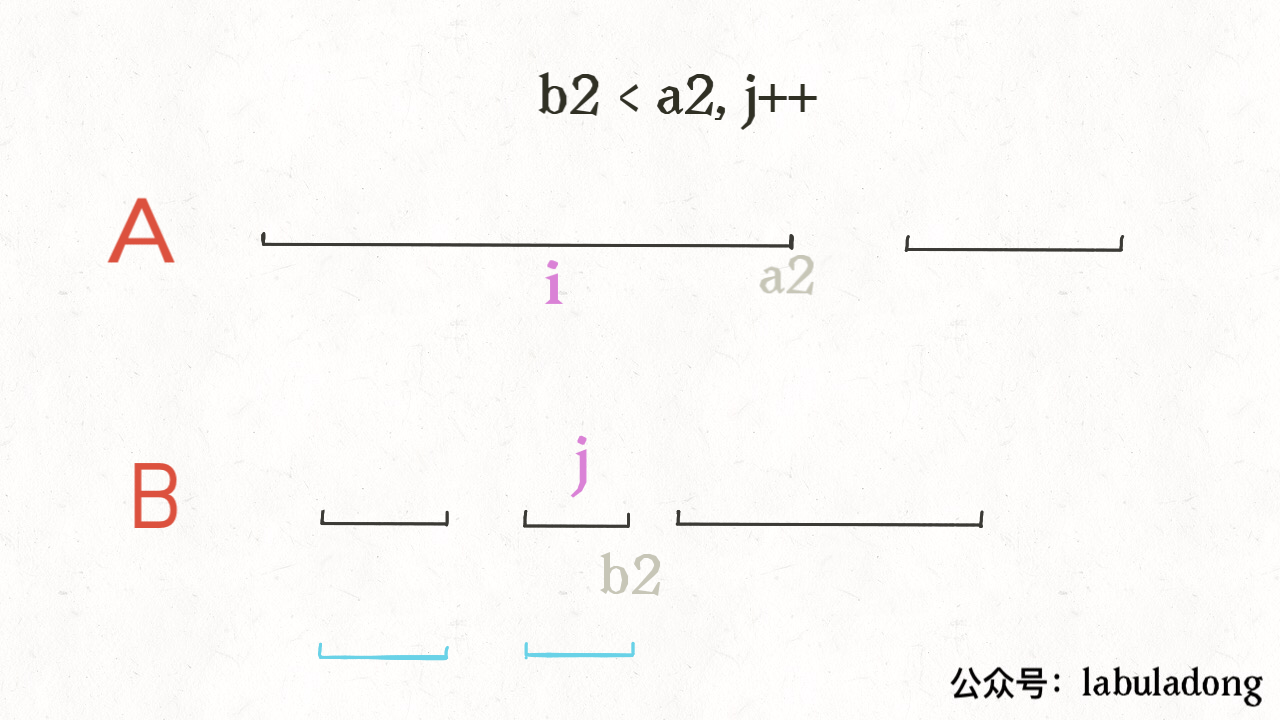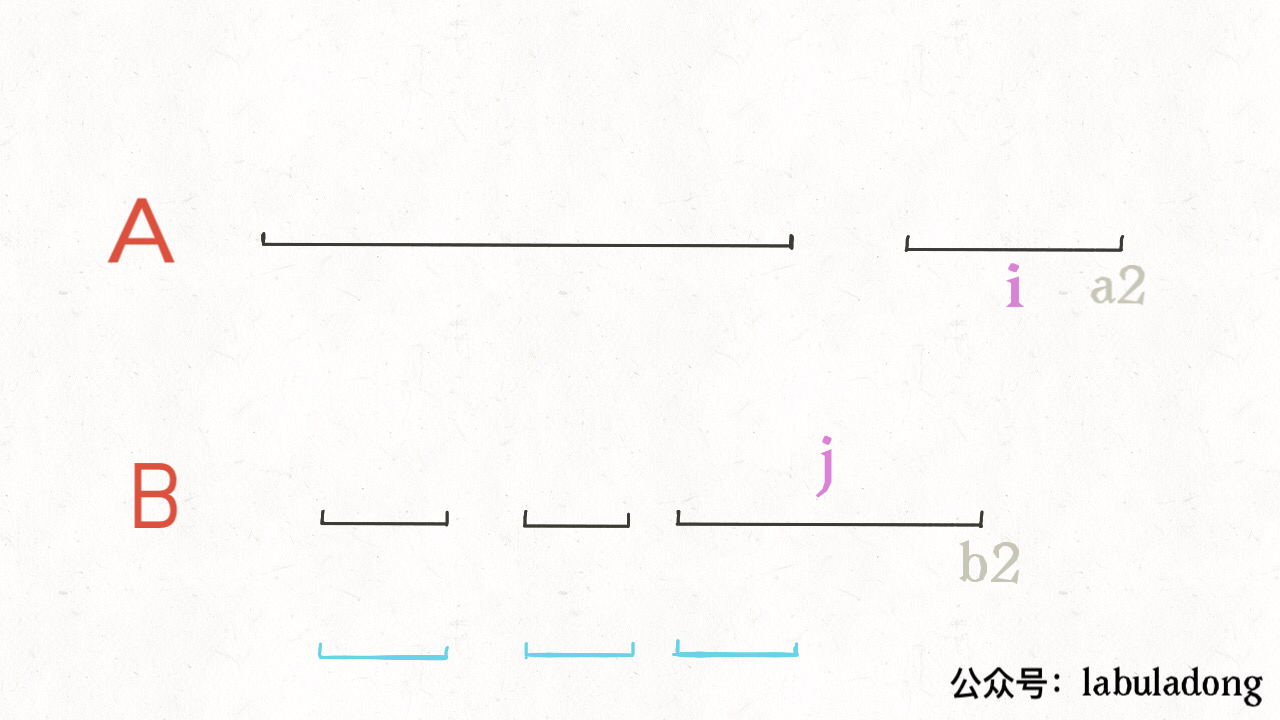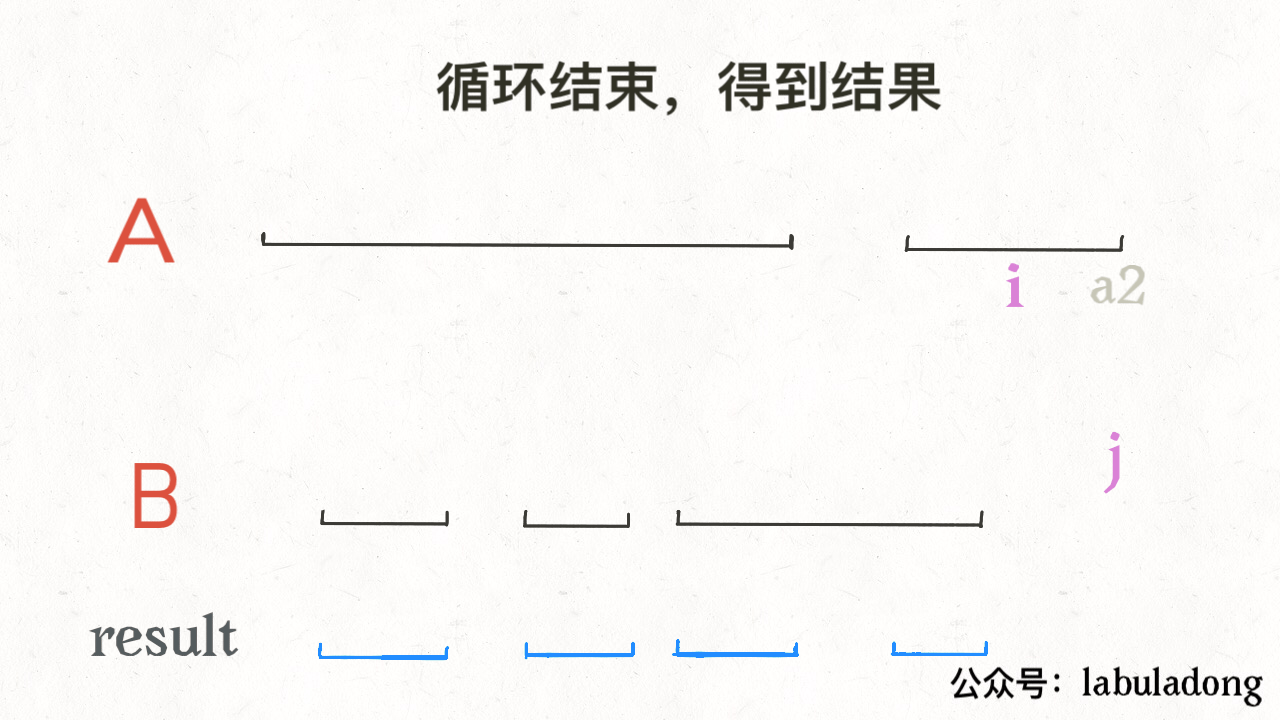
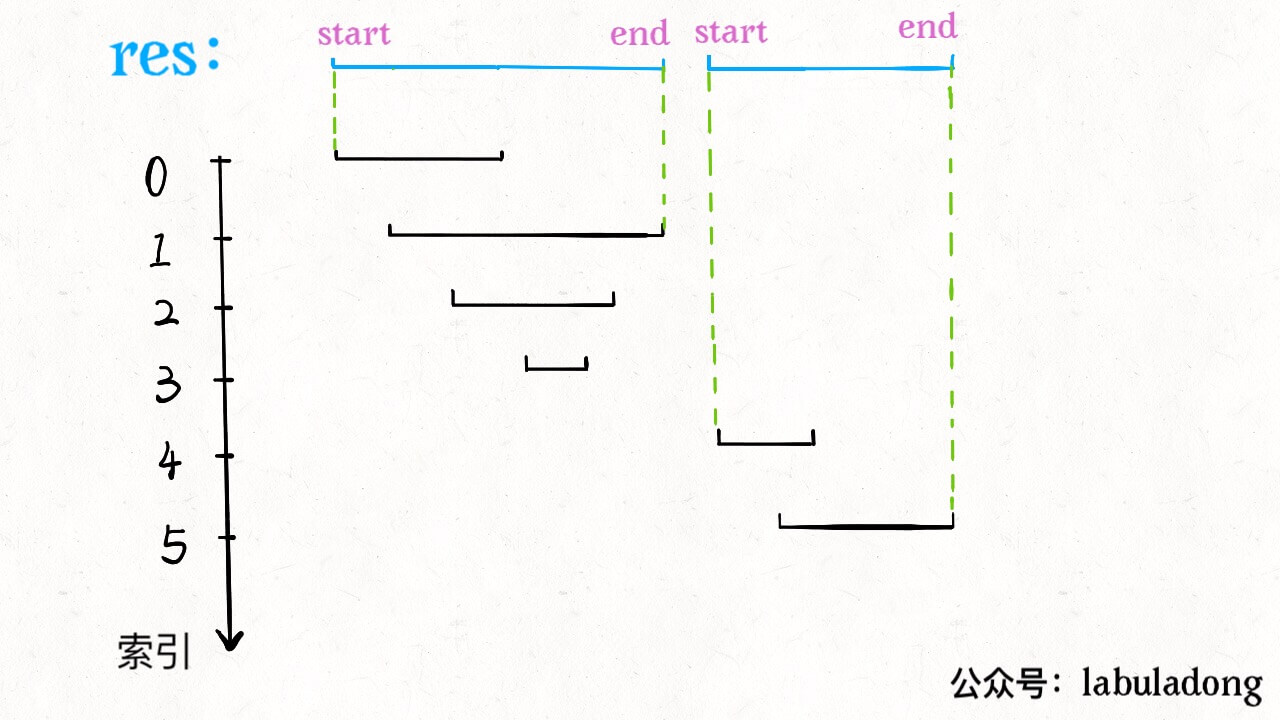
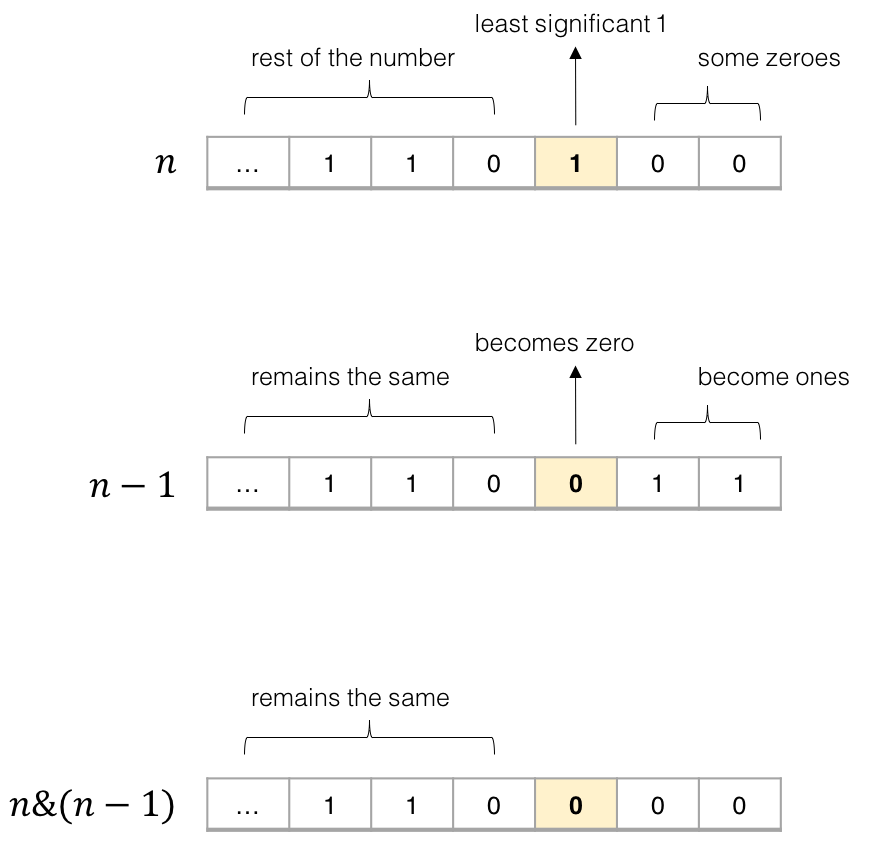
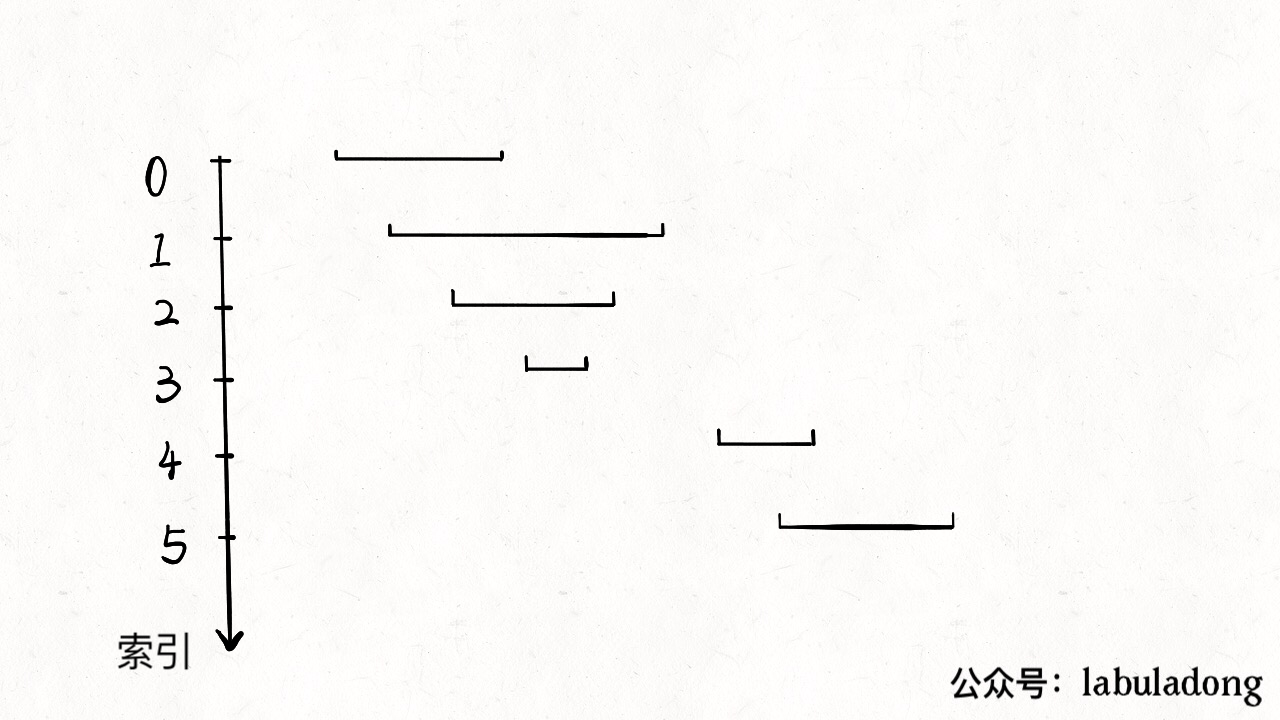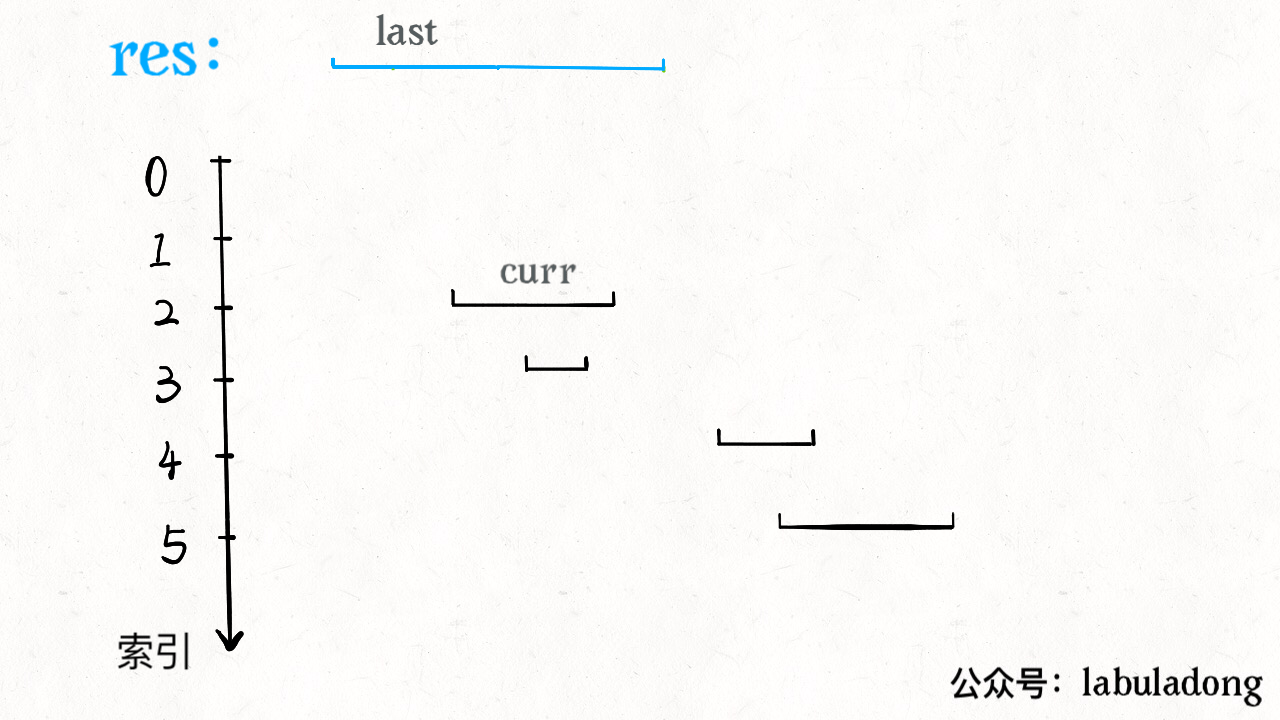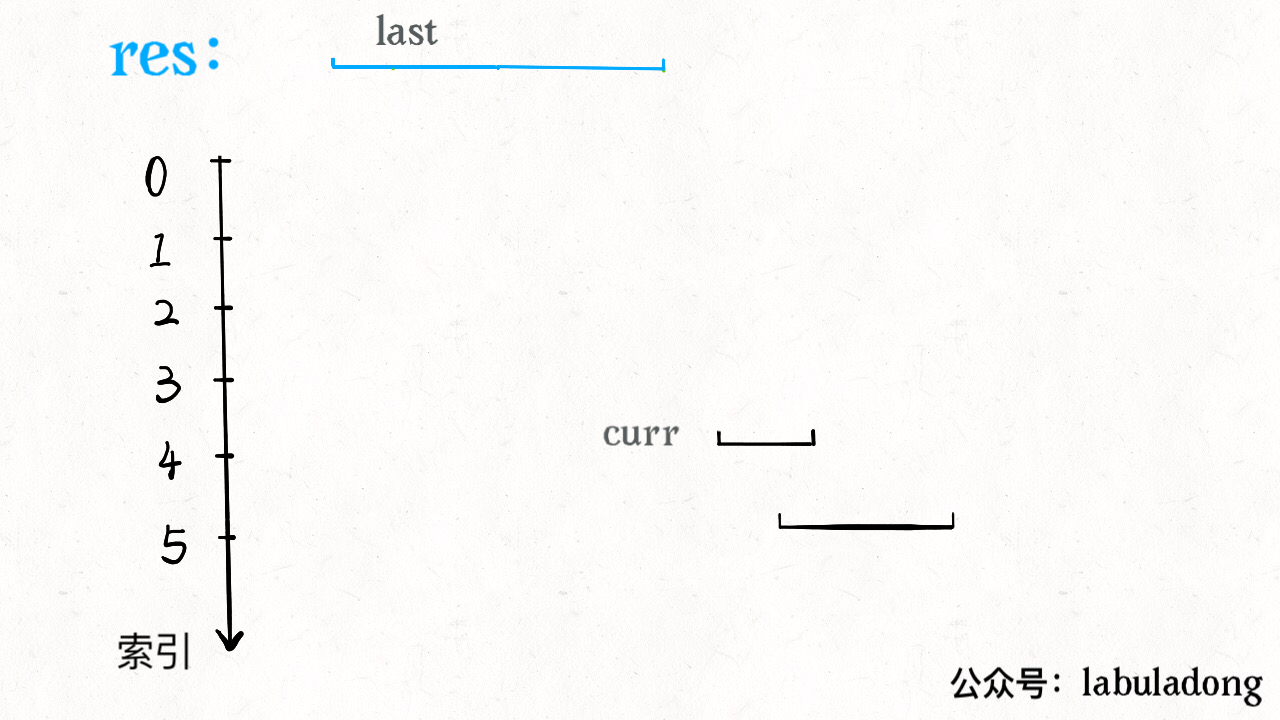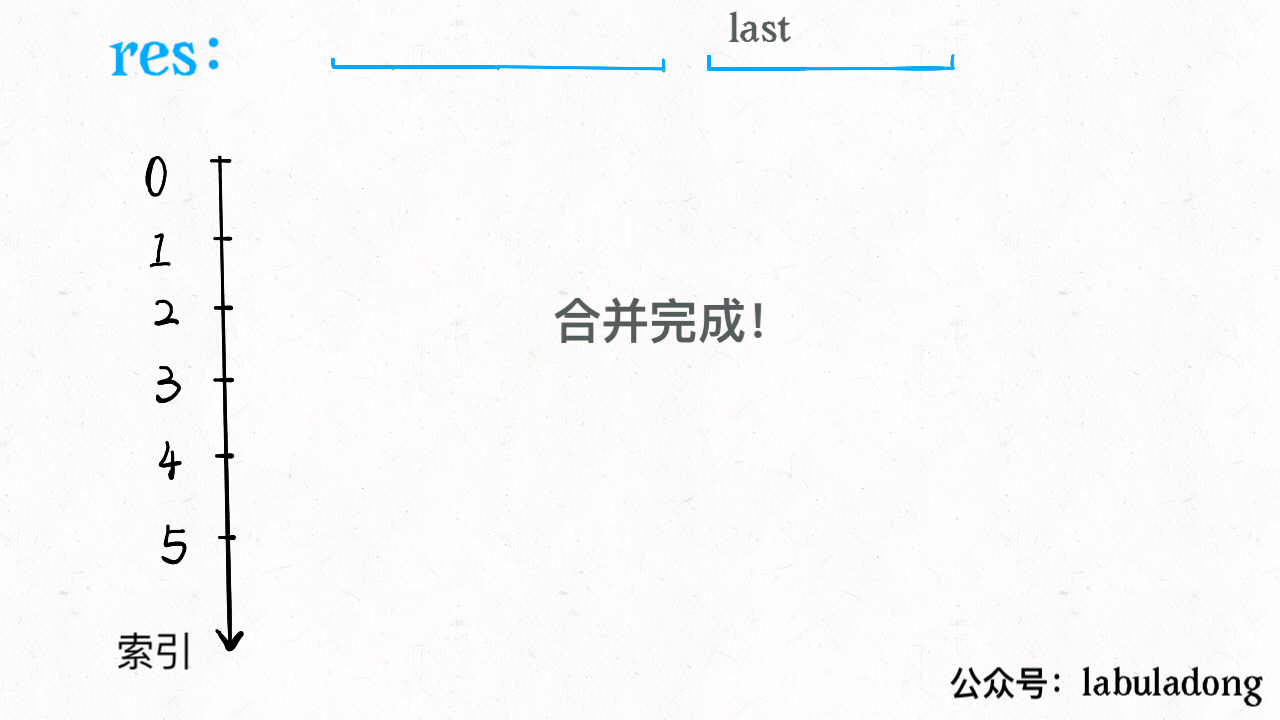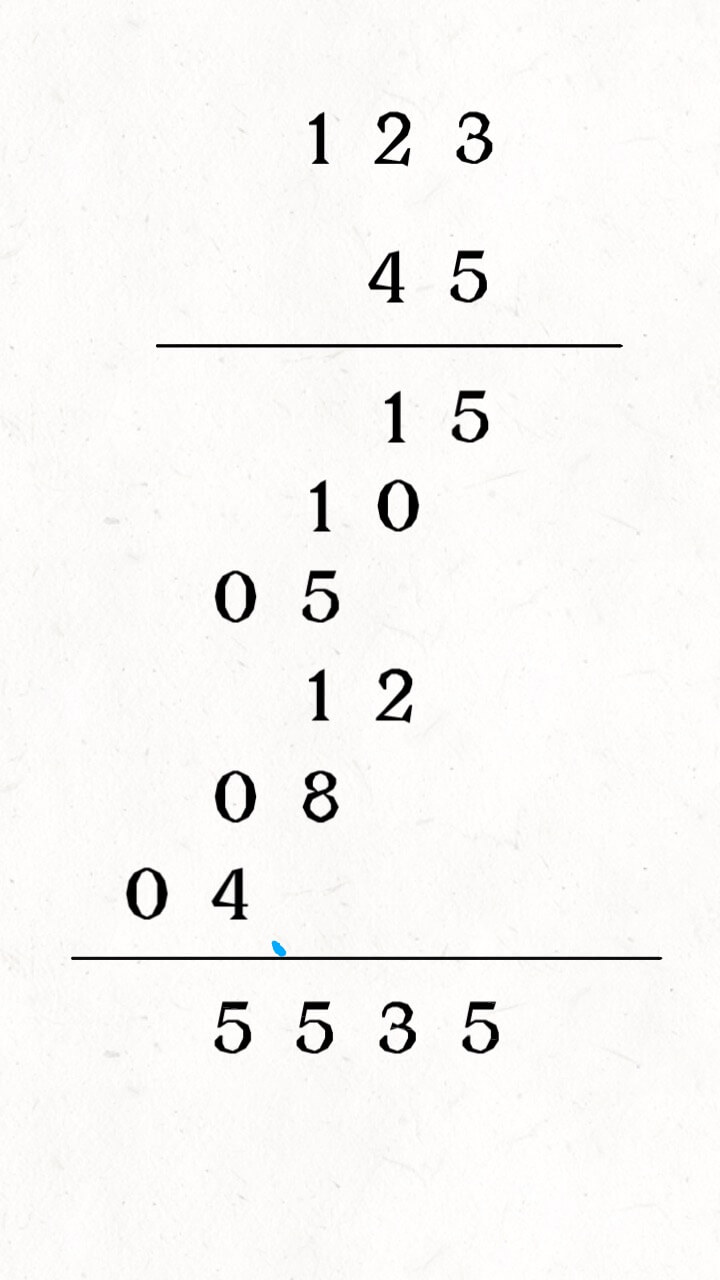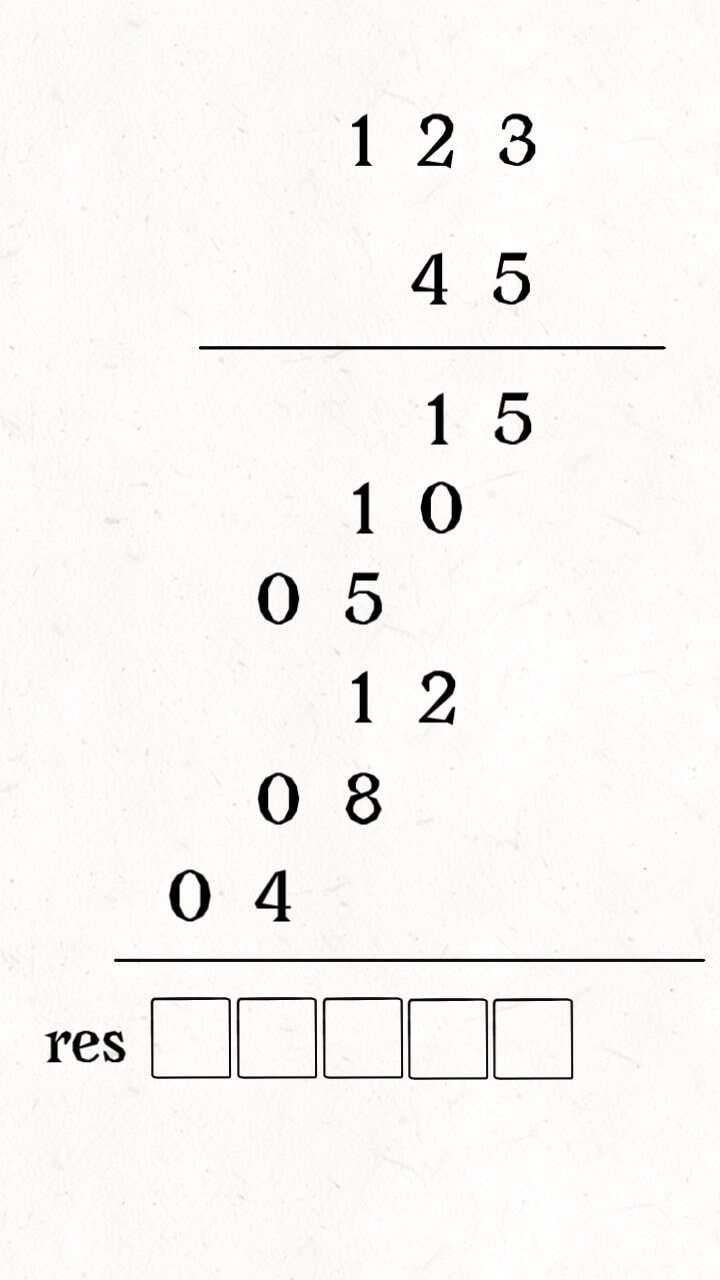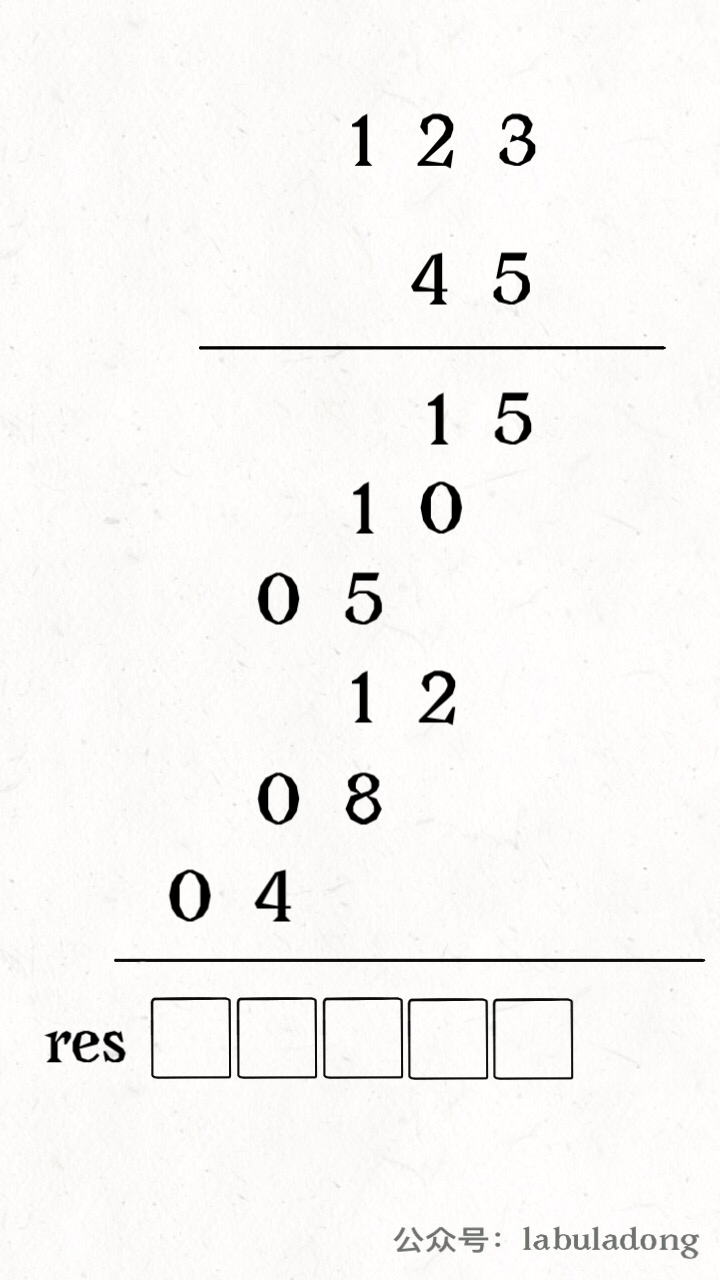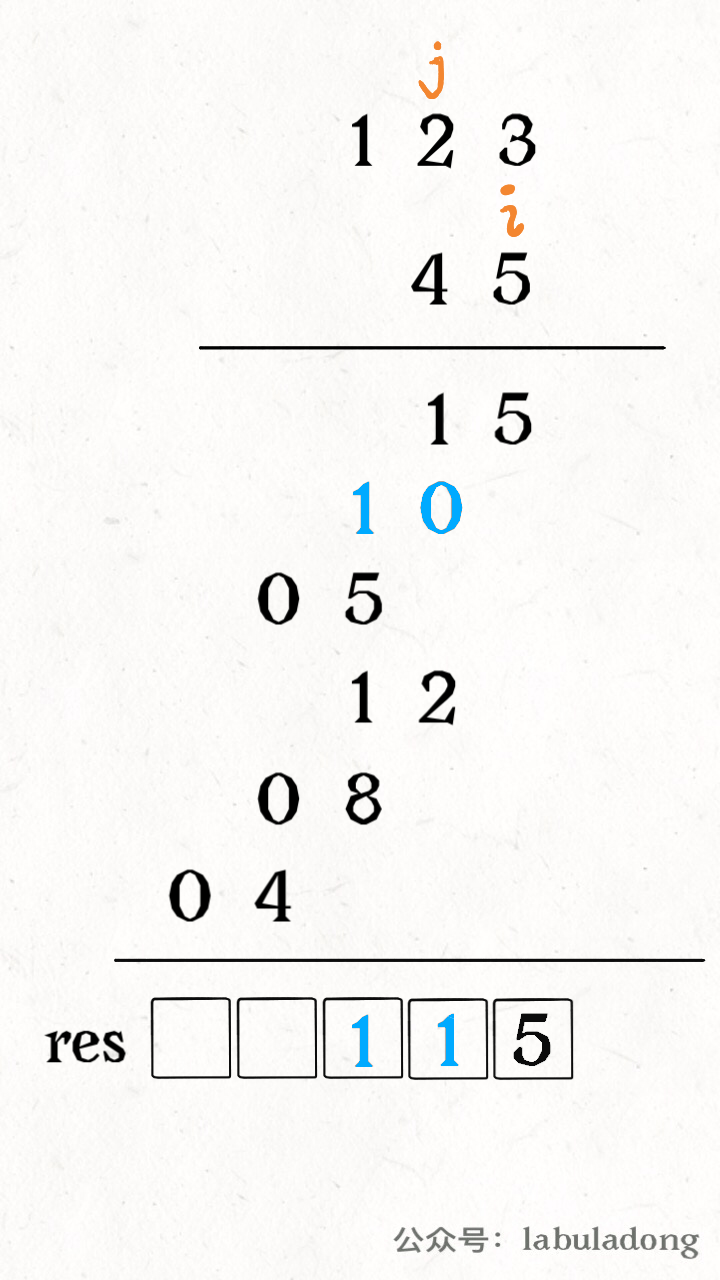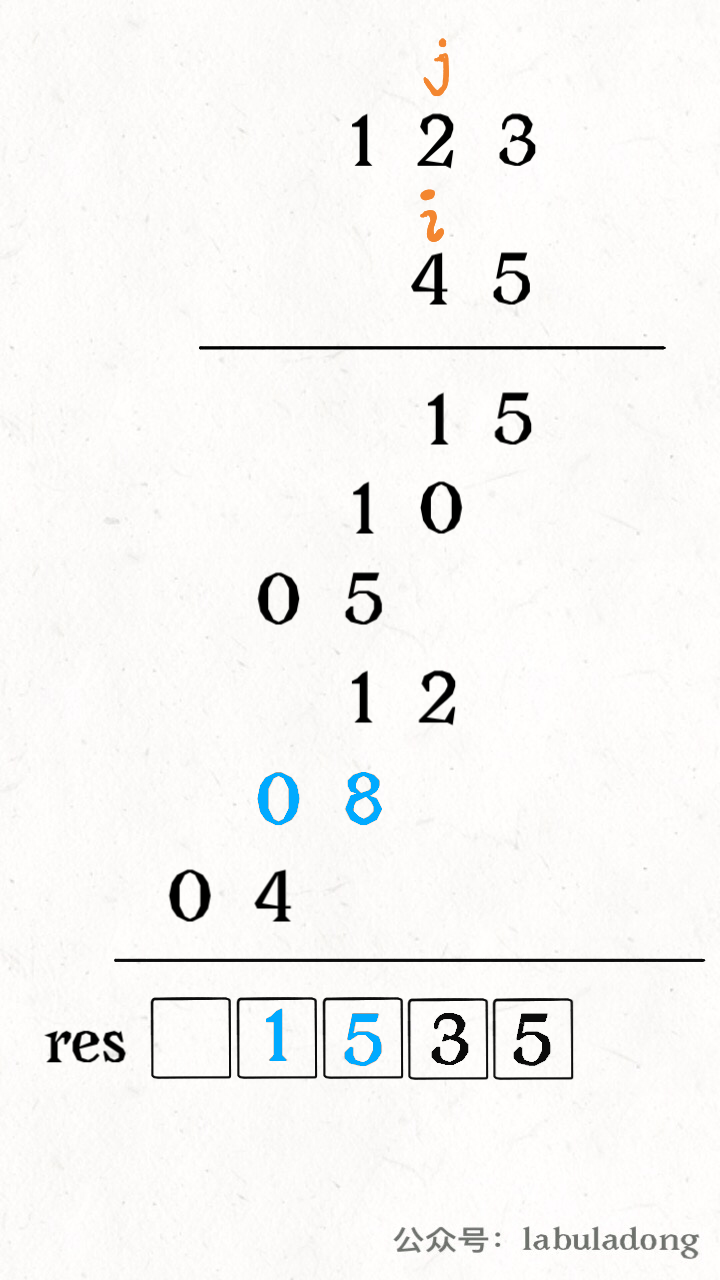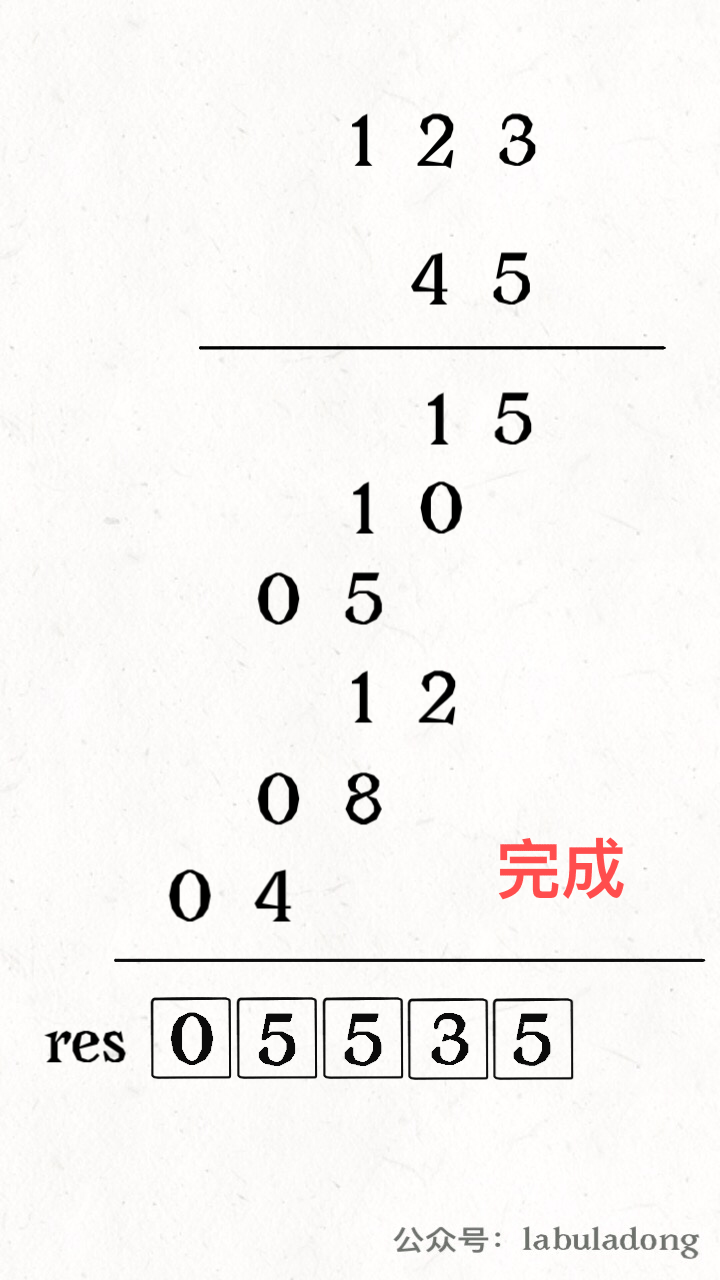for i in range(1, len(intervals)): curr = intervals[i] # res 中最后一个元素的引用 last = res[-1] if curr[0] <= last[1]: # 找到最大的 end last[1] = max(last[1], curr[1]) else: # 处理下一个待合并区间 res.append(curr) return res
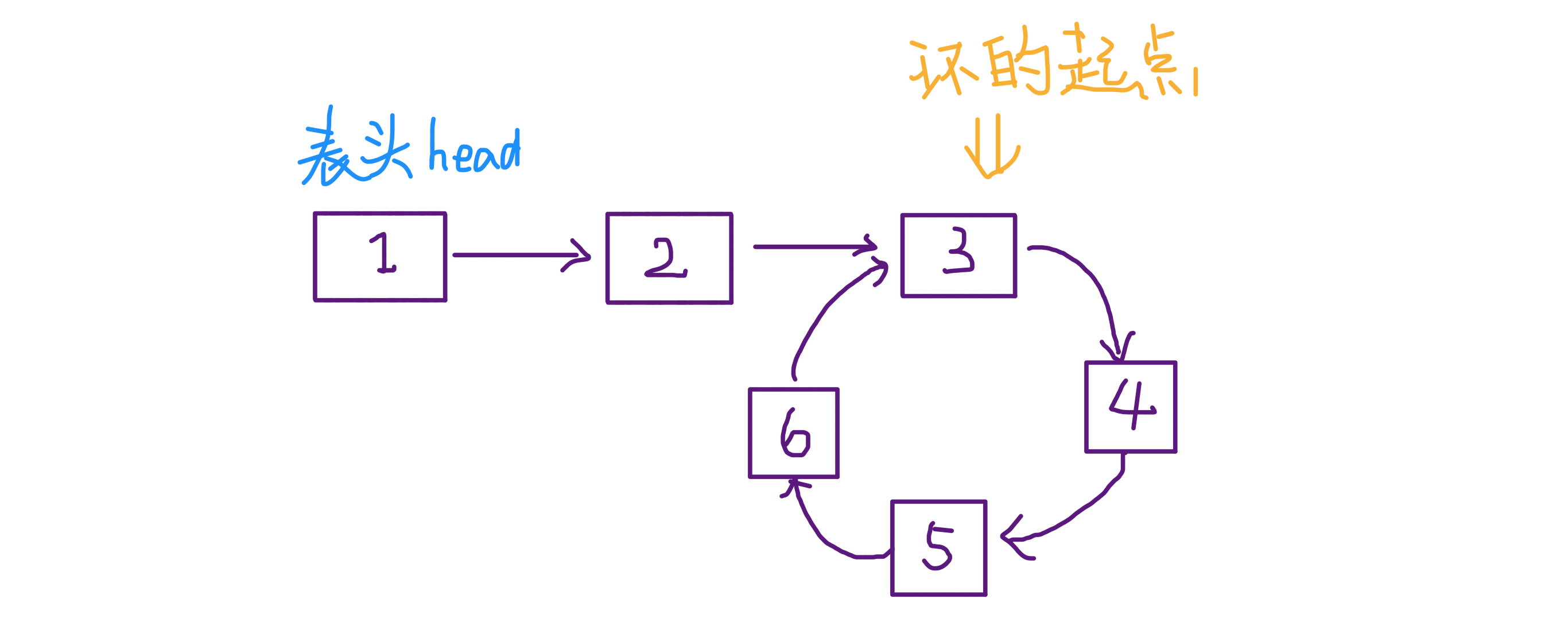
ListNode detectCycle(ListNode head){ ListNode fast, slow; fast = slow = head; while (fast != null && fast.next != null) { fast = fast.next.next; slow = slow.next; if (fast == slow) break; } // 上面的代码类似 hasCycle 函数 slow = head; while (slow != fast) { fast = fast.next; slow = slow.next; } return slow; }
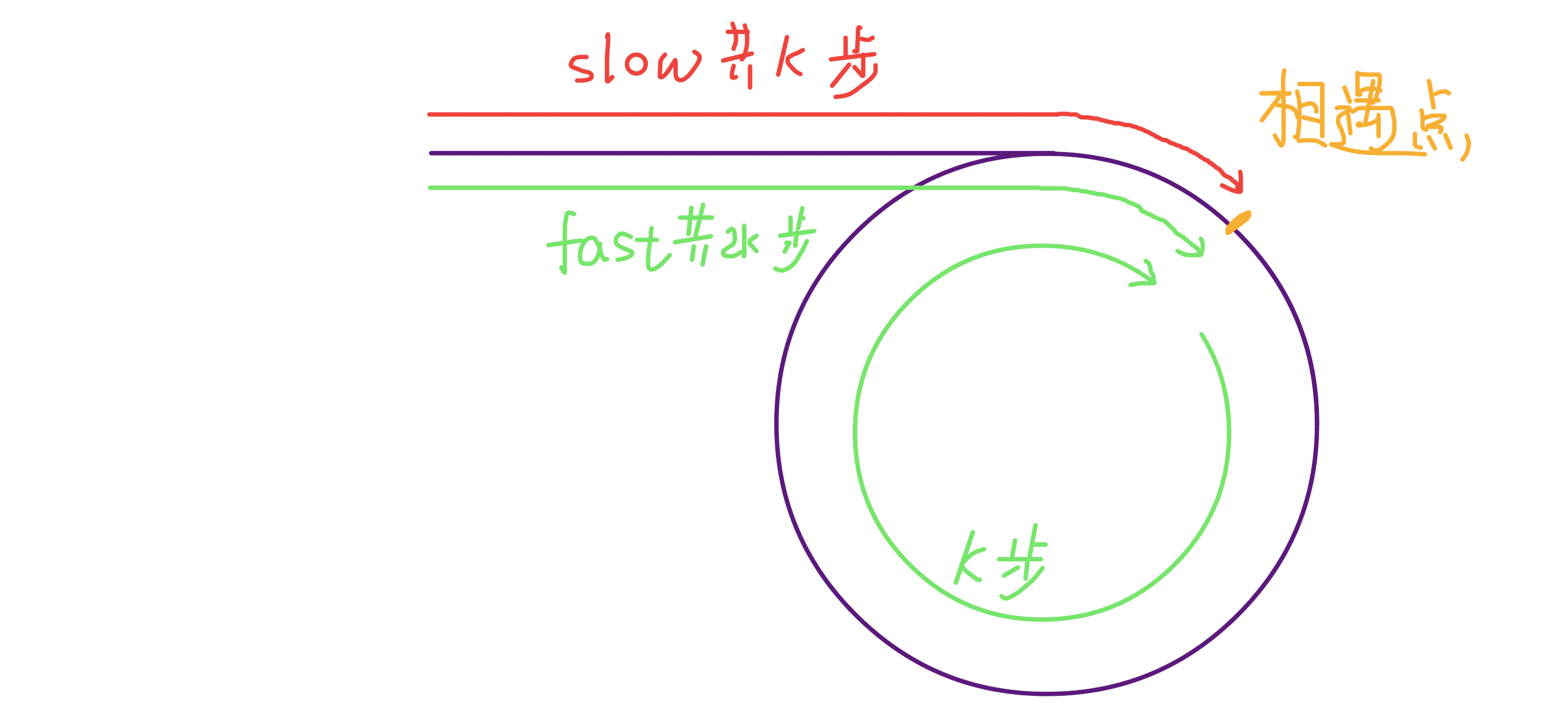
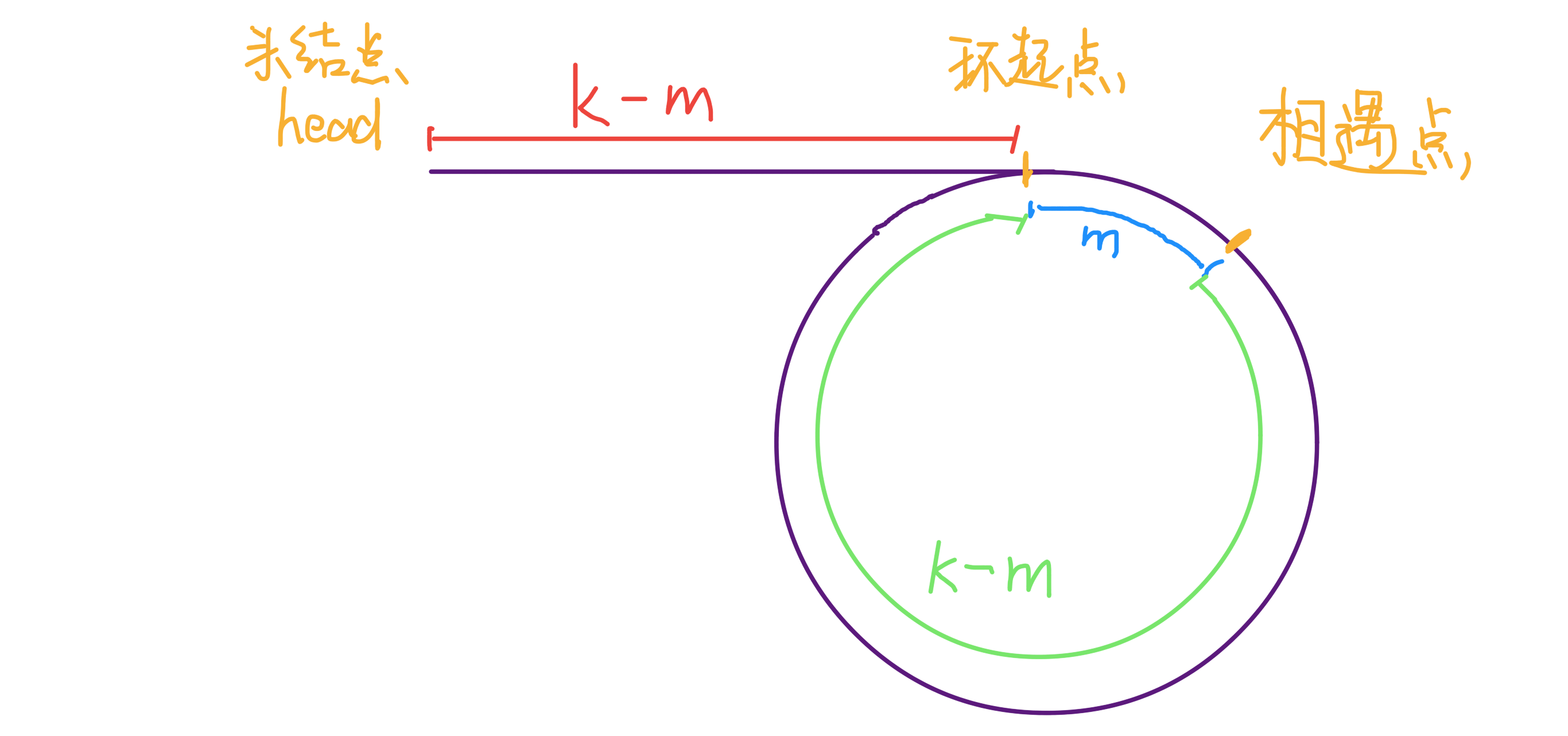
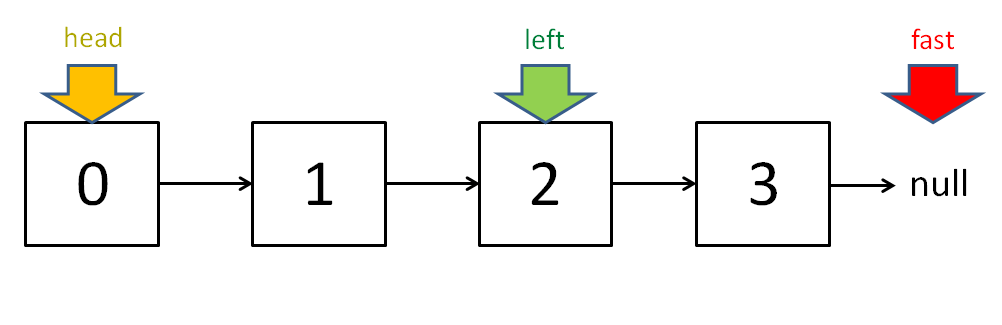
