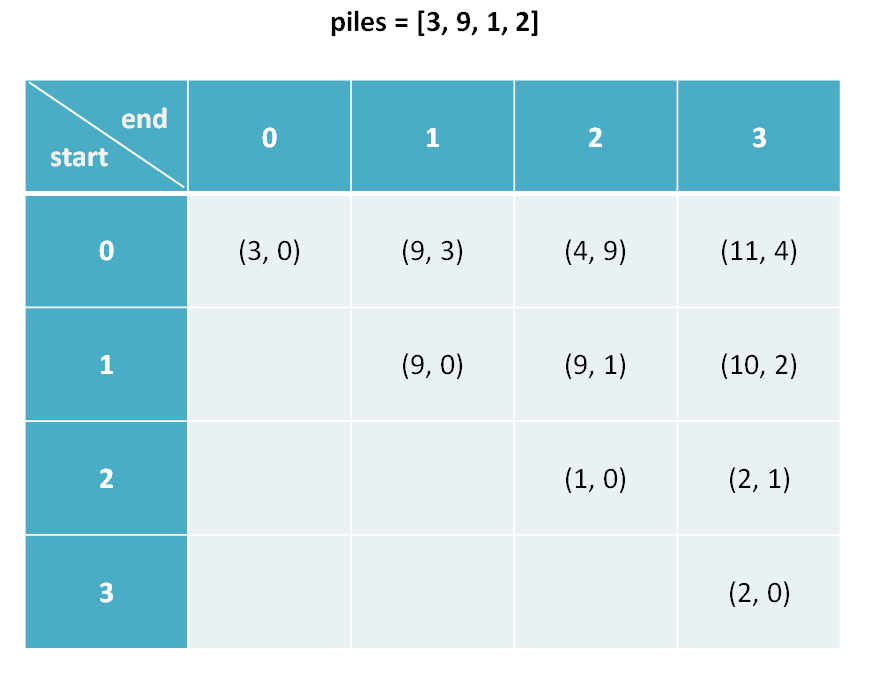
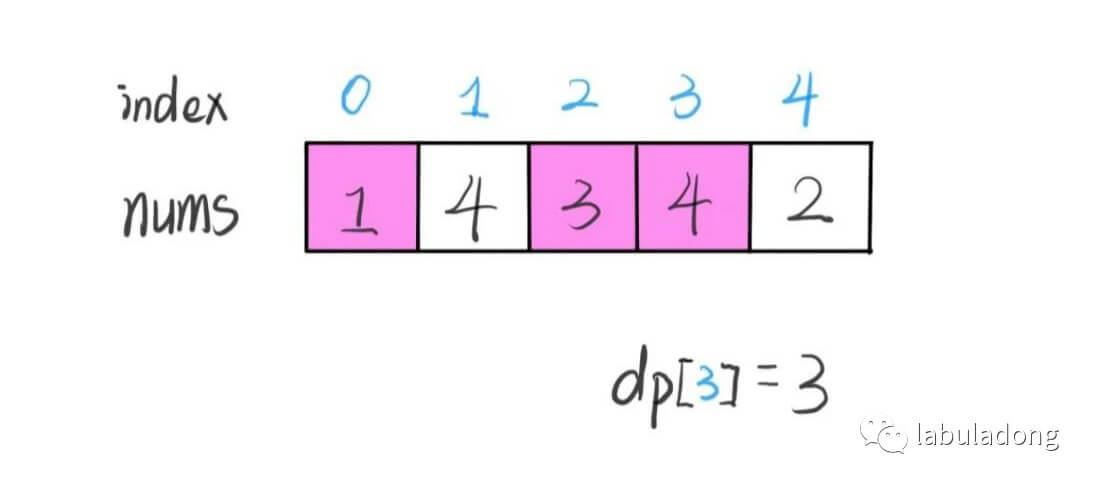
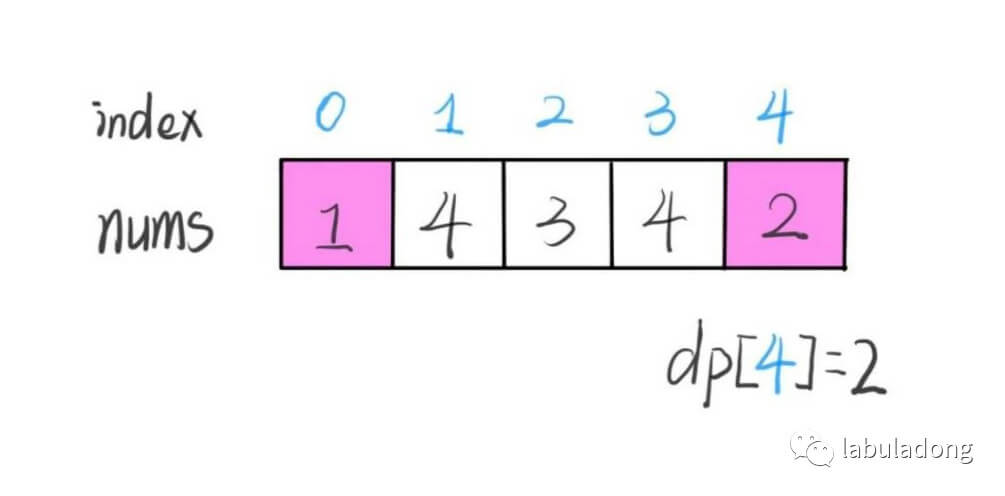
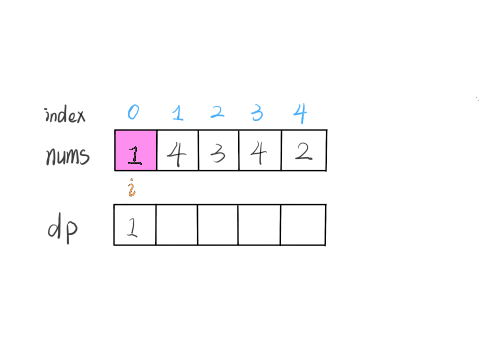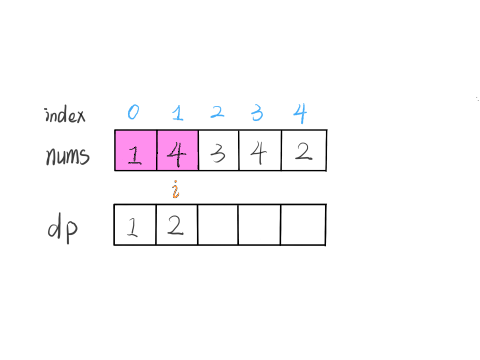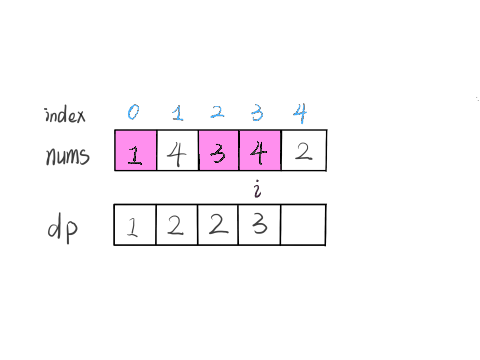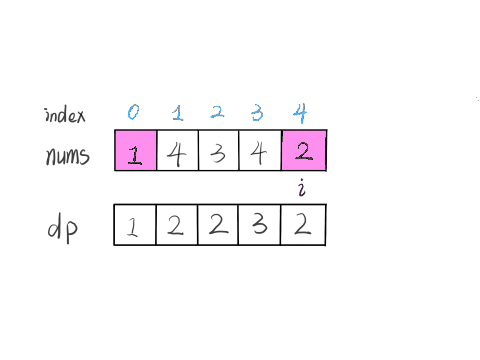
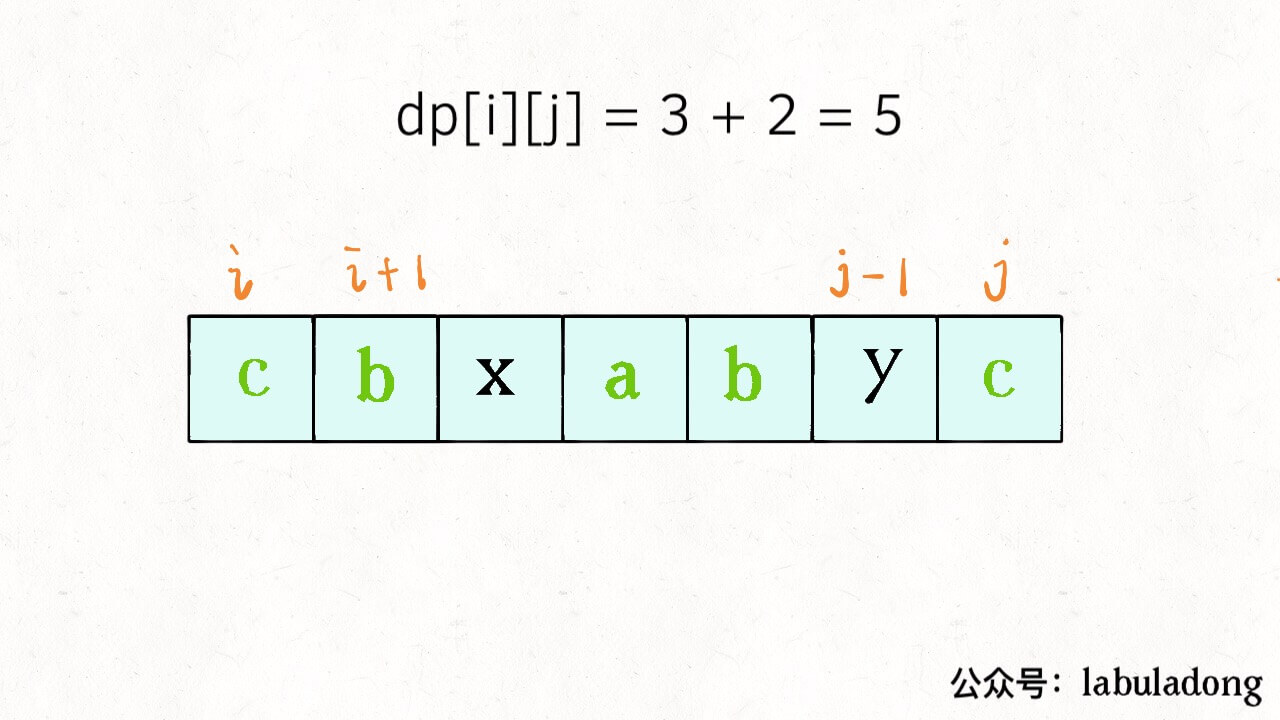
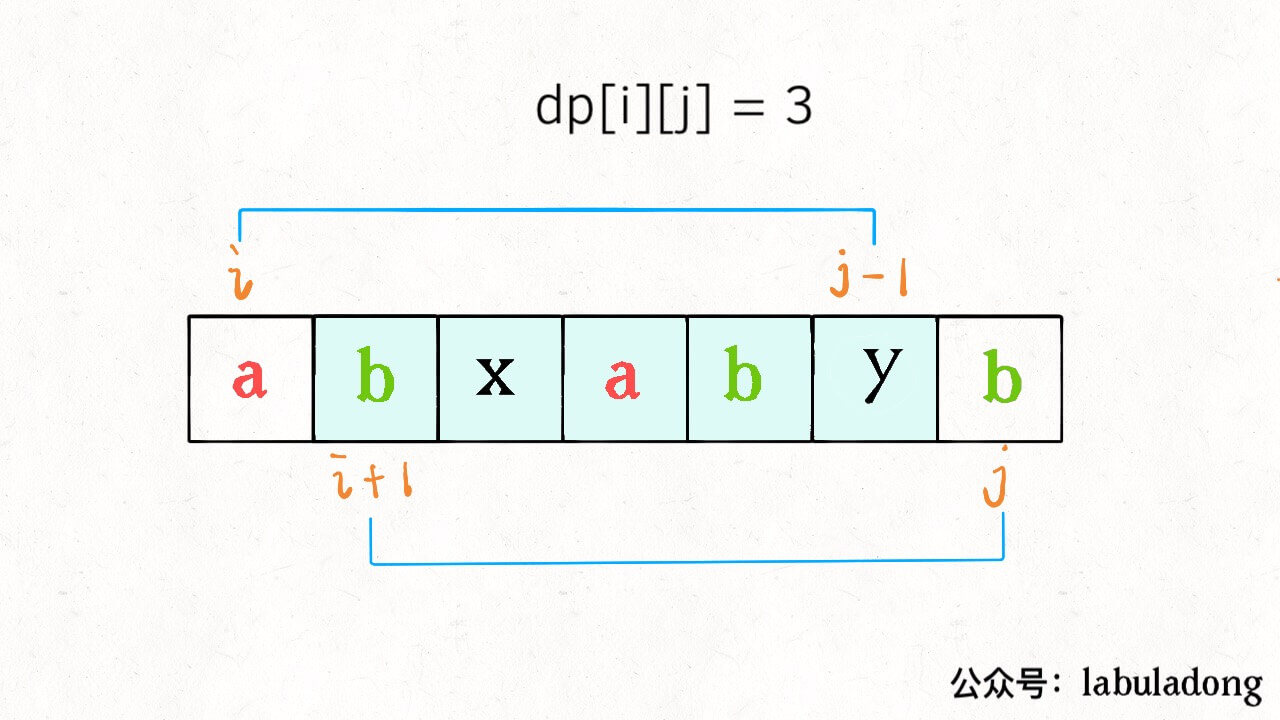
22Al的β衰变谱
摘要
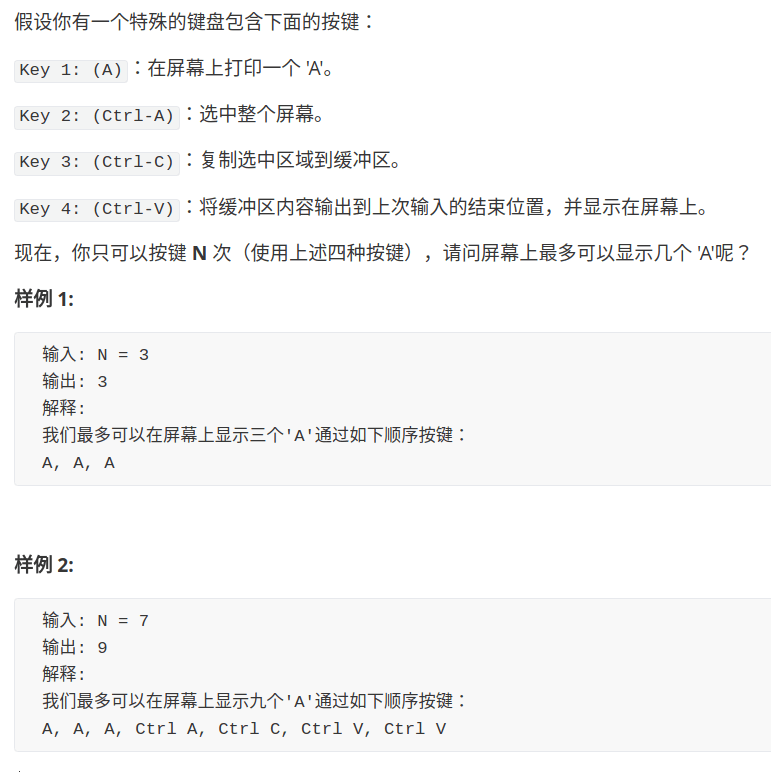
