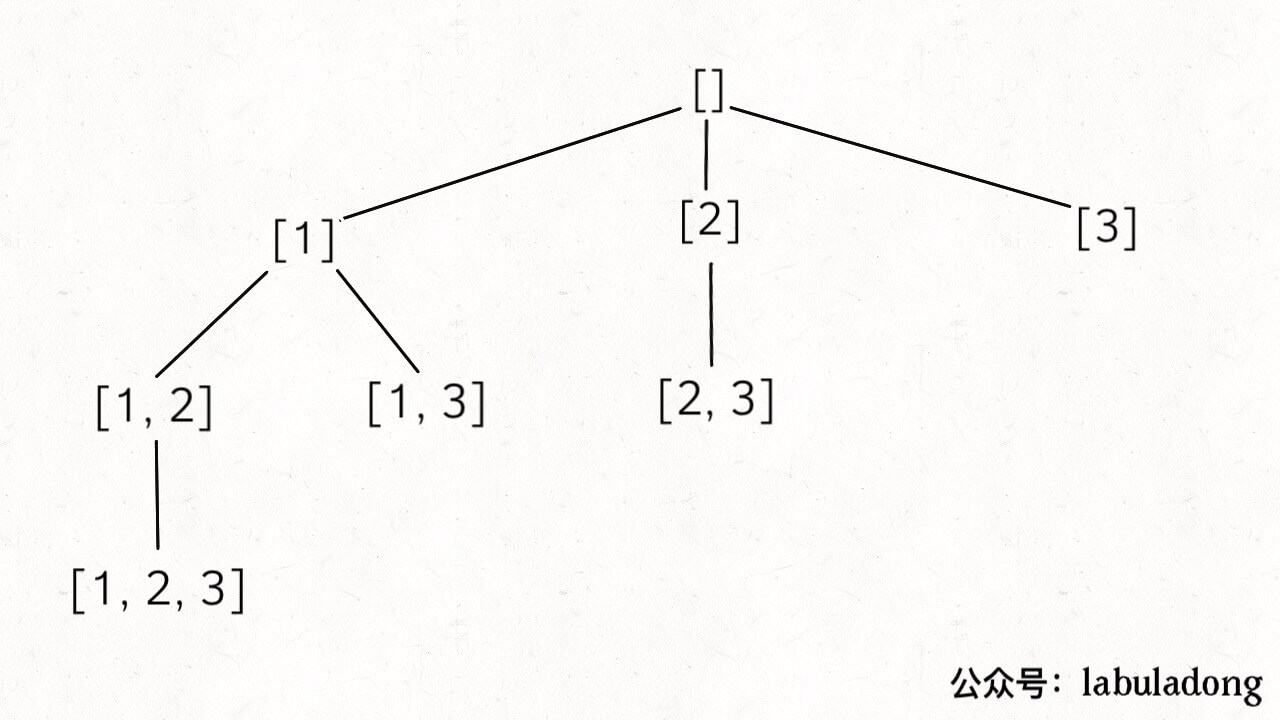
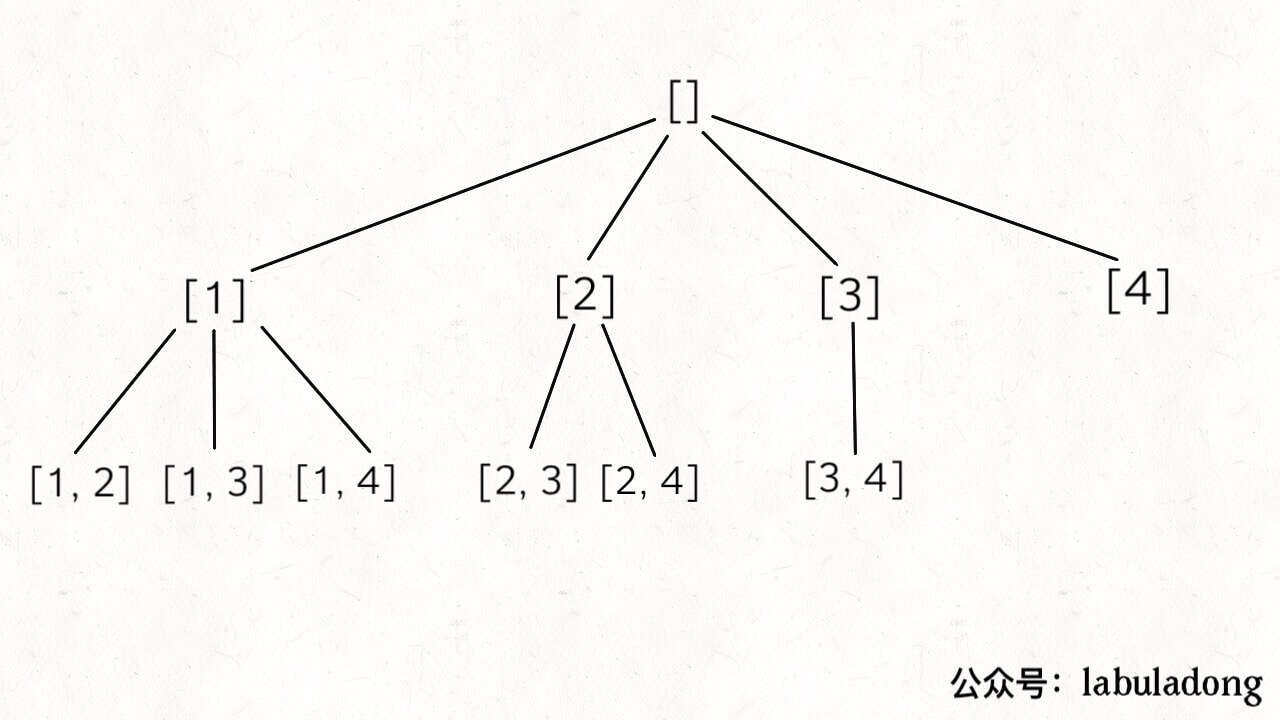
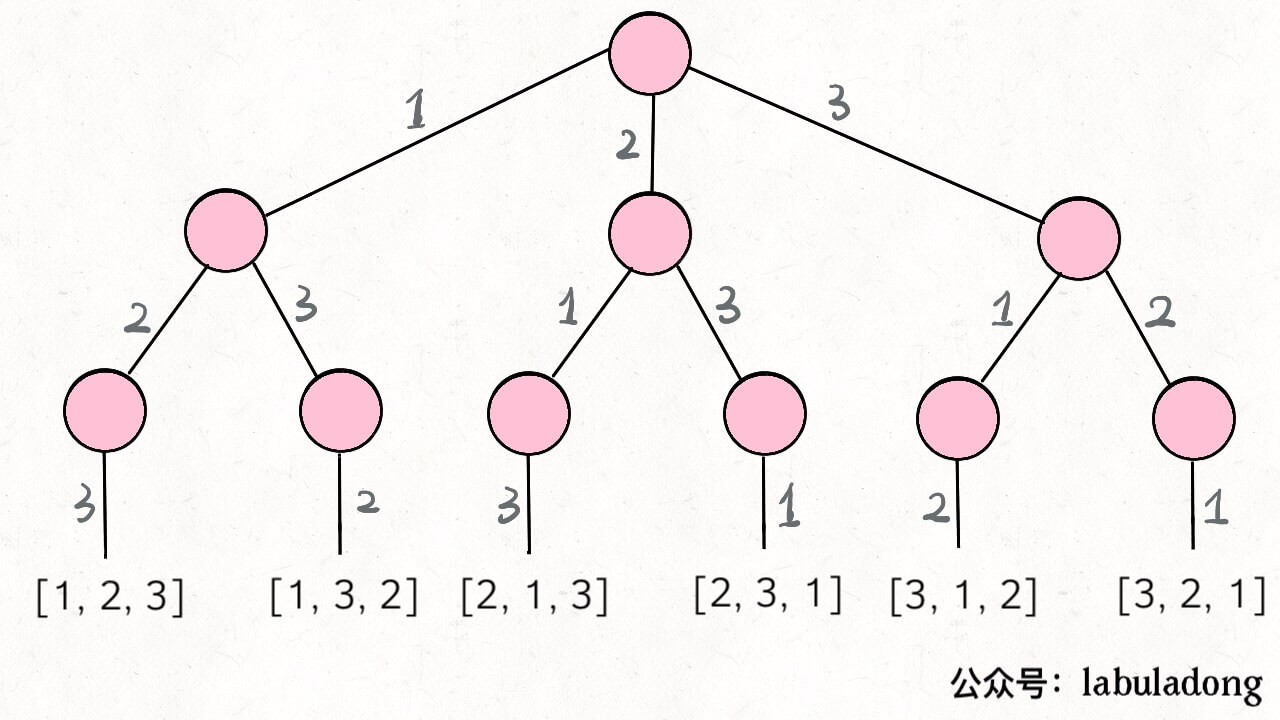
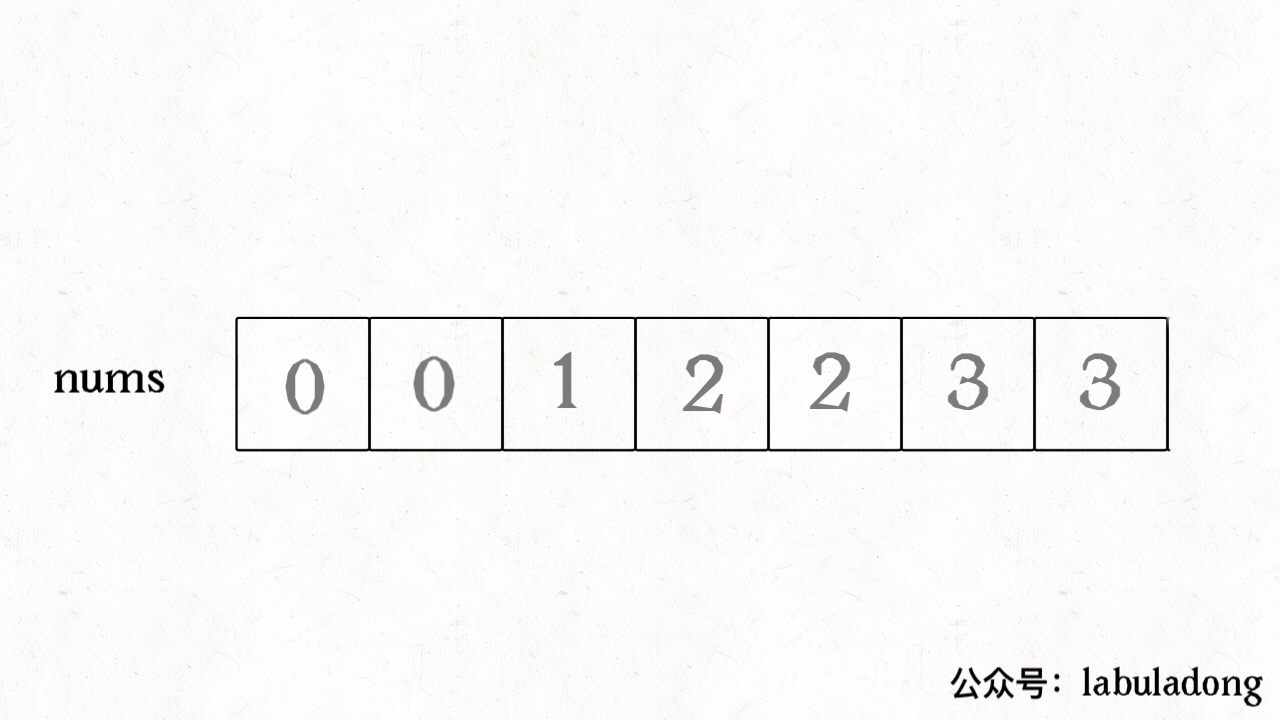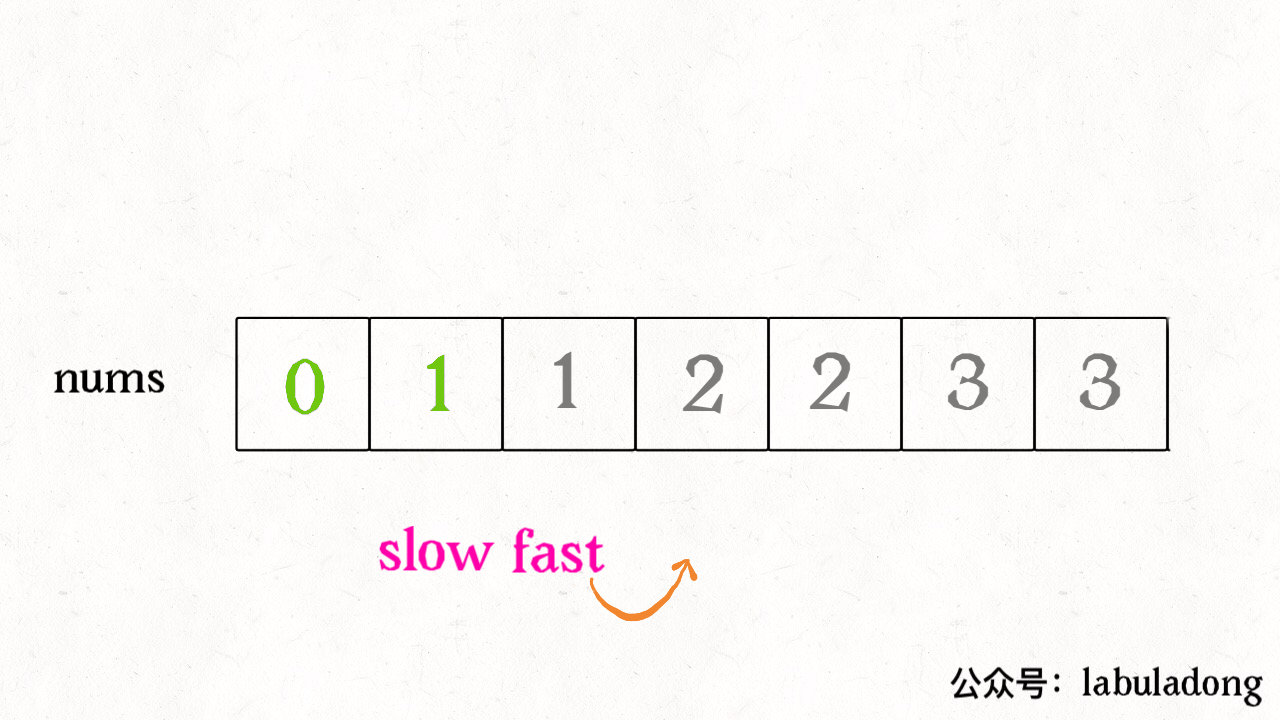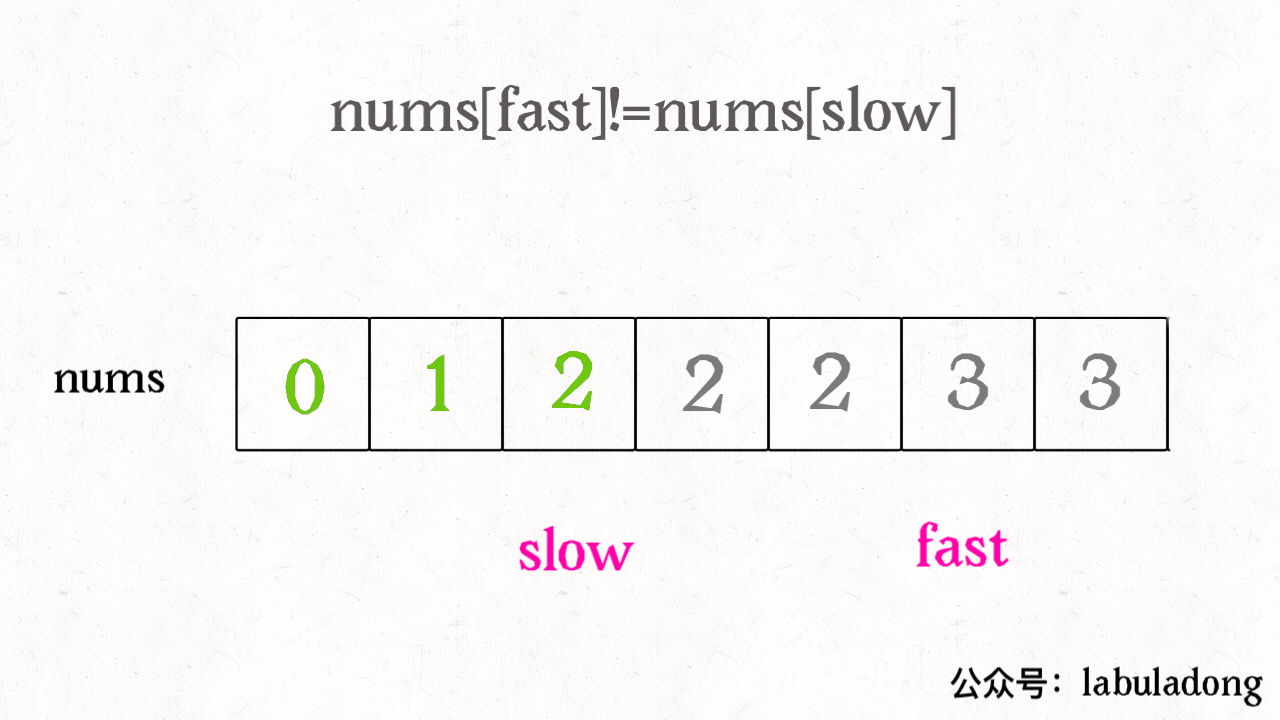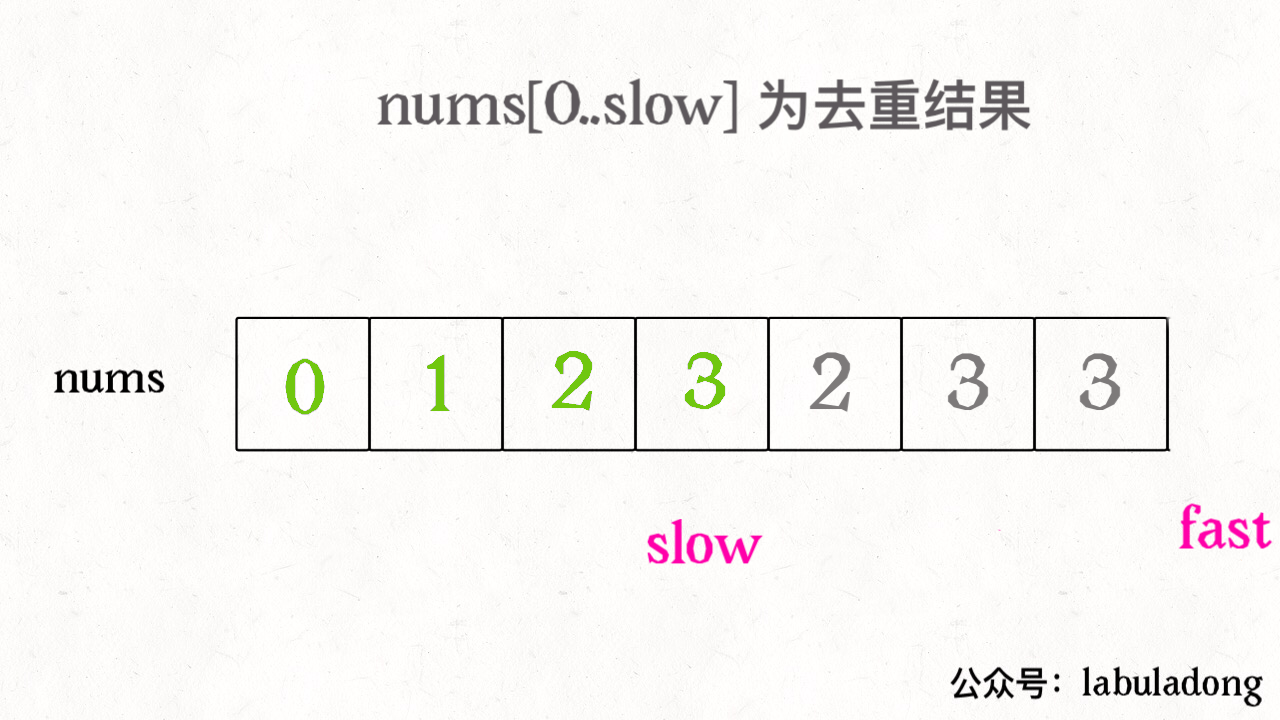vector<vector<int>> subsets(vector<int>& nums){ // base case,返回一个空集 if (nums.empty()) return {{}}; // 把最后一个元素拿出来 int n = nums.back(); nums.pop_back(); // 先递归算出前面元素的所有子集 vector<vector<int>> res = subsets(nums); int size = res.size(); for (int i = 0; i < size; i++) { // 然后在之前的结果之上追加 res.push_back(res[i]); res.back().push_back(n); } return res; }