可以看到,当快慢指针相遇时,让其中任一个指针指向头节点,然后让它俩以相同速度前进,再次相遇时所在的节点位置就是环开始的位置。这是为什么呢? 第一次相遇时,假设慢指针 slow 走了 k 步,那么快指针 fast 一定走了 2k 步,也就是说比 slow 多走了 k 步(也就是环的长度)。 设相遇点距环的起点的距离为 m,那么环的起点距头结点 head 的距离为 k - m,也就是说如果从 head 前进 k - m 步就能到达环起点。 巧的是,如果从相遇点继续前进 k - m 步,也恰好到达环起点。 所以,只要我们把快慢指针中的任一个重新指向 head,然后两个指针同速前进,k - m 步后就会相遇,相遇之处就是环的起点了。 3、寻找链表的中点 类似上面的思路,我们还可以让快指针一次前进两步,慢指针一次前进一步,当快指针到达链表尽头时,慢指针就处于链表的中间位置。
string multiply(string num1, string num2){ int m = num1.size(), n = num2.size(); // 结果最多为 m + n 位数 vector<int> res(m + n, 0); // 从个位数开始逐位相乘 for (int i = m - 1; i >= 0; i--) for (int j = n - 1; j >= 0; j--) { int mul = (num1[i]-'0') * (num2[j]-'0'); // 乘积在 res 对应的索引位置 int p1 = i + j, p2 = i + j + 1; // 叠加到 res 上 int sum = mul + res[p2]; res[p2] = sum % 10; res[p1] += sum / 10; } // 结果前缀可能存的 0(未使用的位) int i = 0; while (i < res.size() && res[i] == 0) i++; // 将计算结果转化成字符串 string str; for (; i < res.size(); i++) str.push_back('0' + res[i]);
你看二叉树的递归遍历方式和链表的递归遍历方式,相似不?再看看二叉树结构和单链表结构,相似不?如果再多几条叉,N 叉树你会不会遍历? 二叉树框架可以扩展为 N 叉树的遍历框架:
1 2 3 4 5 6 7 8 9
/* 基本的 N 叉树节点 */ classTreeNode{ int val; TreeNode[] children; } voidtraverse(TreeNode root){ for (TreeNode child : root.children) traverse(child) }
N 叉树的遍历又可以扩展为图的遍历,因为图就是好几 N 叉棵树的结合体。你说图是可能出现环的?这个很好办,用个布尔数组 visited 做标记就行了,这里就不写代码了。 所谓框架,就是套路。不管增删查改,这些代码都是永远无法脱离的结构,你可以把这个结构作为大纲,根据具体问题在框架上添加代码就行了,下面会具体举例。