我们在兰州RIBLL1上开展了一个Al22衰变实验,主束为28Si. 半衰期91ms被测定。βp,β2p,βα,βγ的测定使得我们得以更新能级纲图。通过Geant4的模拟,我们进一步精确测定分支比,并对部分质子峰结构特征得以解释。
介绍
在过去几十年里,原理稳定线的奇异核一直是核物理领域经久不衰的研究热点。原子核的诸多性质诸如同位旋、能级宽度等一系列物理量随着原子核向远离稳定线延申,产生了诸多奇异的效应。通过这些特性有助于我们深入研究原子核的结构信息和衰变机制。而在其中,通过β衰变谱来开展研究工作成为了滴线附近原子核结构信息和检验并完善壳模型理论的强有力的工具。
奇异核22Al是Al同位素中最缺中子的一个核素,有13个质子,9个中子,Tz为-2,结合能只有20keV. 1982年第一次被Cable观测到。在他的实验中,22Al通过24Mg(3He,p4n)的反应生成(110MeV)。Al原子通过He-jet技术被输运。在衰变谱中,仅仅高能区的两个峰(8212,8537keV)能够被观测到,低能区的部分由于其他核的污染,无法进行观测。 这两个峰被指认为从IAS态到Na21的基态和激发态。IAS态的激发能为13650keV。测定的半衰期为70ms。 由于实验条件的限制,没有确定绝对的分支比。随后,Cable在另一个实验中观测到了β2p衰变事件。在那个实验中,他观测到了两条beta2p衰变分支。基于能量的考虑,这两条分支归到Na20的基态和第一激发态。在最近的实验中,Blank测到了betaalpha衰变,通过将Al22注入到鬼探测器和气体探测器。测得的T1/2为59ms。精确的能级纲图以及实验分支比被测得。然而这个实验也受到了污染,在Ar36生成的次级束中,仅有30%的是Al22核素。那篇文章中还进行了壳模型计算。
尽管Al22这个核已经被研究了很久,但依旧有一些不确定和局限。 由于较强的污染,部分月前丢失或者被污染物中更强的分支掩盖。此外,先前的实验中也没有观测到γ射线。实验的目的是提高beta衰变的测量,通过不同的方式:更纯的22Al次级束,更高的统计,带电粒子测量更好的能量分辨,gamma探测器来辅助指认跃迁。
实验技术