这个问题的时间复杂度计算比较容易坑人。我们之前说的计算递归算法时间复杂度的方法,是找到递归深度,然后乘以每次递归中迭代的次数。对于这个问题,递归深度显然是 N,但我们发现每次递归 for 循环的迭代次数取决于 res 的长度,并不是固定的。 根据刚才的思路,res 的长度应该是每次递归都翻倍,所以说总的迭代次数应该是 2^N。或者不用这么麻烦,你想想一个大小为 N 的集合的子集总共有几个?2^N 个对吧,所以说至少要对 res 添加 2^N 次元素。 那么算法的时间复杂度就是 O(2^N) 吗?还是不对,2^N 个子集是 push_back 添加进 res 的,所以要考虑 push_back 这个操作的效率:
1 2 3 4
for (int i = 0; i < size; i++) { res.push_back(res[i]); // O(N) res.back().push_back(n); // O(1) }
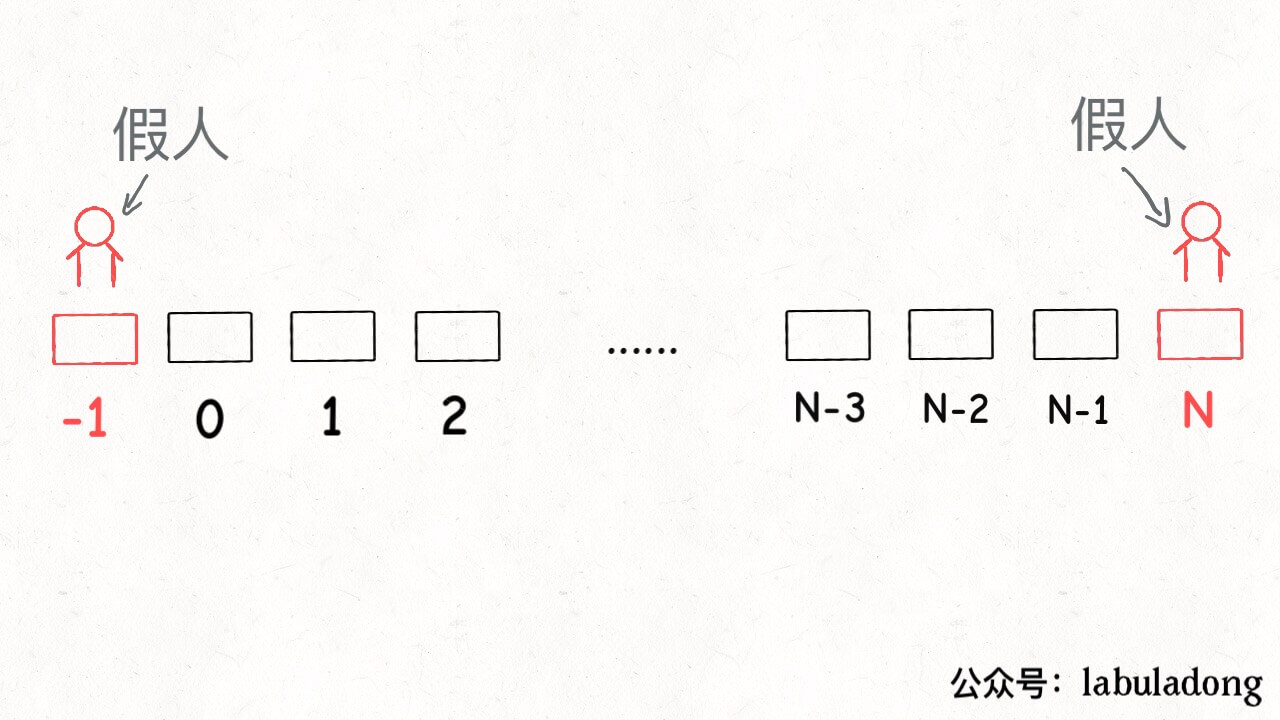
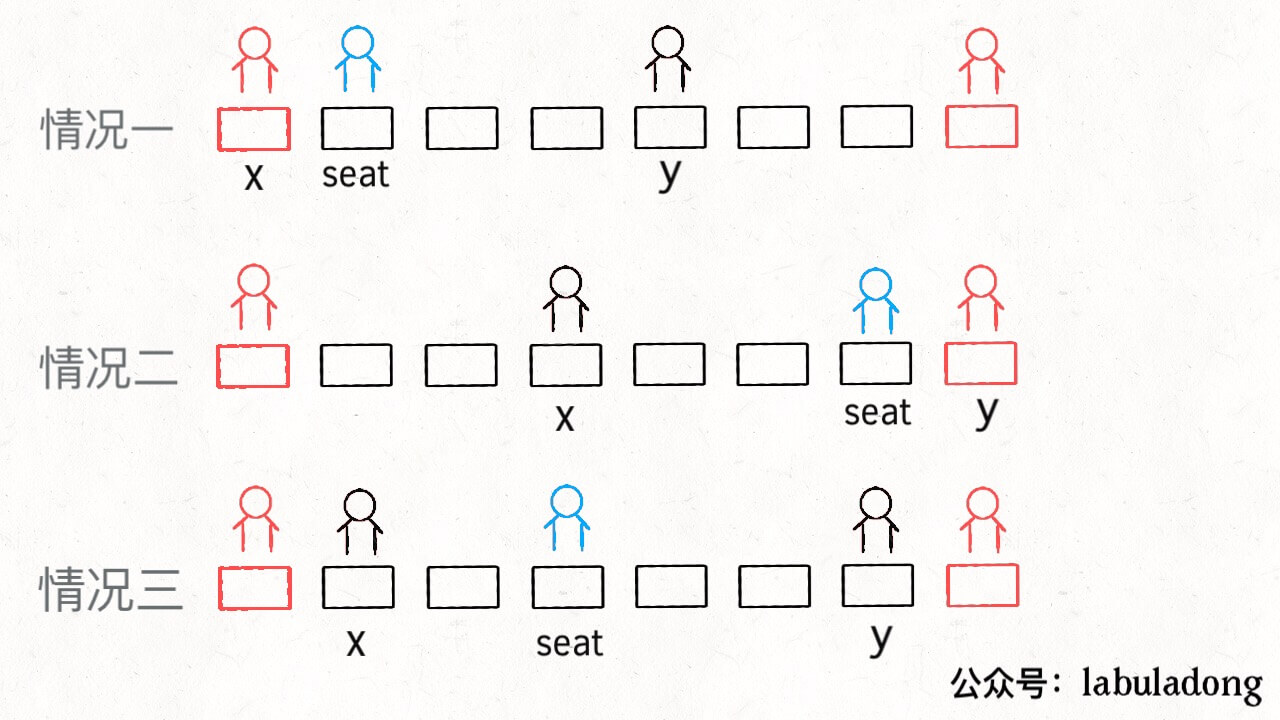
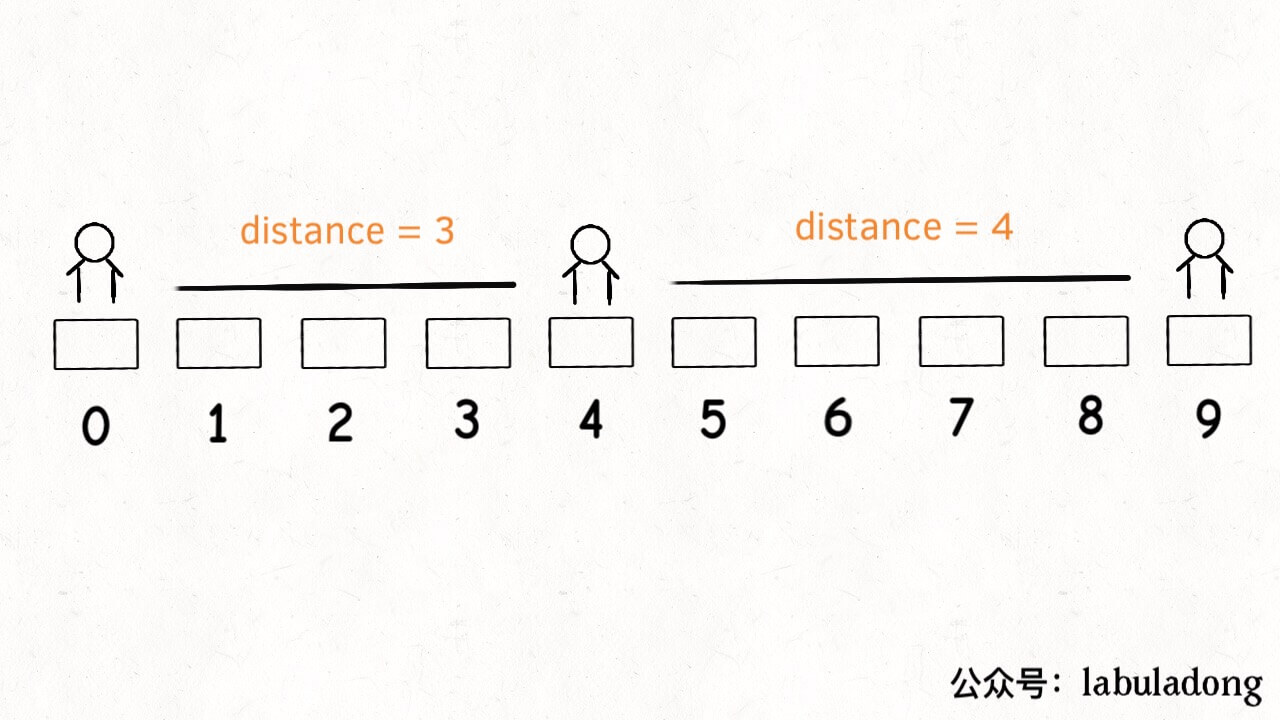
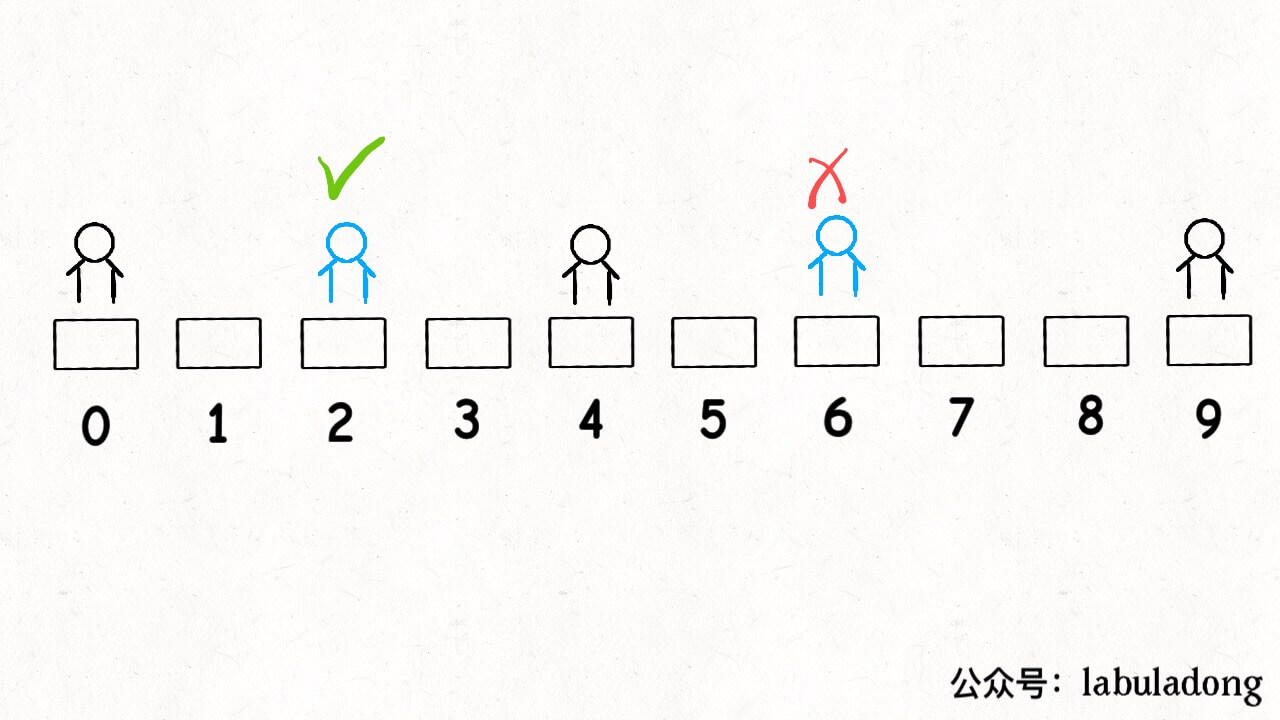
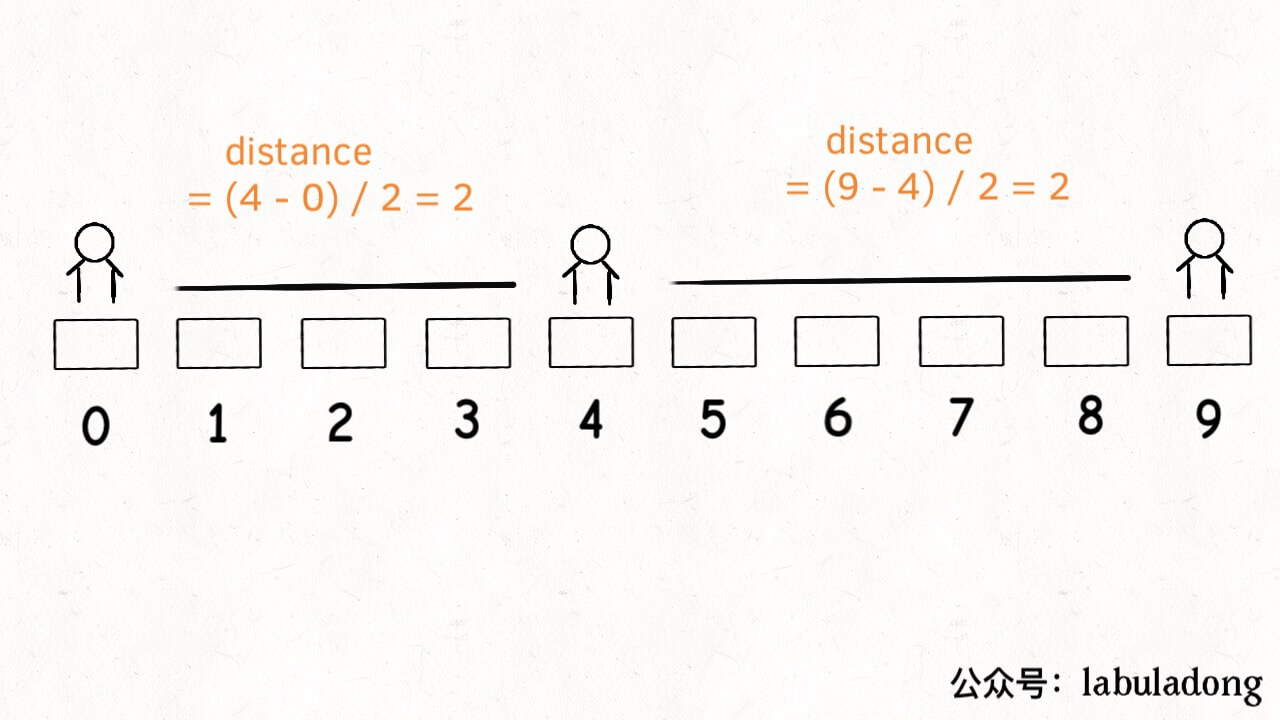