int ans = INT_MIN; intoneSideMax(TreeNode* root){ if (root == nullptr) return0; int left = max(0, oneSideMax(root->left)); int right = max(0, oneSideMax(root->right)); ans = max(ans, left + right + root->val); return max(left, right) + root->val; }
defcoinChange(coins: List[int], amount: int): defdp(n): if n == 0: return0 if n < 0: return-1 res = float('INF') for coin in coins: subproblem = dp(n - coin) # 子问题无解,跳过 if subproblem == -1: continue res = min(res, 1 + subproblem) return res if res != float('INF') else-1
return dp(amount)
这么多代码看不懂咋办?直接提取出框架,就能看出核心思路了:
1 2 3 4
# 不过是一个 N 叉树的遍历问题而已 defdp(n): for coin in coins: dp(n - coin)
其实很多动态规划问题就是在遍历一棵树,你如果对树的遍历操作烂熟于心,起码知道怎么把思路转化成代码,也知道如何提取别人解法的核心思路。 再看看回溯算法,前文回溯算法详解干脆直接说了,回溯算法就是个 N 叉树的前后序遍历问题,没有例外。 比如 N 皇后问题吧,主要代码如下:
for (int i = 0; i < nums.length; i++) { if (track.contains(nums[i])) continue; track.add(nums[i]); // 进入下一层决策树 backtrack(nums, track); track.removeLast(); } /* 提取出 N 叉树遍历框架 */ voidbacktrack(int[] nums, LinkedList<Integer> track){ for (int i = 0; i < nums.length; i++) { backtrack(nums, track); }
N 叉树的遍历框架,找出来了把~你说,树这种结构重不重要? 综上,对于畏惧算法的朋友来说,可以先刷树的相关题目,试着从框架上看问题,而不要纠结于细节问题。 纠结细节问题,就比如纠结 i 到底应该加到 n 还是加到 n - 1,这个数组的大小到底应该开 n 还是 n + 1 ? 从框架上看问题,就是像我们这样基于框架进行抽取和扩展,既可以在看别人解法时快速理解核心逻辑,也有助于找到我们自己写解法时的思路方向。 