实验于2017年11月在兰州RIBLL1上开展。主束为74.27MeV/u,80enA的28Si14+,通过K69 Sector Focus Cyclotron和K450 Separate Sector Cyclotron 。次级束通过将28Si打到1581um厚的Be9靶上。RIBLL1的主要设置为筛选Al22做了优化。Al22的束流强度和纯度分别为()和()。次级束粒子通过ΔE和TOF来筛选想要的粒子。通过位于T1、T2的闪烁薄膜探测器给出的飞行时间(TOF)结合位于T2的QSDΔE1和QSDΔE2给出的能损信号(ΔE)可以建立ΔE–TOF图谱鉴别束流粒子,双重ΔE探测器的能量和时间信号都可以用于进一步提高对束流重离子的鉴别能力。本实验研究的核为Na20,Mg21,Al22,Si23.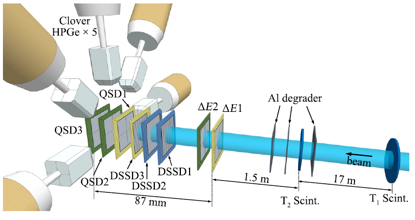
探测器阵列主要由三块双面硅条探测器(DSSD)、五块四分硅探测器(QSD)及外部五个Clover型的高纯锗探测器组成。经过上游铝降能片降能后的束流具有一定能散,目标核的射程分布在三块DSSD,即DSSD做停阻束流中目标核的注入探测器,并对注入核的衰变带电粒子进行测量,硅探测器对从内部发射的带电粒子具有极高的探测效率。