privateintdistance(int[] intv){ int x = intv[0]; int y = intv[1]; if (x == -1) return y; if (y == N) return N - 1 - x; // 中点和端点之间的长度 return (y - x) / 2; }
intcountPrimes(int n){ int count = 0; for (int i = 2; i < n; i++) if (isPrim(i)) count++; return count; } // 判断整数 n 是否是素数 booleanisPrime(int n){ for (int i = 2; i < n; i++) if (n % i == 0) // 有其他整除因子 returnfalse; returntrue; }
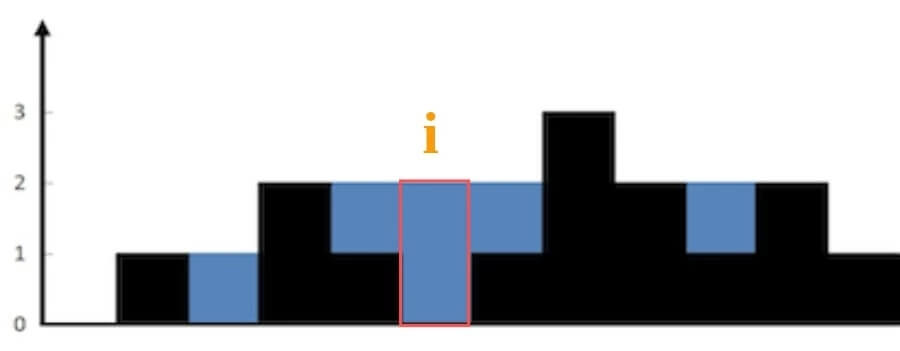
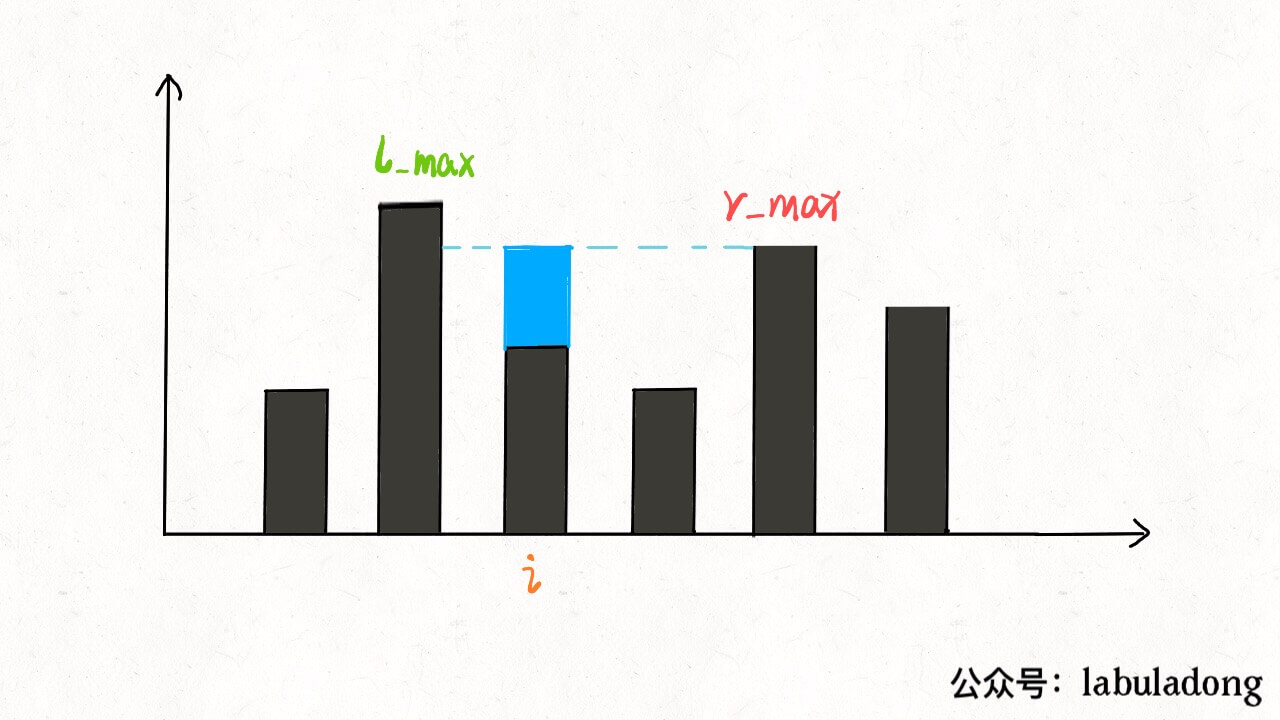
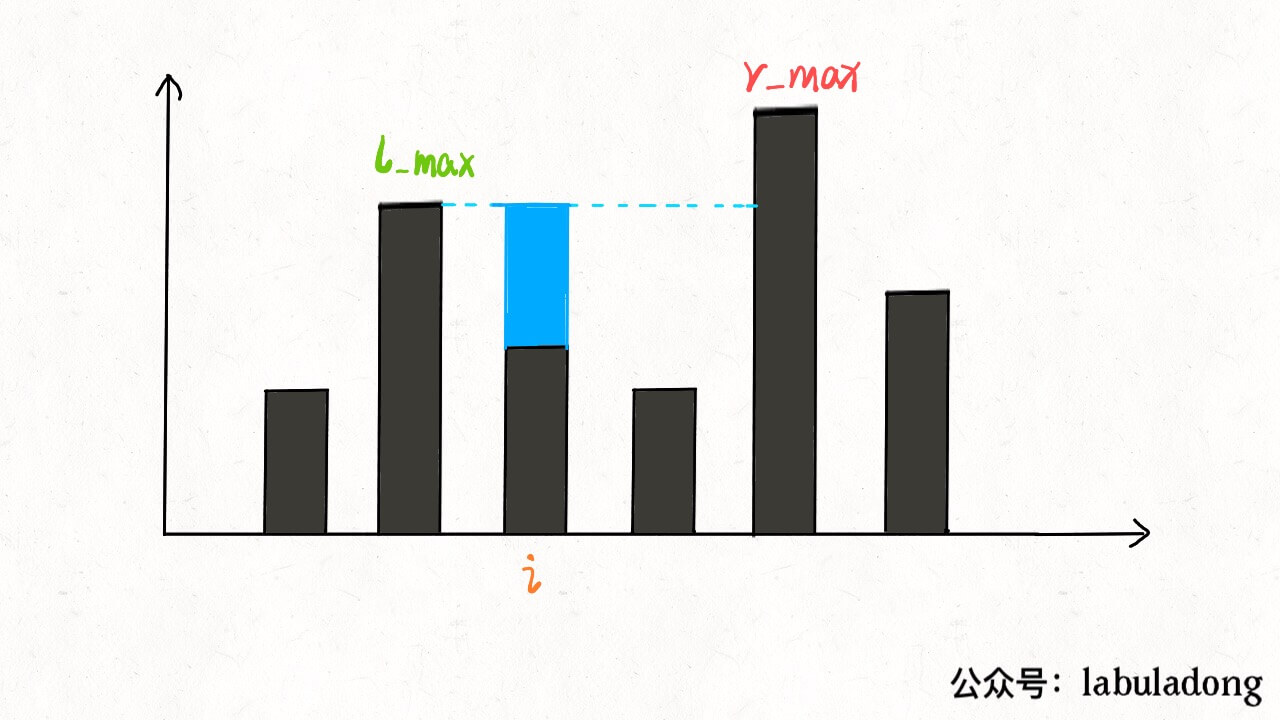
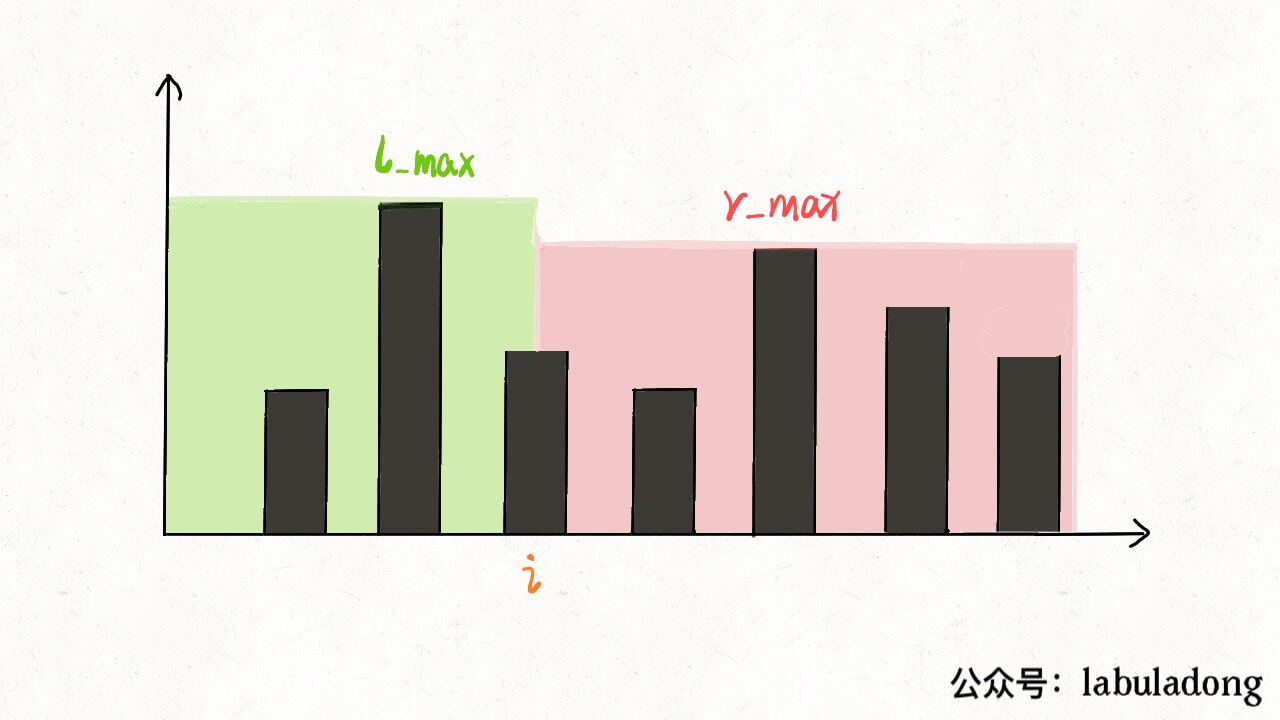
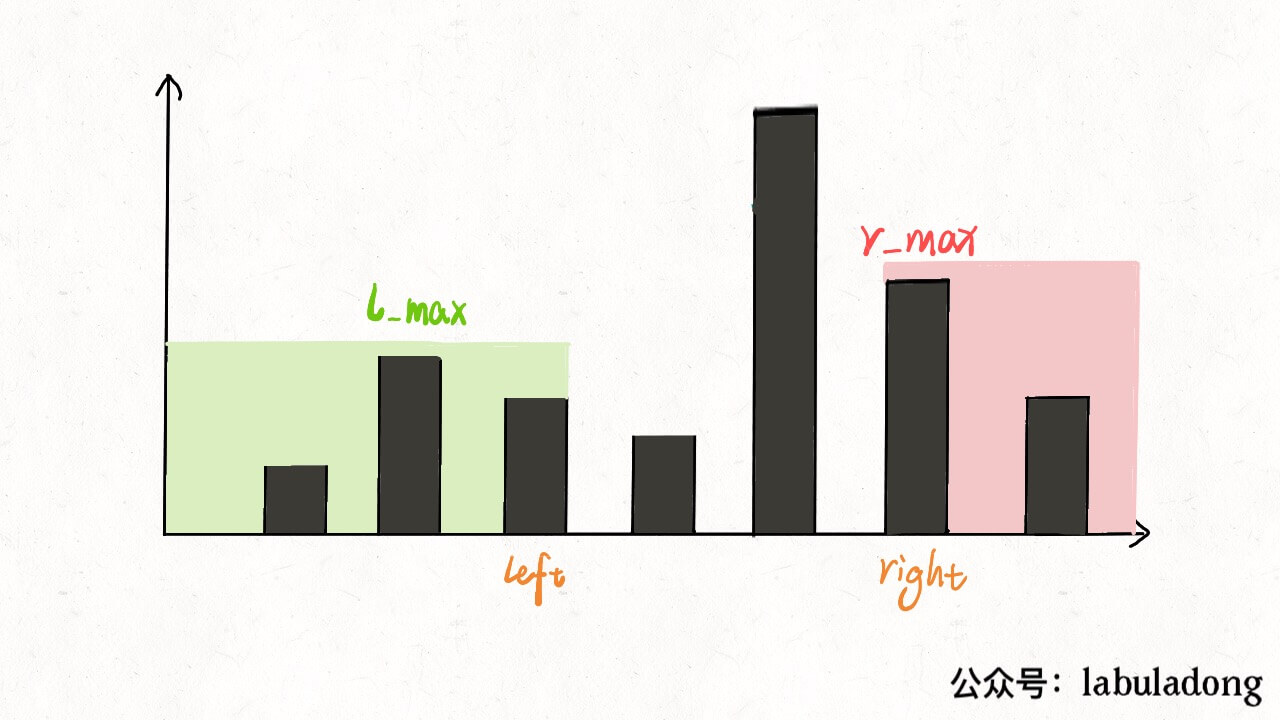
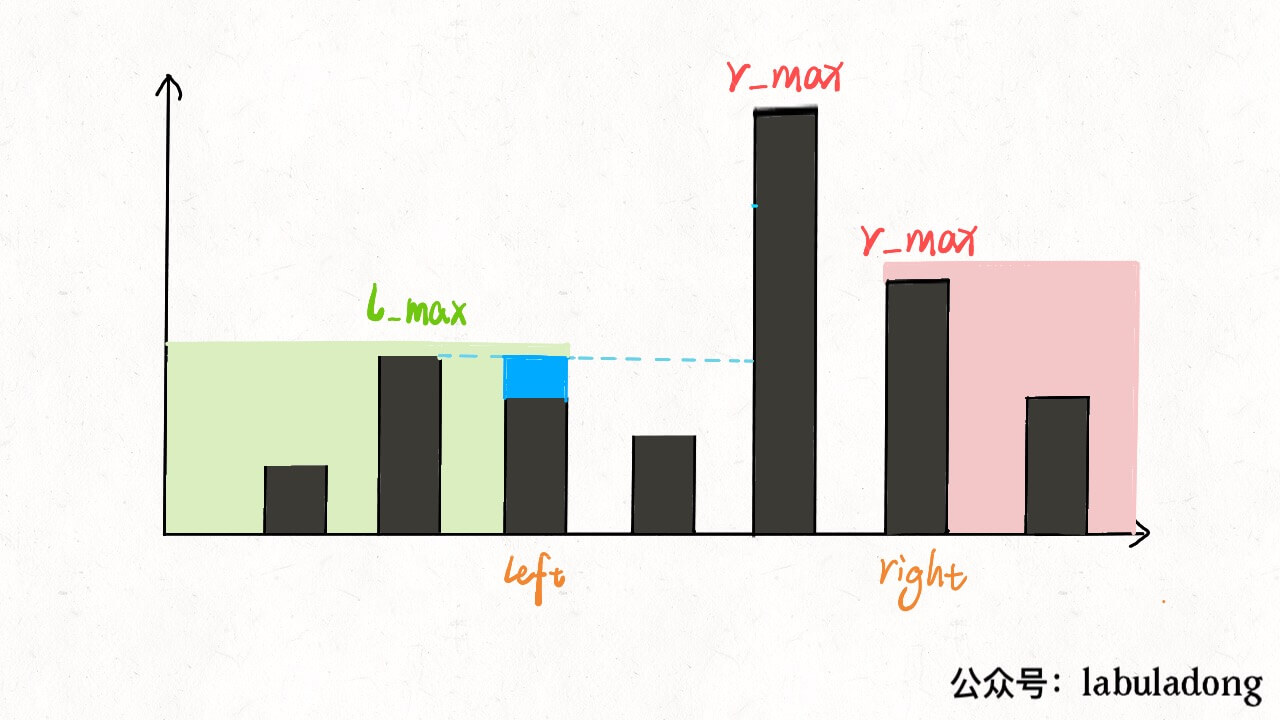