当然,如果细节出错,你得不到正确的答案,但是只要有框架,你再错也错不到哪去,因为你的方向是对的。 但是,你要是心中没有框架,那么你根本无法解题,给了你答案,你也不会发现这就是个树的遍历问题。 这种思维是很重要的,动态规划详解中总结的找状态转移方程的几步流程,有时候按照流程写出解法,说实话我自己都不知道为啥是对的,反正它就是对了。。。 这就是框架的力量,能够保证你在快睡着的时候,依然能写出正确的程序;就算你啥都不会,都能比别人高一个级别。
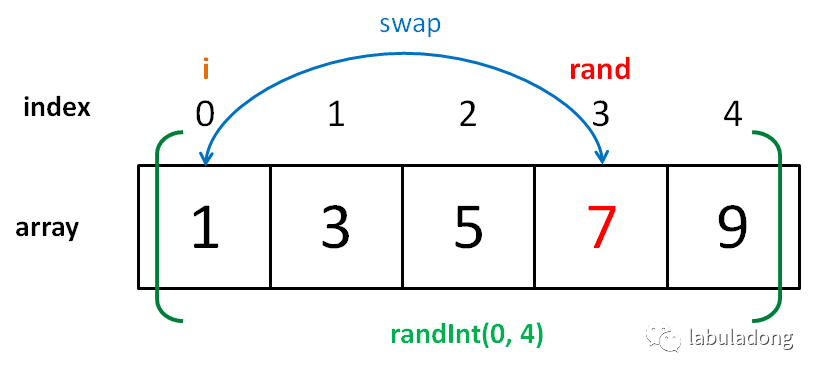
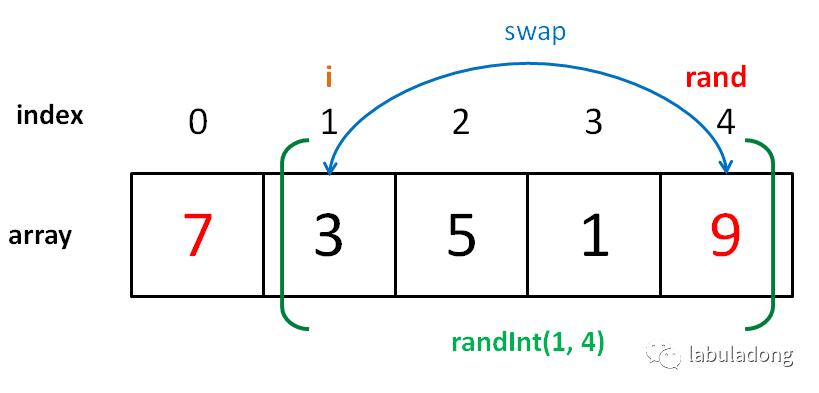
// 得到一个在闭区间 [min, max] 内的随机整数 intrandInt(int min, int max); // 第一种写法 voidshuffle(int[] arr){ int n = arr.length(); /******** 区别只有这两行 ********/ for (int i = 0 ; i < n; i++) { // 从 i 到最后随机选一个元素 int rand = randInt(i, n - 1); /*************************/ swap(arr[i], arr[rand]); } } // 第二种写法 for (int i = 0 ; i < n - 1; i++) int rand = randInt(i, n - 1); // 第三种写法 for (int i = n - 1 ; i >= 0; i--) int rand = randInt(0, i); // 第四种写法 for (int i = n - 1 ; i > 0; i--) int rand = randInt(0, i);
分析洗牌算法正确性的准则:产生的结果必须有 n! 种可能,否则就是错误的。这个很好解释,因为一个长度为 n 的数组的全排列就有 n! 种,也就是说打乱结果总共有 n! 种。算法必须能够反映这个事实,才是正确的。 我们先用这个准则分析一下第一种写法的正确性:
1 2 3 4 5 6 7 8 9
// 假设传入这样一个 arr int[] arr = {1,3,5,7,9}; voidshuffle(int[] arr){ int n = arr.length(); // 5 for (int i = 0 ; i < n; i++) { int rand = randInt(i, n - 1); swap(arr[i], arr[rand]); } }
voidshuffle(int[] arr){ int n = arr.length(); for (int i = 0 ; i < n; i++) { // 每次都从闭区间 [0, n-1] // 中随机选取元素进行交换 int rand = randInt(0, n - 1); swap(arr[i], arr[rand]); } }