每个DSSD x–y像素格都可视为独立探测器,这样在连续束、高束流注入率的条件下各单个像素格内仍能保持较低注入率,衰变事件和注入事件的时间关联仍然可以建立。三块DSSD的厚度分别为142um,40um,304um。Al22主要分布在后两块Si,QSD1用于探测DSSD中感兴趣核衰变产生的β粒子,QSD2和QSD3位于束流最下游,用于测量束流中的轻粒子(1H、2H、3H、4He等),反符合去掉穿透DSSD的轻粒子在DSSD中的能损信号。DSSD被五个clover环绕,下侧有三个LaBr3探测器,用来测量γ射线。
分析及结果
能量刻度及注入深度分布
重离子能量刻度通过将实验中任意两块DSSD组成的望远镜谱与LISE计算的望远镜谱做对照,调整刻度参数,使实验谱的中心与计算的de-E线基本重合;随后通过应用LISE计算得到的能量射程拟合函数计算注入重离子的注入深度。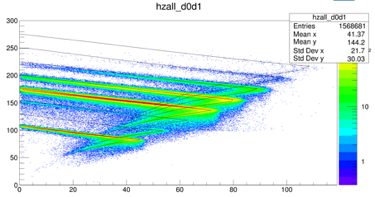
质子能量刻度应用文献中给出的质子峰数据。采用了※,※,※,※,※几个峰参与能量刻度。(考虑了弹道亏损效应。)和(β叠加效应)。
质子探测效率模拟
我们采用了Geant4工具包来模拟计算质子探测效率。质子的注入深度以及x-y平面分布采用了实验数据,在Si内各向同性发射。我们每隔0.5MeV的能量发射100000个质子,绘制了E-Eff曲线。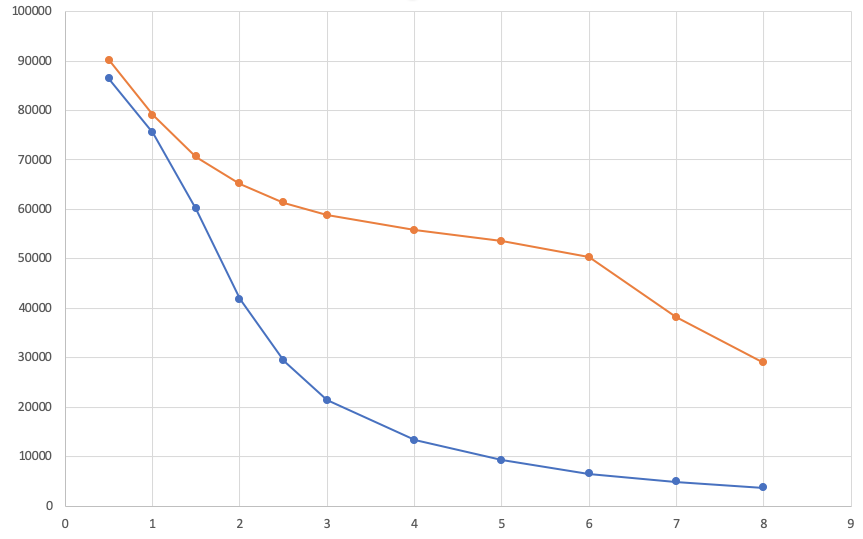
其中蓝线为40umSi的探测效率曲线,橙线为304umSi的探测效率曲线。
质子谱

这是最后一块Si的质子谱,其中蓝线未加入veto条件限制,而红线加入了veto条件限制。
这是中间一块Si的质子谱。
Geant4模拟质子谱
随后,我们应用EPJA2006文章中给出的质子能量分支比数据作为Geant4模拟输入,来研究β叠加效应。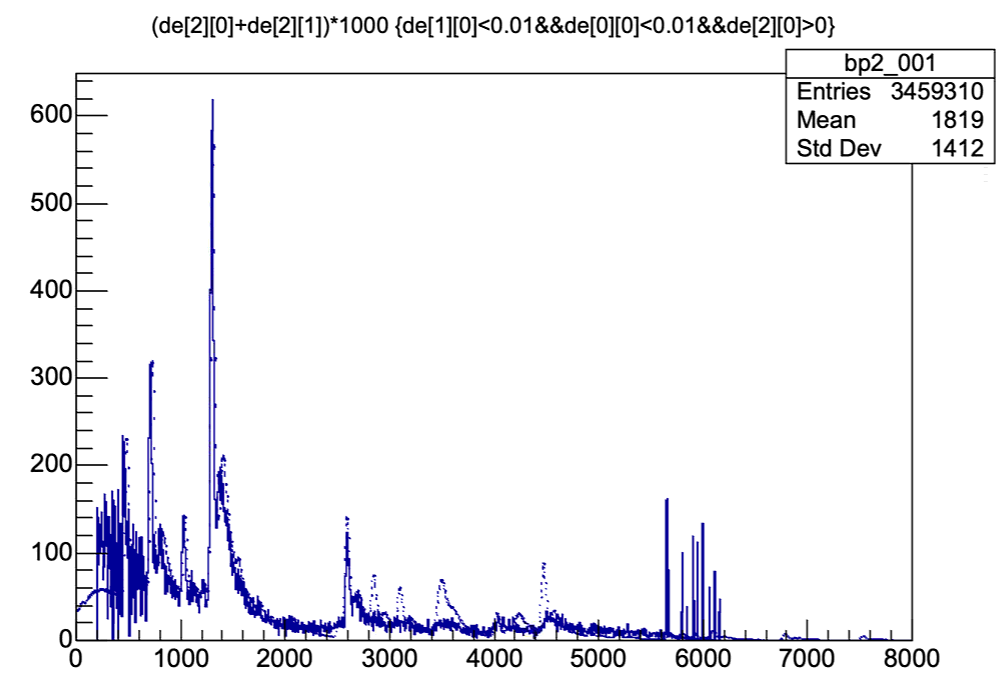
上图中实线为实验谱,虚线为经过归一之后的模拟谱。其中实验谱和模拟谱均未设置veto条件。