inttrap(vector<int>& height){ if (height.empty()) return0; int n = height.size(); int ans = 0; // 数组充当备忘录 vector<int> l_max(n), r_max(n); // 初始化 base case l_max[0] = height[0]; r_max[n - 1] = height[n - 1]; // 从左向右计算 l_max for (int i = 1; i < n; i++) l_max[i] = max(height[i], l_max[i - 1]); // 从右向左计算 r_max for (int i = n - 2; i >= 0; i--) r_max[i] = max(height[i], r_max[i + 1]); // 计算答案 for (int i = 1; i < n - 1; i++) ans += min(l_max[i], r_max[i]) - height[i]; return ans; }
我最近在 LeetCode 上做到两道非常有意思的题目,382 和 398 题,关于水塘抽样算法(Reservoir Sampling),本质上是一种随机概率算法,解法应该说会者不难,难者不会。 我第一次见到这个算法问题是谷歌的一道算法题:给你一个未知长度的链表,请你设计一个算法,只能遍历一次,随机地返回链表中的一个节点。 这里说的随机是均匀随机(uniform random),也就是说,如果有 n 个元素,每个元素被选中的概率都是 1/n,不可以有统计意义上的偏差。 一般的想法就是,我先遍历一遍链表,得到链表的总长度 n,再生成一个 [1,n] 之间的随机数为索引,然后找到索引对应的节点,不就是一个随机的节点了吗? 但题目说了,只能遍历一次,意味着这种思路不可行。题目还可以再泛化,给一个未知长度的序列,如何在其中随机地选择 k 个元素?想要解决这个问题,就需要著名的水塘抽样算法了。
算法实现
先解决只抽取一个元素的问题,这个问题的难点在于,随机选择是「动态」的,比如说你现在你有 5 个元素,你已经随机选取了其中的某个元素 a 作为结果,但是现在再给你一个新元素 b,你应该留着 a 还是将 b 作为结果呢,以什么逻辑选择 a 和 b 呢,怎么证明你的选择方法在概率上是公平的呢? 先说结论,当你遇到第 i 个元素时,应该有 1/i 的概率选择该元素,1 - 1/i 的概率保持原有的选择。看代码容易理解这个思路:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
/* 返回链表中一个随机节点的值 */ intgetRandom(ListNode head){ Random r = new Random(); int i = 0, res = 0; ListNode p = head; // while 循环遍历链表 