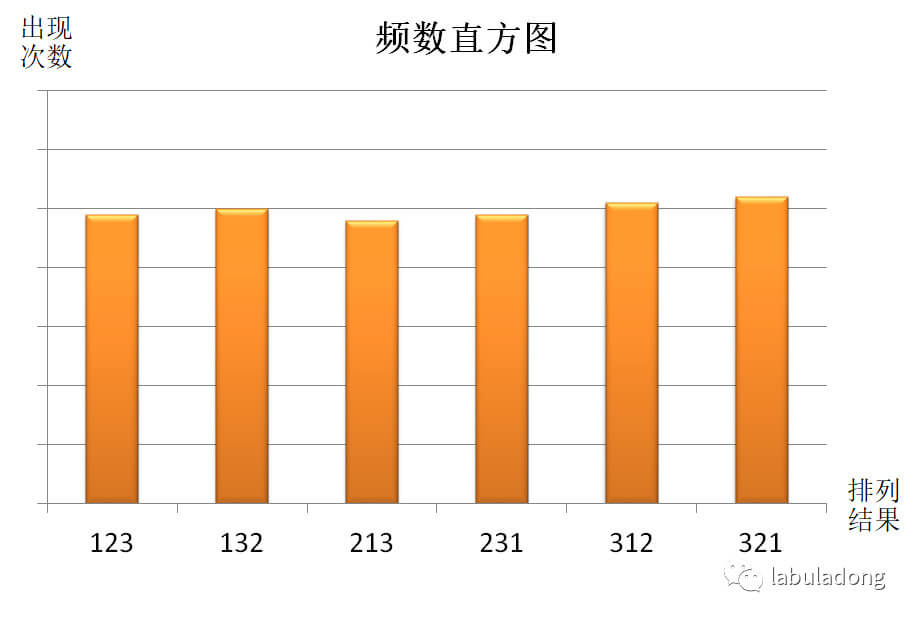
voidshuffle(int[] arr); // 蒙特卡罗方法 int N = 1000000; int[] arr = {1,0,0,0,0}; int[] count = newint[arr.length]; for (int i = 0; i < N; i++) { shuffle(arr); // 打乱 arr for (int j = 0; j < arr.length; j++) if (arr[j] == 1) { count[j]++; break; } } for (int feq : count) print(feq / N + " "); // 频率
这种思路也是可行的,而且避免了阶乘级的空间复杂度,但是多了嵌套 for 循环,时间复杂度高一点。不过由于我们的测试数据量不会有多大,这些问题都可以忽略。 另外,细心的读者可能发现一个问题,上述两种思路声明 arr 的位置不同,一个在 for 循环里,一个在 for 循环之外。其实效果都是一样的,因为我们的算法总要打乱 arr,所以 arr 的顺序并不重要,只要元素不变就行。
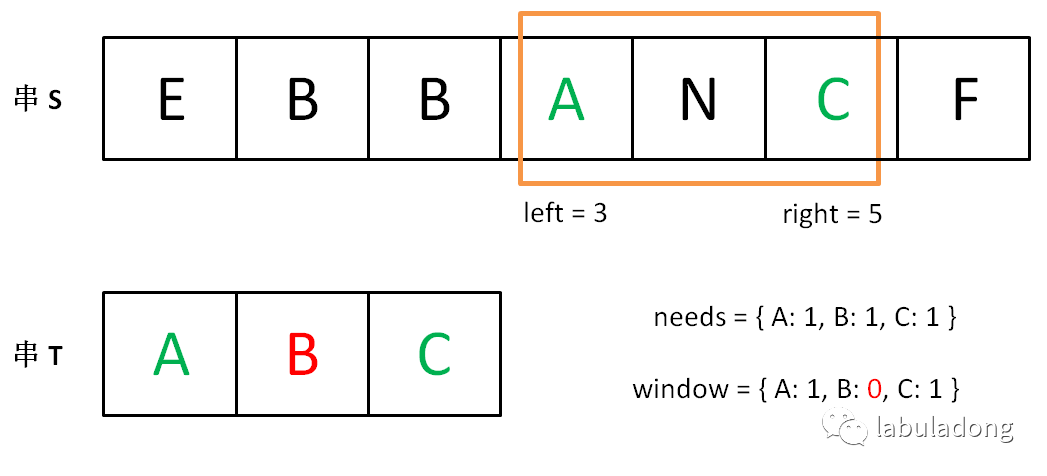
之后重复上述过程,先移动 right,再移动 left…… 直到 right 指针到达字符串 S 的末端,算法结束。 如果你能够理解上述过程,恭喜,你已经完全掌握了滑动窗口算法思想。至于如何具体到问题,如何得出此题的答案,都是编程问题,等会提供一套模板,理解一下就会了。 上述过程可以简单地写出如下伪码框架:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
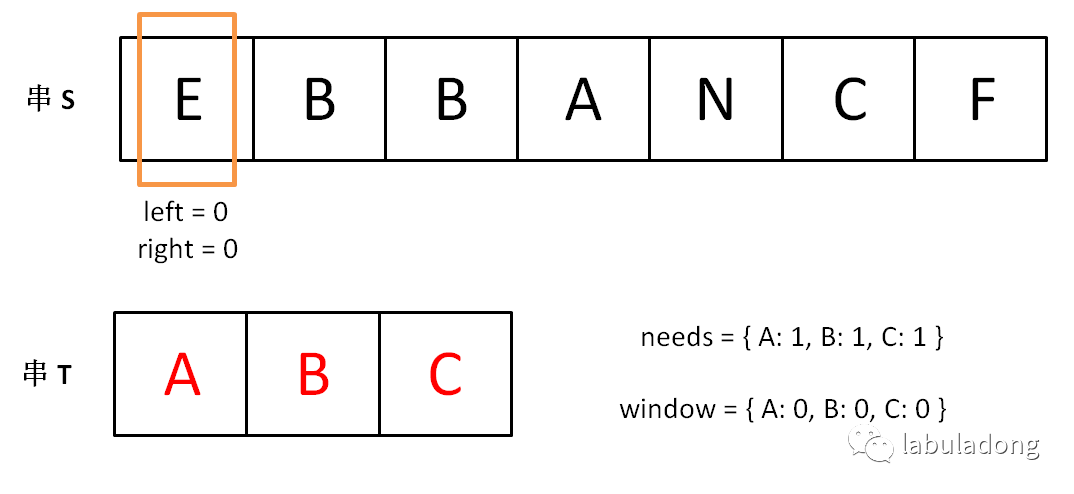
string s, t; // 在 s 中寻找 t 的「最小覆盖子串」 int left = 0, right = 0; string res = s; while(right < s.size()) { window.add(s[right]); right++; // 如果符合要求,移动 left 缩小窗口 while (window 符合要求) { // 如果这个窗口的子串更短,则更新 res res = minLen(res, window); window.remove(s[left]); left++; } } return res;
如果上述代码你也能够理解,那么你离解题更近了一步。现在就剩下一个比较棘手的问题:如何判断 window 即子串 s[left…right] 是否符合要求,是否包含 t 的所有字符呢? 可以用两个哈希表当作计数器解决。用一个哈希表 needs 记录字符串 t 中包含的字符及出现次数,用另一个哈希表 window 记录当前「窗口」中包含的字符及出现的次数,如果 window 包含所有 needs 中的键,且这些键对应的值都大于等于 needs 中的值,那么就可以知道当前「窗口」符合要求了,可以开始移动 left 指针了。 现在将上面的框架继续细化:
stringminWindow(string s, string t){ // 记录最短子串的开始位置和长度 int start = 0, minLen = INT_MAX; int left = 0, right = 0;
unordered_map<char, int> window; unordered_map<char, int> needs; for (char c : t) needs[c]++;
int match = 0;
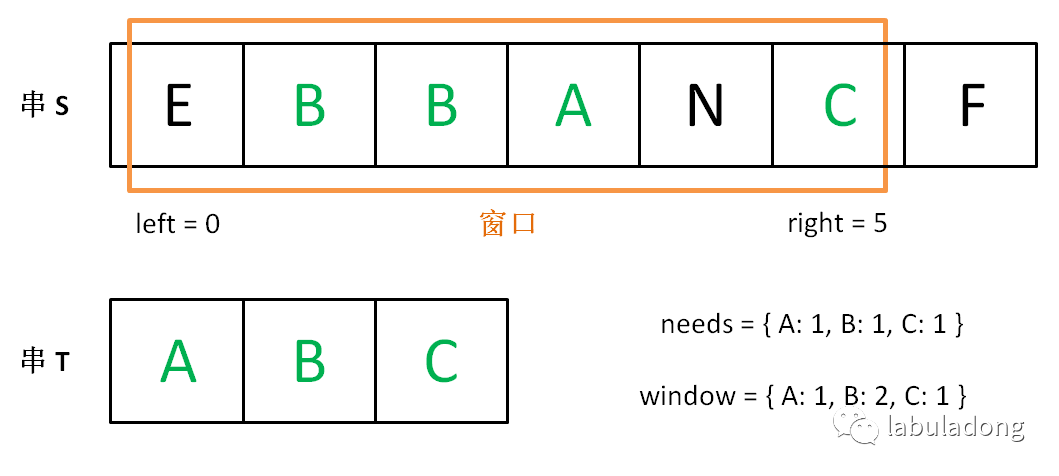
while (right < s.size()) { char c1 = s[right]; if (needs.count(c1)) { window[c1]++; if (window[c1] == needs[c1]) match++; } right++;
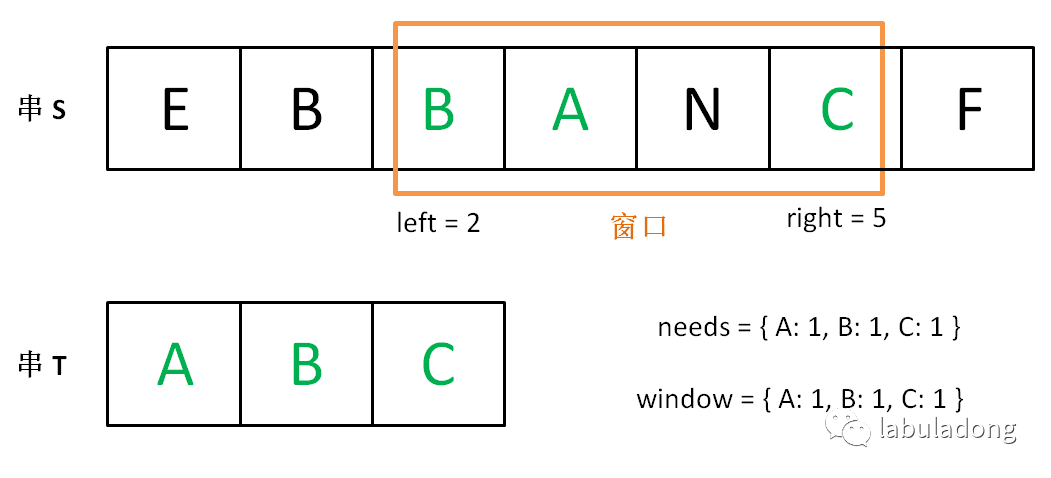
while (match == needs.size()) { if (right - left < minLen) { // 更新最小子串的位置和长度 start = left; minLen = right - left; } char c2 = s[left]; if (needs.count(c2)) { window[c2]--; if (window[c2] < needs[c2]) match--; } left++; } } return minLen == INT_MAX ? "" : s.substr(start, minLen); }
如果直接甩给你这么一大段代码,我想你的心态是爆炸的,但是通过之前的步步跟进,你是否能够理解这个算法的内在逻辑呢?你是否能清晰看出该算法的结构呢? 这个算法的时间复杂度是 O(M + N),M 和 N 分别是字符串 S 和 T 的长度。因为我们先用 for 循环遍历了字符串 T 来初始化 needs,时间 O(N),之后的两个 while 循环最多执行 2M 次,时间 O(M)。 读者也许认为嵌套的 while 循环复杂度应该是平方级,但是你这样想,while 执行的次数就是双指针 left 和 right 走的总路程,最多是 2M 嘛。
二、找到字符串中所有字母异位词
这道题的难度是 Easy,但是评论区点赞最多的一条是这样: How can this problem be marked as easy??? 实际上,这个 Easy 是属于了解双指针技巧的人的,只要把上一道题的代码改中更新 res 部分的代码稍加修改就成了这道题的解:
vector<int> findAnagrams(string s, string t){ // 用数组记录答案 vector<int> res; int left = 0, right = 0; unordered_map<char, int> needs; unordered_map<char, int> window; for (char c : t) needs[c]++; int match = 0;
while (right < s.size()) { char c1 = s[right]; if (needs.count(c1)) { window[c1]++; if (window[c1] == needs[c1]) match++; } right++; while (match == needs.size()) { // 如果 window 的大小合适 // 就把起始索引 left 加入结果 if (right - left == t.size()) { res.push_back(left); } char c2 = s[left]; if (needs.count(c2)) { window[c2]--; if (window[c2] < needs[c2]) match--; } left++; } } return res; }
因为这道题和上一道的场景类似,也需要 window 中包含串 t 的所有字符,但上一道题要找长度最短的子串,这道题要找长度相同的子串,也就是「字母异位词」嘛。
三、无重复字符的最长子串
遇到子串问题,首先想到的就是滑动窗口技巧。 类似之前的思路,使用 window 作为计数器记录窗口中的字符出现次数,然后先向右移动 right,当 window 中出现重复字符时,开始移动 left 缩小窗口,如此往复:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
intlengthOfLongestSubstring(string s){ int left = 0, right = 0; unordered_map<char, int> window; int res = 0; // 记录最长长度 while (right < s.size()) { char c1 = s[right]; window[c1]++; right++; // 如果 window 中出现重复字符 // 开始移动 left 缩小窗口 while (window[c1] > 1) { char c2 = s[left]; window[c2]--; left++; } res = max(res, right - left); } return res; }
需要注意的是,因为我们要求的是最长子串,所以需要在每次移动 right 增大窗口时更新 res,而不是像之前的题目在移动 left 缩小窗口时更新 res。
最后总结
通过上面三道题,我们可以总结出滑动窗口算法的抽象思想:
1 2 3 4 5 6 7 8 9 10
int left = 0, right = 0; while (right < s.size()) { window.add(s[right]); right++;