while (p != null) { // 生成一个 [0, i) 之间的整数 // 这个整数等于 0 的概率就是 1/i if (r.nextInt(++i) == 0) { res = p.val; } p = p.next; } return res; }
/* 返回链表中 k 个随机节点的值 */ int[] getRandom(ListNode head, int k) { Random r = new Random(); int[] res = newint[k]; ListNode p = head; // 前 k 个元素先默认选上 for (int j = 0; j < k && p != null; j++) { res[j] = p.val; p = p.next; } int i = k; // while 循环遍历链表 while (p != null) { // 生成一个 [0, i) 之间的整数 int j = r.nextInt(++i); // 这个整数小于 k 的概率就是 k/i if (j < k) { res[j] = p.val; } p = p.next; } return res; }
intmissingNumber(int[] nums){ int n = nums.length; int res = 0; // 先和新补的索引异或一下 res ^= n; // 和其他的元素、索引做异或 for (int i = 0; i < n; i++) res ^= i ^ nums[i]; return res; }
publicintmissingNumber(int[] nums){ int n = nums.length; int res = 0; // 新补的索引 res += n - 0; // 剩下索引和元素的差加起来 for (int i = 0; i < n; i++) res += i - nums[i]; return res; }
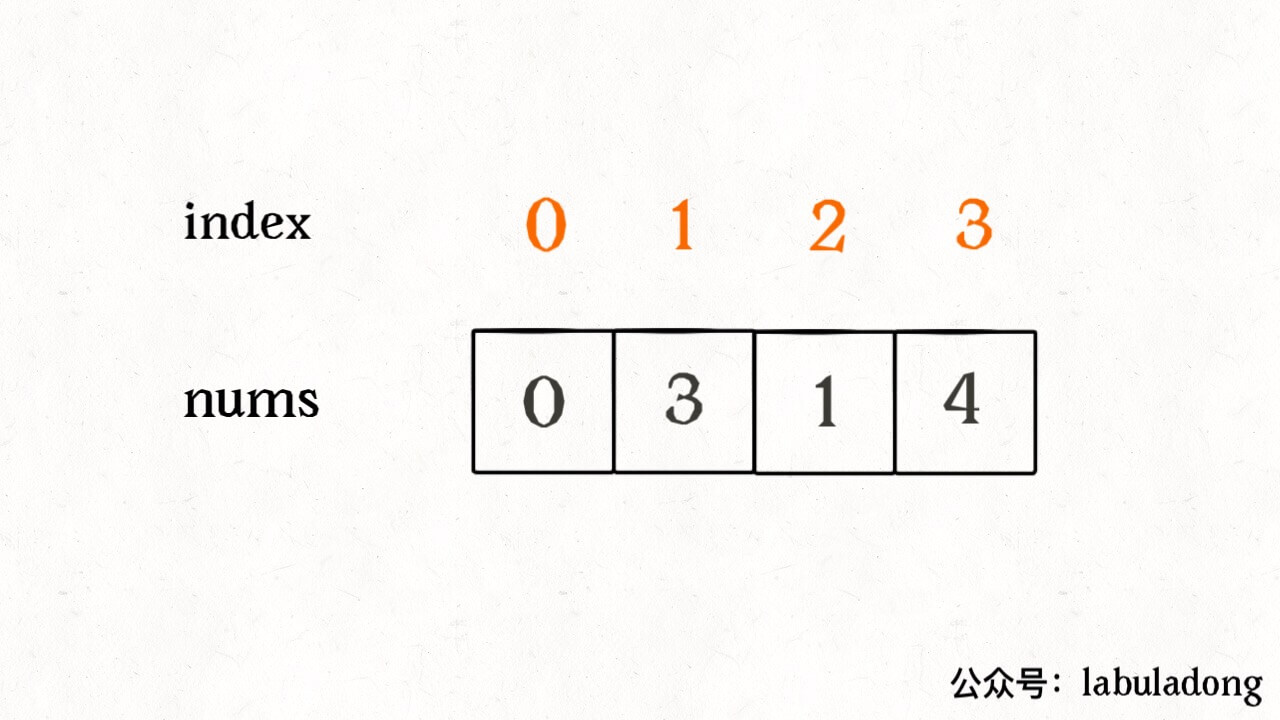
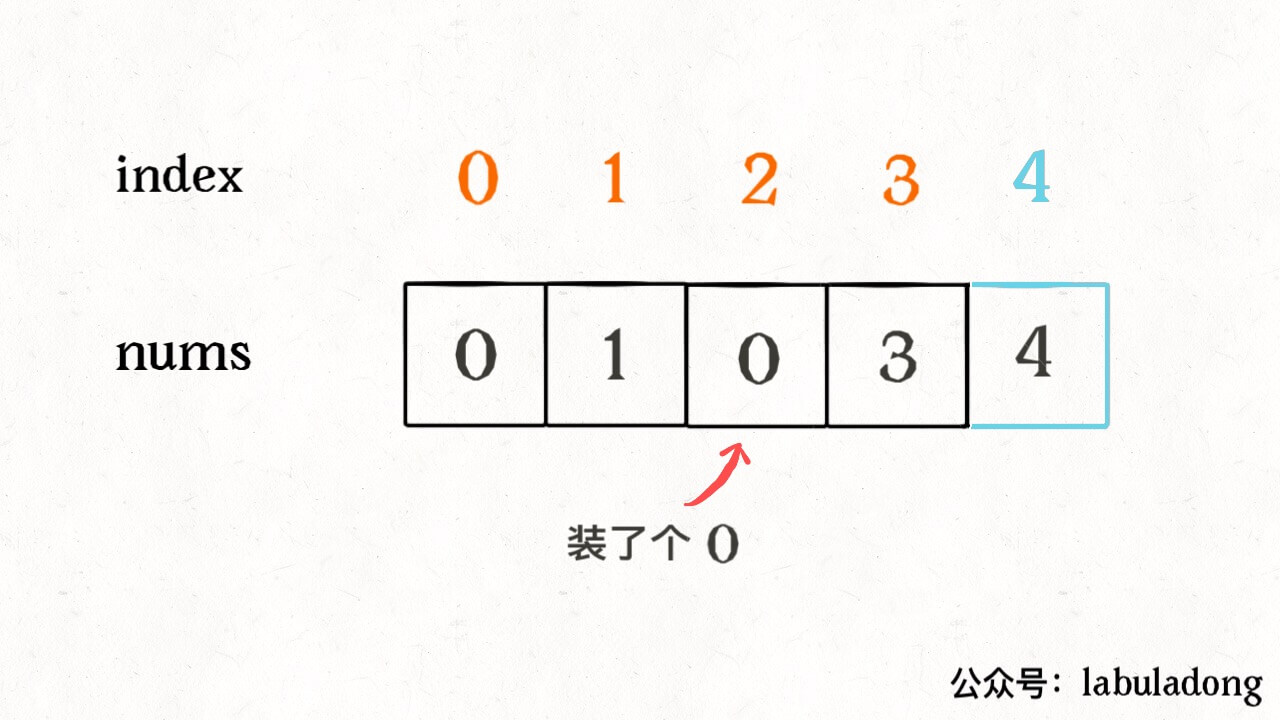
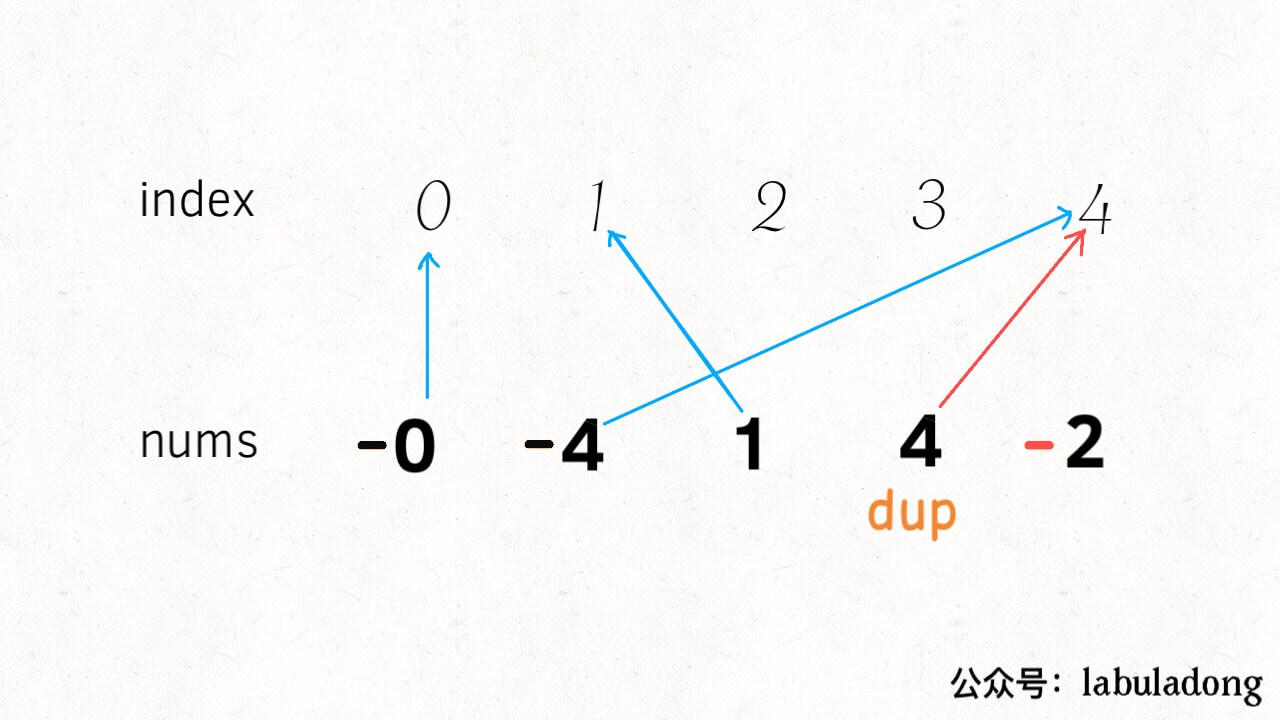
vector<int> findErrorNums(vector<int>& nums){ int n = nums.size(); int dup = -1; for (int i = 0; i < n; i++) { int index = abs(nums[i]); // nums[index] 小于 0 则说明重复访问 if (nums[index] < 0) dup = abs(nums[i]); else nums[index] *= -1; } int missing = -1; for (int i = 0; i < n; i++) // nums[i] 大于 0 则说明没有访问 if (nums[i] > 0) missing = i;
vector<int> findErrorNums(vector<int>& nums){ int n = nums.size(); int dup = -1; for (int i = 0; i < n; i++) { // 现在的元素是从 1 开始的 int index = abs(nums[i]) - 1; if (nums[index] < 0) dup = abs(nums[i]); else nums[index] *= -1; } int missing = -1; for (int i = 0; i < n; i++) if (nums[i] > 0) // 将索引转换成元素 missing = i + 1;
对于这种数组问题,关键点在于元素和索引是成对儿出现的,常用的方法是排序、异或、映射。 映射的思路就是我们刚才的分析,将每个索引和元素映射起来,通过正负号记录某个元素是否被映射。 排序的方法也很好理解,对于这个问题,可以想象如果元素都被从小到大排序,如果发现索引对应的元素如果不相符,就可以找到重复和缺失的元素。 异或运算也是常用的,因为异或性质 a ^ a = 0, a ^ 0 = a,如果将索引和元素同时异或,就可以消除成对儿的索引和元素,留下的就是重复或者缺失的元素。可以看看前文「寻找缺失元素」,介绍过这种方法。