while (valid) { window.remove(s[left]); left++; } }
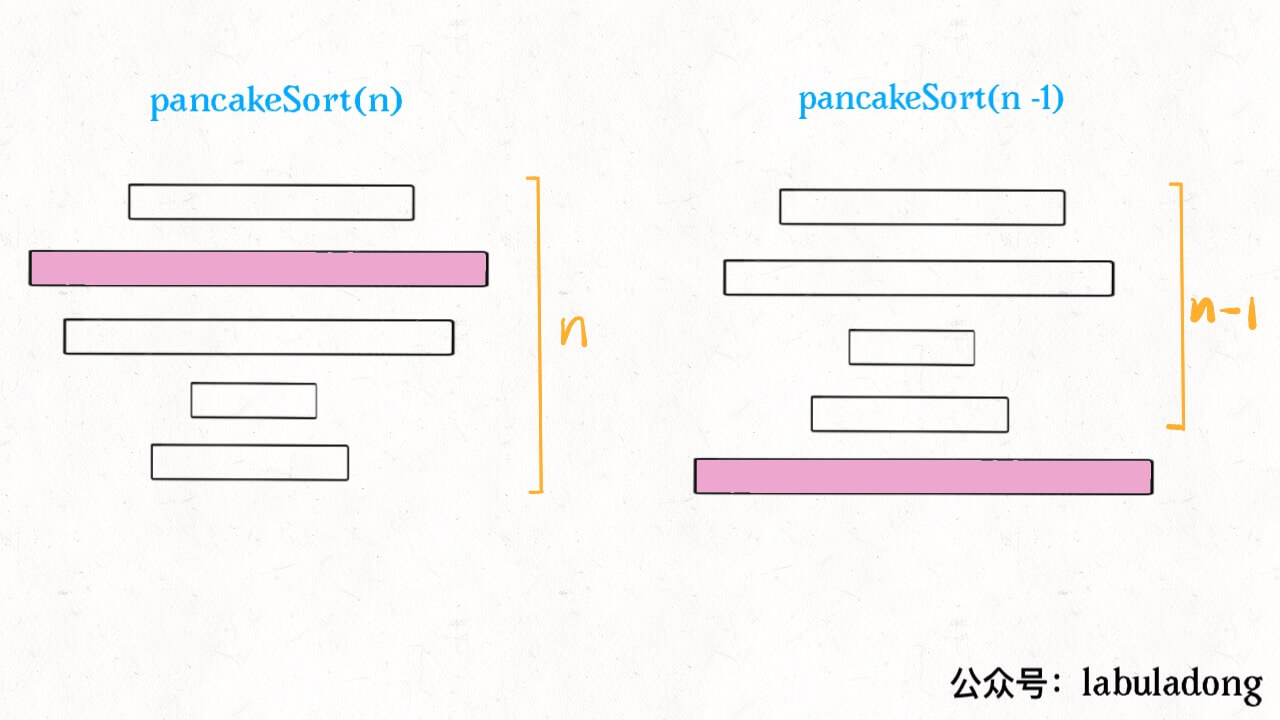
// 记录反转操作序列 LinkedList<Integer> res = new LinkedList<>(); List<Integer> pancakeSort(int[] cakes){ sort(cakes, cakes.length); return res; } voidsort(int[] cakes, int n){ // base case if (n == 1) return;
// 寻找最大饼的索引 int maxCake = 0; int maxCakeIndex = 0; for (int i = 0; i < n; i++) if (cakes[i] > maxCake) { maxCakeIndex = i; maxCake = cakes[i]; }
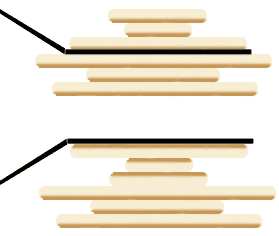
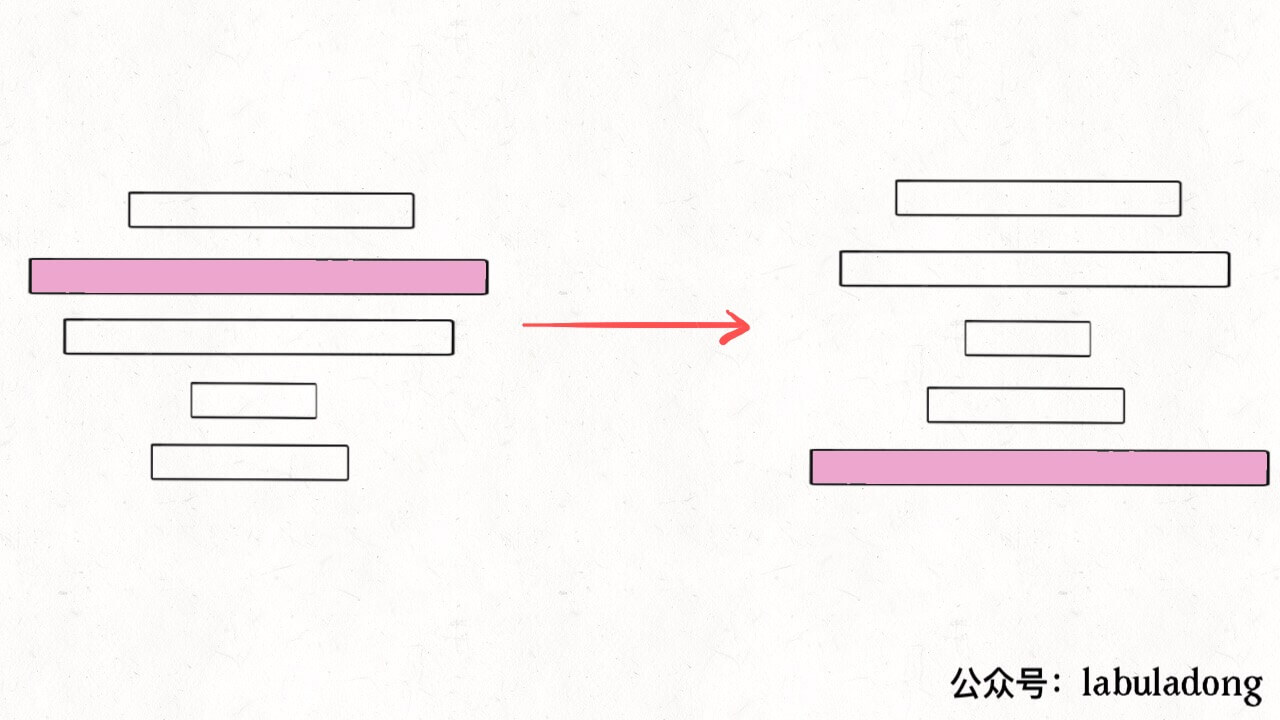
// 第一次翻转,将最大饼翻到最上面 reverse(cakes, 0, maxCakeIndex); res.add(maxCakeIndex + 1); // 第二次翻转,将最大饼翻到最下面 reverse(cakes, 0, n - 1); res.add(n); // 递归调用 sort(cakes, n - 1); } voidreverse(int[] arr, int i, int j){ while (i < j) { int temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; i++; j--; } }
通过刚才的详细解释,这段代码应该是很清晰了。 算法的时间复杂度很容易计算,因为递归调用的次数是 n,每次递归调用都需要一次 for 循环,时间复杂度是 O(n),所以总的复杂度是 O(n^2)。 最后,我们可以思考一个问题:按照我们这个思路,得出的操作序列长度应该为 2(n - 1),因为每次递归都要进行 2 次翻转并记录操作,总共有 n 层递归,但由于 base case 直接返回结果,不进行翻转,所以最终的操作序列长度应该是固定的 2(n - 1)。 显然,这个结果不是最优的(最短的),比如说一堆煎饼 [3,2,4,1],我们的算法得到的翻转序列是 [3,4,2,3,1,2],但是最快捷的翻转方法应该是 [2,3,4]: 初始状态 :[3,2,4,1] 翻前 2 个:[2,3,4,1] 翻前 3 个:[4,3,2,1] 翻前 4 个:[1,2,3,4] 如果要求你的算法计算排序烧饼的最短操作序列,你该如何计算呢?或者说,解决这种求最优解法的问题,核心思路什么,一定需要使用什么算法技巧呢? 不妨分享一下你的思考。